
day38 mycql 初识概念,库(增删改查),表(增删改)以及表字段(增删改查),插入更新操作
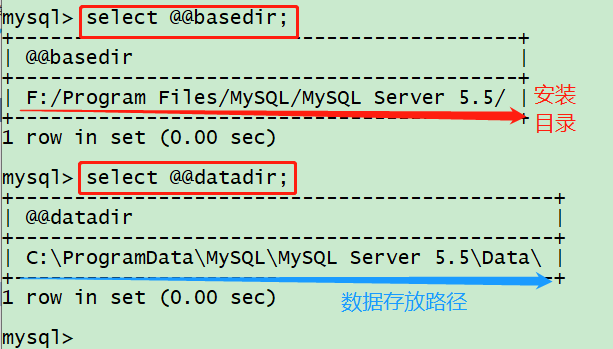
经常安装了MySQL,会忘记安装的路径,然后后期需要修改配置文件,很容易找不到地方。如下命令,可以在命令行找到路径:
在Navicat中把已经生成的表逆向成模型
数据库上,右键-逆向数据库到模型
ego笔记:
增删改查


文件夹(库) 增 create database day43 charset utf8; 改 alter database day43 charset gbk; 查 show databases; show create database day43; 删 drop database day43; 文件(表) use day43; select database(); 增 create table t1(id int,name char(16))engine=innodb charset=utf8; 改 alter table t1 add sex enum('male','female'); alter table t1 modify sex char(6); alter table t1 change sex Sex char(6); alter table t1 drop sex; alter table t1 rename t2; 查 desc day43.t1; #查看表结构 show create table t1; 删 drop table t1; 文件的一行内容(一条记录) 增 insert into t1(id,name) values (1,'egon'), (2,'alex'), (3,'wxx'); 改 update t1 set name='wpeiqisb' where id=3; 查 select id from t1; 删 delete from t1 where id=2; truncate t1; #拷贝表结构+记录 create table day43.user select host,user,password from mysql.user; #只拷贝表结构 create table day43.user select host,user,password from mysql.user where 1=2; 这里就是在后面附上了一个不成立的条件,然后表格里面的数据就都不会拷贝出来了,只是把表的结构拷贝出来而已, mysql -uroot -p123 -h10.0.0.10 -P 33306
这里是简单的概念性的东西,关于数据库的一些概念
数据库如果要使用的话,必须要先安装它,然后安装完之后还需要卸载它,这些初始步骤都是在老师的博客里面的, 我就不在这里一一总结了,我都会操作,而且已经操作过一遍了,都成功的达到了预期的效果.
这条连接是如何创建临时表.---所谓的临时表就是你把它创建出来了然后它存在于内存里面,内存的特性就是你关机后自清空,所以这里我们关掉了mycql之后它就会被系统自动清理掉.它的存在还是很有必要的.
http://blog.csdn.net/itegel84/article/details/5940445
老师的笔记:
2.问题:为什么要学习数据库 3.什么是数据库 用来存储数据的仓库 4.数据库的优势: 1.存储数据量大 2.方便管理 3.多用户共享 4.独立的数据集合 5. 关系型数据 mysql oracle sql server db2 sybase 6. 非关系型数据库 redis MongoDB 7.主要学习的是 mysql数据库 7.1 环境安装 服务端安装 客户端的安装 7.2 数据库操作 1. 显示数据库 show databases; 2. 进入指定数据库 use 数据库名称; 3. 创建数据库 create database 数据库名称 default character set=utf8; 4.删除数据库 drop database 数据库名称; 7.3 数据库表操作: 1.创建表: create table studentInfo2( name VARCHAR(10) not NULL, sex char(10) null, age int(5), phone BIGINT(11) ) 2.删除表 drop table 表名; 7.4 新增表数据 #一次增加一条数据 insert into studentinfo (name,sex,age) VALUES('大花','男','12') #一次增加多条数据 insert into studentinfo (name,sex,age) VALUES('大花','男','12'),('二花','女','32') insert into 表名称 (字段名称,多个以“,”间隔)values(‘具体的值’多个以“,”间隔) 7.5 修改 update studentinfo set name='花花' where name='二花' 7.6 删除 delete from 表名 where 条件 练习: 1.要求:将武当派 张三 修改为 张三丰 update ren set p_name ='张三丰' where p_name='张三' -- 1.查询所有人员? -- select * from ren; -- 2.只查询人员的姓名和年龄? -- select p_name,p_age from ren; -- 3.查询年龄为20岁的人有哪些? -- select * from ren where p_age ='20'; -- 4.查询60岁以下的人员有哪些? -- select * from ren where p_age < '60' -- select * from ren where p_age != '60' -- 常见的逻辑运算符 <,>,= <=,>=,<>,!= -- 5.查询50岁以上并且工资大于8000的人员有哪些? -- select * from ren where p_age >50 || p_sal <8000 -- 注意: and 用于连接两个条件 表示并且意思 -- 注意2: or 用于连接两个条件 表示或者意思 -- 6.