
day40 mycql 视图,触发器,存储过程,函数
视图,触发器,存储过程,自定义函数


-- 回顾 1.mysql 约束 1、非空 not null 2. 主键约束 primary key 3. 唯一约束 unique 4. 外键约束 foreign key 5. 默认值约束 default 2. 数据库的设计 1.好处: 1.有效的存储数据 2.满足用户的多种需求 2.数据库设计三范式: 1.确保每列都保持原子性 2.确保每列都与主键相关 3.确保每列都与主键直接相关,而非间接相关。 3.数据库表关系、 1. 1-1 特殊的一对多,通过在字段上添加唯一约束产生一对一关系 2. 1-n 主表不动。从表中添加主表的主键 3. n-n 两张主表结构不变,然后利用第三张表表示两张主表的关系 id name 。。。 id name 。。。 1 华联 1 老王 2 加利福 2 小王 超市顾客关系表 id c_id u_id 1 1 1 2 2 1 -- 今日内容 视图 概念:其实就是一个临时表 1.创建视图 create view 视图名称 as sql查询语句; 2.使用视图 select * from 视图名称 where 条件 3.改变视图 alter view ren_wei as sql查询语句; 4.删除视图 drop view ren_view; 触发器 1.创建触发器 create trigger t2 AFTER INSERT on order_table for each row -- 固定写法 BEGIN -- sql update goods set num = num -2 where id = 1; end 动态获取参数 create trigger t2 AFTER INSERT on order_table for each row BEGIN -- sql update goods set num = num- new.much where id = new.gid; end 注意: new 表示获得插入的参数 2.删除触发器 drop trigger 触发器; 存储过程 1.创建存储过程(体会封装) create PROCEDURE p1() BEGIN select * from ren; select * from goods; end 2.创建存储过程(体会参数) create PROCEDURE p2(in num int) BEGIN select * from ren where p_sal > num; end 3.创建存储过程(体会控制) create PROCEDURE p3(in num int,in flag char(1)) BEGIN if flag = '1' THEN select * from ren where p_sal >num; elseif flag ='2' THEN select * from ren where p_sal =num; else select * from ren where p_sal < num; end if; END 4.创建存储过程(体会循环) create PROCEDURE p4(inout num int) BEGIN DECLARE i int DEFAULT 1; -- 声明变量 DECLARE he int DEFAULT 0; while i<= num DO -- 表示开始循环 set he = he +i; set i = i+1; end while; -- select he; -- 显示结果 set num = he; end 5.删除存储过程 drop PROCEDURE 名称; 6.调用存储过程 call 名称(参数值) 7.显示当前库下的所用存储过程 show PROCEDURE status; 作业:http://www.cnblogs.com/wangfengming/p/7891939.html 要求完成(10-15个sql查询) 谈论表设计
一些概念补充:
视图:
视图就是一个虚拟表(并非真实存在),其本质是根据sql语句获取动态的数据集,为其命名,用户使用时只需要使用名称即可获取结果集,可以将该结果集当做表来使用.它是用来存储查询结果集的,就是我们的一句查询sql存入到视图中,然后再查询该结果的时候就从视图中就能查到,比如我们把一些嵌套的子查询存入到视图中,再查该数据的时候就从视图中查即可.
insert into tw_view values(201,'alex','egon','2017-10-01 12:00:30','风平浪静','','')
-- 这里需要备注一下,我们在使用视图的时候要把你copy的表格完整的copy过来,不能有遗漏(字段),否则在进行修改的时候会报错,
alter view tr_view as select name from tr -- 这里alter是关键字改变字段结构,view是固定用法,然后后面就是加上需要更改的表格的名字再后面就是as关键字,然后是sql语句,这个sql语句查询得到的结果放到前半句里面,就是根据tr_view这个表格把其他的字段都删除掉,只保留sql语句得到结果的字段.
-- drop view tr_view 删除视图表格
-- 视图的存在就是为了增加权限,同样一个表格,每个人的级别不一样,看到的内容也不一样,对于有些内容是需要进行隐藏,但是隐藏之后又不能够影响用户的使用,这里的约束就类似于装饰器,我们需要增加功能之后同时也不可以改变用户的使用方法,
-- 基于这个需求我们就开始创建了视图,视图就相当于一个临时表格,是主表格的映射,对他进行修改增加内容都会影响到主表格,但是如果对试图表格进行删除的话,那么主表格是不会受其影响的,这里就是主副之别.
{要补充的一点是我们的数据库设计出来不单单是我们自己使用,还会牵涉到很多其他人使用,为了大家的使用都更加便捷,我们要尽可能少用到视图操作,把表格设计得更加合理化}
视图示例
create view actor_view as select id,name from actors ; -- 创建视图 select * from actor_view; -- 直接从我们所创建的视图中查询数据查所有数据 select name from actor_view; -- 查单单列字段数据 drop view actor_view; -- 删除视图 alter view actor_view as select name from actors ; -- 修改视图 select * from actor_view; -- 这里是查询我们修改过的视图里面的数据
视图示例二
create view student_View as select student.id,student.sname,student.gender, student.class_id,class.cname from student left join class on student.class_id=class.id; 这里可以进行update操作 update student_View set sname='shera' where id=2;
但是insert会报错 insert into student_View (id,sname,gender,class_id,cname) values (5,'paul',1,1,'php');
报错信息如下:
[Err] 1471 - The target table student_View of the INSERT is not insertable-into
触发器:
create trigger e before delete on order_table for each ROW
begin
update goods set num=num+old.much where id=old.gid;
END;
我们这里的应用场景是在购物过程中,买方购买商品后购物车里增加内容,然后卖方的仓库里面会减少内容,为了实现这个需求我们使用了触发器的功能,
这里解释一下,第一句create是创建一个触发器,使用delete方法是要用到before选项归属于delete方法,
on是固定搭配,不用delete方法还可以使用update方法,查询是不支持的,查询没有触发器可以用,on后面接的是需要使用到delete方法的该表格的名字,
然后就是固定搭配,begin.........end,中间加上sql逻辑语句,update是更改表格的内容,所要更改的表格是仓库里的库存的表格紧跟着就是固定搭配用法,for each ROW,
该库存商品的数量随着
卖出的数量不断的递减,所以我们需要拿到库存商品数量的对应的字段,然后在此基础上进行加减操作,这里因为使用的是delete方法,所以是消费者退货的
时候我们的库存数量逐渐递增,所以这里使用的是加法,然后后面的where是条件设定,要删除那一条数据根据这个where后面的内容来决定,
触发器示例
-- CREATE TRIGGER tri_before_insert_act AFTER INSERT ON actors for EACH ROW -- BEGIN -- IF new.name = 'alex' THEN INSERT INTO USER (name) VALUES ('judy'); # 数据库中的=是一个 -- end if; # 在触发器中if和endif是对应的,需要加;号 -- END; -- insert into actors (name) VALUE('alex'); # 如果插入的值name=alex,那么我们的user表中就插入一条数据,name是judy. -- create TRIGGER tri_after_drop after DELETE on actors for EACH ROW -- BEGIN -- DELETE FROM USER where name=old.name; -- END; -- DELETE from actors where name='alex'; # 当我们从actors表中删除一条数据的时候,被删除的名字如果跟user表中的名字一样,那么就把user表中的名字也删除掉 CREATE TRIGGER tri_befor_upd BEFORE UPDATE on actors for EACH ROW BEGIN UPDATE USER set name=new.name where id=old.id; END; -- 这里的触发器作用就是我们要在actors表的update操作前增加一条指令, -- 当我们的actors里面的id和user表中的id值相等的时候,我们的update表中name值就被改为我们的actors里面的更新后的值 UPDATE actors set name='jane' where id=2;
当用户修改一个订单的数量时,我们触发器修改怎么写?
create trigger f after update on order_table
for each ROW
BEGIN
update goods set num=num+old .much-new.much where id=new.gid;
END
-- 这里是update,这个update的意思是我们在购物车原有商品数量的基础上对该数量进行操作,
例如原来的数量是10,我们把它改成了15或者改成了10,这是update操作可以实现的,这才是重点,
而不是insert和delete!!!所以这里的old是原来的数据的样子,而new是改过之后的数据的样子,
所以我们在这里需要让商品库里加上原来的数据,然后再减掉我们更改过后的数据,这样就可以实现
需求------用户不论怎么改变商品数量,都可以保证商品库里面的数量的准确性.