查询姓[张]的人员有哪些? -- select * from ren where p_name LIKE '张%' -- select * from ren where p_name LIKE '%张%' -- 7.查询哪些人员属于 武当/华山/嵩山? -- select * from ren where p_menpai ='武当' or p_menpai ='华山' or p_menpai='嵩山'; -- select * from ren where p_menpai not in('武当','华山','嵩山'); -- 8.查询工资在 5000-8900的人员有哪些? -- select * from ren where p_sal >=5000 and p_sal<= 8900; -- select * from ren where p_sal between 5000 and 8900; -- 9.查询所有人员,要求按工资倒序排列? -- select * from ren where p_sal>3000 ORDER BY p_sal asc -- 10.查询年龄为21岁人员的领导人是谁? select p_leader from ren where p_age ='21' select * from ren where p_id ='p003' select * from ren where p_id =(select p_leader from ren where p_age ='21')
-- 回顾 1.数据库 概念:存储数据,以文件的形式存储 好处:1.永久保存数据(理论上) 2.数据共享 3.可以通过命令进行数据的精准查找 2.数据库分类 1.关系型数据 mysql oracle sql server db2 .... 特点:以表格形式进行数据库存储 2.非关系型数据(NOSQL数据库) MongoDB redis 3.mysql 介绍 1.优点: 免费,可靠,支持千万级的数据吞吐量 2.环境安装 安装包方式(next...) 解压方式安装(http://www.cnblogs.com/wangfengming/p/7880595.html) 客户端安装 3.连接数据 mysql -u root -p 回车 输入密码 ****** 4.数据库的操作 1.创建 create database 库名; 2.进库 use 库名; 3.删库 drop database ku; 4.显示当前用户下所有的数据库 show databases; 5. 表操作 1.创建 create table 表名( 字段名 类型(长度) 是否为空 是否为主键 ) 2. 删除表 drop table 表名; 3.修改表的字段 alter table 表名 add 字段名称 类型(长度) 约束条件; alter table 表名 drop 字段名称; alter table 表名 change 旧字段 新字段 类型(长度) 约束条件; 4.查看表 desc 表名; 6.sql 增删改查 6.1 新增 insert into 表名 values(要求:字段的位置与个数必须一一对应) insert into 表名(表字段名称,多个以“,”间隔)values(字段值多个以“,”间隔) insert into 表名2 (select * from 表名) 6.2 修改 update 表名 set 字段名=‘值’ where 字段名=‘条件值’ update 表名 set 字段1 =‘值1’,字段2=‘值2’ where 字段1="条件1" and 字段2=‘条件2’ 6.3 删除 delete from 表名 where 条件1 =‘值1’ delete from 表名; 6.4 清空表 truncate 表名; 6.5查询(核心) 1.查询所有 select * from 表名; select :表示查询 * :表示所有(通配符) from :表示从哪个表进行查询 注意:最好把“*”换成具体字段 2.查询某两个字段 select 字段1,字段2 from 表名 3. 根据条件查询 select * from 表 where 字段1 =‘值1’ where :表示条件,跟在where后面的统统称之为条件 4. 多条件查询 select * from 表名 where 字段1=‘值1’ and/or 字段2=‘值2’ and/or 字段3=‘值3’ 注意 and 表示并且 or 表示 或者 5. 逻辑运算符查询 select * from 表 where 字段1 != 值1 and z2 >=v2 逻辑运算符: = ,<,>,!=,<>,<=,>= 6.模糊查询 select * from 表名 where 字段 like '%羊蝎子' like :表示模糊查询 以什么开头: "s%" 以什么结尾:'%s' 包含: '%s%' 7 集合查询 select * from 表名 where 字段 in('值1','值2','值3') in :表示 集合 not in:表示反向集合 8.区间查询 select * from 表 where 字段 between z1 and z2; 注意: between ... and ... 表示区间查询 9.排序 select * from 表 order by 字段 asc 注意:order by 表示排序 正序: ASC 默认 倒序: DESC 10.嵌套查询 select * from 表 where 字段 in(select 字段 from 表 where id=“值1”) 注意:()优先执行 总结: 遇到"="值唯一, 遇到in值为集合 2.今日内容 --- -------------聚合函数------------------- -- 11.查询当前人员中谁的工资最高? select max(p_sal) as p_sal from ren ; select p_name from ren where p_sal =(select max(p_sal) as p_sal from ren) 注意: max() 表示最大值 as 表示 起别名 -- 12.查询当前人员中谁的工资最低? select p_name from ren where p_sal = (select min(p_sal) from ren) 注意:min()表示最小值 -- 13.查询所有人员的平均工资是多少? select AVG(p_sal) from ren 注意:avg():表示平均值 -- 14.查询所有人员的工资总和是多少? select sum(p_sal) from ren 注意 sum() 求和 -- 15.查询目前有多少个人员? select count(p_id) from ren 注意 count(主键) 表示查询表中数据的总条数 -- 16.查询各门派的平均工资是多少? select avg(p_sal),p_menpai,p_name from ren GROUP BY p_menpai order by avg(p_sal) desc 注意 group by 表示分组 -- 17.查询武当派最高工资是谁? select p_name from ren where p_sal = (select max(p_sal) from ren where p_menpai ='武当') and p_menpai ='武当' -- 18.查询当前武林中有哪些门派? select p_menpai from ren GROUP BY p_menpai; select DISTINCT p_menpai,p_name from ren 注意:DISTINCT 表示去重复查询,要求查询的所有字段必须一样,才认为是重复数据 -- 19.查询当前武林中有哪些门派和门派的平均工资是多少? select p_menpai,avg(p_sal) from ren GROUP BY p_menpai -- 20.查询当前人员表的中的第3条数据到第7条数据? select * from ren LIMIT 2,5 注意 limit 表示分页 参数1:表示从第几条开始查询,下标从0开始 参数2:表示每次查询多少条数据 -- 21.查询没有门派的人员有哪些? select * from ren where p_menpai is null; 表示查询字段为 null 的数据 select * from ren where p_menpai =''; 表示查询字段为 '' 的数据 update ren set p_menpai = null where p_id='p008' 注意:修改字段为null 时 要写 = -- 22.查询武当派下有哪些小弟? select * from ren where p_leader =(select p_id from ren where p_menpai='武当' and p_leader='0') · select * from ren where p_menpai ='武当' and p_leader !='0' -- 23.查询各门派的工资总和按倒序/正序排列 select sum(p_sal) sal,p_menpai from ren GROUP BY p_menpai ORDER BY sal -- 24.查询人员并显示门派所在位置(多表联合查询) select * from ren,wei where ren.p_menpai = wei.a_name 注意:如果多表联合查询不加条件则会出现(笛卡尔乘积) 注意:在使用多表联合查询时,一定要加条件 结果:符合两个表条件的结果 -- 25.查询人员表,如果人员门派存在位置则显示位置信息,不存在则不显示位置 select * from ren LEFT JOIN wei on ren.p_menpai = wei.a_name 左连接查询 注意:on 表示条件 专门配置 left join 来使用 特点:左表数据全要,右表的数据与左表数据相匹配则显示,不匹配则以NULL填充 -- 26.查询位置表,如果人员的门派有位置信息则显示人员,没有则不显示. select * from ren RIGHT JOIN wei on ren.p_menpai = wei.a_name -- 27.查询登记了地理位置的门派人员信息 select * from ren INNER JOIN wei on ren.p_menpai = wei.a_name 作业:http://www.cnblogs.com/wangfengming/p/7944029.html
数据库的由来:
描述事物的符号记录称为数据,描述事物的符号既可以是数字,也可以是文字、图片,图像、声音、语言等,数据由多种表现形式,它们都可以经过数字化后存入计算机
在计算机中描述一个事物,就需要抽取这一事物的典型特征,组成一条记录,就相当于文件里的一行内容,如:
1 egon,male,18,1999,山东,计算机系,2017,oldboy
单纯的一条记录并没有任何意义,如果我们按逗号作为分隔,依次定义各个字段的意思,相当于定义表的标题
1 name,sex,age,birth,born_addr,major,entrance_time,school #字段 2 egon,male,18,1999,山东,计算机系,2017,oldboy #记录
这样我们就可以了解egon,性别为男,年龄18岁,出生于1999年,出生地为山东,2017年考入老男孩计算机系
2 什么是数据库(DataBase,简称DB)
数据库即存放数据的仓库,只不过这个仓库是在计算机存储设备上,而且数据是按一定的格式存放的
过去人们将数据存放在文件柜里,现在数据量庞大,已经不再适用
数据库是长期存放在计算机内、有组织、可共享的数据即可。
数据库中的数据按一定的数据模型组织、描述和储存,具有较小的冗余度、较高的数据独立性和易扩展性,并可为各种 用户共享
========================================================================================================================
我们要进行数据传输的时候只能通过文件来操作,但是文件操作的效率太低了,而且文件只能存在于一台电脑上面,查询或者更改之后只有自己可以看到,别人看不到的,
这样就很麻烦,基于这个考量我们有了数据库的存在,它是可以多用户共享,大家都能看到这个东西,而且你有任何的改变别人也可以直接在自己的电脑上面看到结果.
但是由于数据库的庞大,导致了我们使用的时候要有规范,即数据库语言,通过这一套的规范流程,大家都基于此访问数据库,就完美的达到了想要的效果,实现了效率最大化.