存储过程:
存储过程包含了一系列可执行的sql语句,存储过程存放于MySQL中,通过调用它的名字可以执行其内部的一堆sql
(在innodb存储引擎中,如果你的字段里面没有指定主键,它系统会自动在内部找一个不为空只唯一的字段来作为主键,如果有好几个不为空且唯一的字段,那么系统就会从上往下依次寻找,遇到一个满足条件的,就选定它作为主键,如果所有的字段都不满足条件,系统会自动生造一个主键出来,由于主键是有非凡意义的存在,有主键使用索引查数据的时候会快很多倍,所以主键一定要自己设定好.必须要有)
frm是innodb存储引擎的表结构form
ibd是innodb存储引擎的表数据-data(innodb是必须要有主键的,它按照主键聚集)
frm是myisam存储引擎的表结构form
myd是myisam存储引擎的data文件data
myi是myisam存储引擎的索引文件index
frm是blackhole存储引擎的表结构,里面是不会有任何数据的,凡是扔进去的数据都会消失,它是专门清空数据的
frm是memory存储引擎的表结构它的数据都是存放在内存里面
使用存储过程的优点:
#1. 用于替代程序写的SQL语句,实现程序与sql解耦 #2. 基于网络传输,传别名的数据量小,而直接传sql数据量大
使用存储过程的缺点:
#1. 程序员扩展功能不方便
create procedure p11(OUT num int) -- in 是入参,这里的参数需要数据类型来限制它,同理,out是出参,也需要数据类型来加以限制
BEGIN
DECLARE i int default 10; -- 这里是给上面的out定义一个默认值,因为这里是用的out,它只是出参,不接收传入的参数所以需要在这里
-- 给他在内部定义一个参数,
set num = i; -- 这里是把默认的参数赋值给上面的一开始定义的参数里面
END
set @n = 0; -- 这里我们设置一个变量,这个变量是用于接收上面的出参
call p11(@n); -- 这里不能直接用函数名加上空括号会报错,所以我们需要在里面加入一个变量来接收上面的出参,需要跟上面一步相关联,否则也会报错.
select @n; -- 这就类似于print,把结果打印出来
存储过程示例:
简单版:
create procedure actor_pro() -- 这里就是创建了存储过程,固定语法,要在存储过程的名字里加上() BEGIN select name from actors ; END; call actor_pro();
复杂版:
create PROCEDURE us_pro(
in id int,out name varchar(32), inout city varchar(30)
)
BEGIN
if (id>3) then set name='alex';set city='tibet';
end if;
if (id<3) then set name='wusir';set city = 'cingdao';
end if;
END;
set @name='peter'; # 这里是由上面我们的存储过程里面的参数类型决定的,只要是in类型的参数(输入参数)就在传参的时候,直接写入即可,如果是out(输出参数)/inout(输入输出参数)类型的参数就需要在这里使用set设置值,以=赋值的方式,然后把设置的值写入到我们的参数里面去.
set @city='peking';
CALL us_pro(4,@name,@city);
select @name as name,@city as city;
这个存储过程里面封装了一些逻辑判断,不是上面简单的sql语句了,我们在调用这个存储过程的时候,把相应的参数传进去[传参的时候,我们是用的位置参数,要对应上,不能随意调换位置],然后在里面就会执行逻辑判断,然后有返回结果,我们使用select语句就能得到返回值了.

in/out/inout三种参数类型以及declare跟set两种声明变量的方式区别
in/out/inout三种参数类型
create PROCEDURE demo_inout(inout p_inout int) BEGIN SELECT p_inout; -- 这里的p_inout参数在我们存储过程的形参里面的变量 set p_inout=22; -- 这样写在存储过程里面的变量就不需要加上@符号,直接赋值即可 select p_inout; END; set @p_inout=100; -- 写在存储过程外面就需要加上@符号进行赋值 call demo_inout(@p_inout); -- 这里第一次显示的是我们的存储过程外面设置的值,inout是输入输出参数,可以被修改,也可以传入. -- 第二次再执行就变成了我们的存储过程里面设置的值了, -- 下面的select获取结果集也是一样第一次执行结果是外面设置的set的结果,第二次是里面存储过程里面的值 SELECT @p_inout; create PROCEDURE demo_out(out p_inout int) BEGIN SELECT p_inout; set p_inout=22; select p_inout; END; set @p_inout=100; call demo_out(@p_inout); -- 这里是out参数类型,输出参数,不接收传入的值, SELECT @p_inout;-- 所以这里我们获取的都是存储过程里面的值 DROP PROCEDURE demo_in;
create PROCEDURE demo_in(in p_inout int) BEGIN SELECT p_inout; set p_inout=22; select p_inout; END; set @p_inout=10; call demo_in(@p_inout);-- 这里是in参数类型,输入参数,我们传入的是什么值就会在这里输出什么值,就执行这一句就可以得到结果 SELECT @p_inout;-- 这里就是我们在存储过程外面设置的值
declare跟set两种方式声明变量的区别
drop PROCEDURE demo_declare ; create PROCEDURE demo_declare() BEGIN declare s1 int default 0; -- 这里我们使用declare声明一个变量,declare只是声明一个变量,然后set是对它进行赋值操作, set s1=10;-- set在这里赋值的只能是declare所声明的变量,或者是我们的存储过程里面所接收的参数,它不能自己声明变量并赋值 set @s2=@s2+2;-- 这里我们的set使用@符号语法就可以一步操作在声明变量的同时对其进行并赋值, -- SELECT s1,@s2; -- 我们在存储过程里面使用select语法就类似于python里面的print操作,我们在调用该存储过程的时候就可以直接得到这一句的结果 END; set @s2=5; -- 而加上@符号的就是全局变量,就可以在存储过程外部进行修改操作 set s1=22; -- 这里的s1是我们的存储过程里面的变量,不能在外部进行修改,相当于是局部变量 call demo_declare(); SELECT @s2,s1;-- [Err] 1054 - Unknown column 's1' in 'field list' 这里在外部是无法调用到我们的s1变量的,它是存储过程里面的局部变量
带事物的存储过程示例
-- 带事物的存储过程 create PROCEDURE p1( out s8 TINYINT ) BEGIN -- 我们在这里创建事物,如果事物执行成功之后就会返回一个数值类似于状态码 DECLARE EXIT HANDLER for SQLEXCEPTION BEGIN -- ERRORS -- 如果执行结果状态是errors就直接返回我们这里的errors里面设置的s8=1 set s8=1; rollback; END; DECLARE EXIT HANDLER for sqlwarning BEGIN -- WARNINGS 如果执行结果是warnings就返回这里的s8=10的结果值 set s8=10; ROLLBACK; END; START TRANSACTION; -- 这里是开启事物的语法, DELETE from actors;-- 这里是把我们的表中所有数据清空 INSERT INTO USER (name,age,city) VALUES ('fred',39,'tibet'),('alvin',29,'hongkong'); -- 以上两个操作同时执行,要么同时提交,要么就是都回滚, commit; -- success 如果事物执行结果是success,就返回我们的s8=21的结果值 set s8=21; END; DROP PROCEDURE p1; set @p=20; -- 这里在存储过程外部设置一个全局变量,用于给我们的存储过程传参,这里我们的存储过程用的是out类型的参数, call p1(@p); -- 这里把参数传进去,因为是out类型的输出参数,所以即便传入进去也不会被接收, select @p; -- 所以这里我们打印的就是我们的存储过程里面的变量s8
存储过程中的游标用法
在检索出来的行中,前进或者后推一行或者多行,就需要用到所谓的"游标",游标不是某一个select语句,而死该语句检索出来的结果集,在mysql数据库中只能用于存储过程和函数
创建游标使用关键字,declare 和 cursor
游标是局限于存储过程,所以如果存储过程处理完成后,游标就消失了.在存储过程中要关键字open进行打开,于游标相关的select查询语句在定义时不执行,在open时才执行,存储检索出的数据以供浏览和滚动.游标使用完之后,close进行关闭.
使用游标数据,要用到关键字fetch访问数据,fetch从第一行开始,获取当前行的数据,每次执行后会移动内部行指针,再次调用fetch会检测到下一行,不会重复读取同一行数据.
create PROCEDURE ps() BEGIN DECLARE ssid int; DECLARE ssname varchar(20); DECLARE done int DEFAULT false;-- 这里相当于定义一个flag, DECLARE my_cursor CURSOR for select name from user; -- 这里是设置游标 DECLARE CONTINUE HANDLER for not found set done = TRUE;-- 当我们获取完数据之后,改变标志位的值 open my_cursor; xxoo:LOOP -- LOOP关键字,这里是类似于for循环遍历每一条数据 FETCH my_cursor into ssname; -- 把游标取到的值赋值给我们上面声明的变量里面 if done then leave xxoo;-- 如果标志位值被改变就退出循环 end if; insert into actors (name) VALUES(ssname);-- 把我们取到的值insert到另一张表格中 end LOOP xxoo;-- 退出循环的完整步骤 close my_cursor;-- 关闭游标 end; call ps;
自定义函数示例:
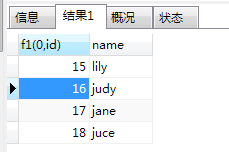
create function f1( q1 int,-- 这里是函数的参数 q2 int ) returns INT -- 返回的是我们的函数名加上参数 BEGIN declare num int; -- 函数体内声明变量 set num =q1+q2;-- 写逻辑代码 return (num);-- 具体的返回值,上面两个参数相加的结果值 END; SELECT f1(1,15);-- 函数的调用使用select关键字+函数名(函数所需要的参数) select f1(0,id),name from user; -- 在sql查询中使用我们的自定义函数
得到的结果如下图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号