那么就开始来学习数据库语言了.
首先要有库才能有数据,所以我们要先建立库,---create database 库名 这句命令行就是创建库. create就是创建,然后database,就是库,
--------
库的增删改查:
create database 库名 这句命令行就是创建库. 库创建了之后就要基于它进行操作
drop database 库名 删除库,
show databases 显示所有存在的库
use 库名 进入指定的库
然后我们有了库之后就开始在库里面进行操作,最重要的是库里面的表,即Excel表的表,当然了这里并不是Excel,
在库里创建表
---------
create table time (id int primary key not null, d date, t time ,dt datetime);not null 是不能为空,默认不写就是可以为空,
create table 表名(字段名 字段类型 字段类型长度[特殊字段是没有长度的,比如邮箱,比如日期] 是否为主键 是否为空 , 字段名 字段类型 字段类型长度 是否为空 )这里的字段名就是Excel表里面的表头, 然后字段类型就是数据类型,有字符串,数字, 固定长度的字符串,不固定长度的,时间类型的字符串.....数据里面有整数,小数,大整数(bigint,他的长度要比int长,没错,整数都是有上限的,不能够无限大,)等等.
所谓的主键{不能为空,且不能重复,}
还有一种特殊的主键——复合主键。主键不仅可以是表中的一列,也可以由表中的两列或多列来共同标识.[也就是说a和b是复合主键,a,b都不能为空,a可以一样,但同时b不能一样,或者b能一样,但是a不能一样,这样就满足了复合主键的条件]
就是字段里面的唯一的那个字段,也就是说表头里面的其中一个表头是唯一的,在这些条件限制里面,字段名必须要有,而且不能能够有重复的,字段类型也是必须要有的,没有那些必要条件是会报错的.
表的增删改查:
create table 表名( 字段名1 类型[(宽度) 约束条件], 字段名2 类型[(宽度) 约束条件], 字段名3 类型[(宽度) 约束条件] ); #注意: 1. 在同一张表中,字段名是不能相同 2. 宽度和约束条件可选 3. 字段名和类型是必须的
drop table 表名 删除整张表
update 表名 set 字段名2=值2 where 字段1=值1 修改表
delete from 表名 where 字段名=值 删除表里面的其中一条内容,
insert into 表名 (字段名)values(字段对应的值) 新增加的内容,可以增加多个,一般都是多个一起增加,类似于字典里的键对值,如果value就是只增加一个,
show tables 查看该库下面所有的表
例如:
表里面的字段的增删改查:
语法:
1. 修改表名
ALTER TABLE 表名 RENAME 新表名;
2. 增加字段
ALTER TABLE 表名 ADD 字段名 数据类型 完整性约束条件,
3. 删除字段
ALTER TABLE 表名 DROP 字段名;
4. 修改字段
ALTER TABLE 表名 MODIFY 字段名 数据类型 完整性约束条件; 这里是修改字段的约束条件,比如把int改成char
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 数据类型 完整性约束条; 这里是改变字段名,比如把id字段改成sex字段
alter table attendance change afternoon afternoon_on enum('1','0');
字段的一些操作示例:
示例:
1. 修改存储引擎
mysql> alter table service
-> engine=innodb;
2. 添加字段
mysql> alter table student10
-> add name varchar(20) not null,
-> add age int(3) not null default 22;
mysql> alter table student10
-> add stu_num varchar(10) not null after name; //添加name字段之后
mysql> alter table student10
-> add sex enum('male','female') default 'male' first; //添加到最前面
3. 删除字段
mysql> alter table student10
-> drop sex;
mysql> alter table service
-> drop mac;
4. 修改字段类型modify
mysql> alter table student10
-> modify age int(3);
mysql> alter table student10
-> modify id int(11) not null primary key auto_increment; //修改为主键
5. 增加约束(针对已有的主键增加auto_increment)
mysql> alter table student10 modify id int(11) not null primary key auto_increment;
ERROR 1068 (42000): Multiple primary key defined
mysql> alter table student10 modify id int(11) not null auto_increment;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
6. 对已经存在的表增加复合主键
mysql> alter table service2
-> add primary key(host_ip,port);
7. 增加主键(在已有字段里面增加主键)
mysql> alter table student1
-> modify name varchar(10) not null primary key;
7.1增加外键(在已有字段里面增加外键)
mysql> alter table schedule add constraint attend_id
-> foreign key(atd_id)references attendance(attend_id) on delete cascade on update cascade;
alter table 表名
add constraint 外键名称 foreign key (字段)
references 关系表名 (关系表内字段)
8. 增加主键和自动增长(在已有的字段里面增加主键)
mysql> alter table student1
-> modify id int not null primary key auto_increment;
9. 删除主键
a. 删除自增约束
mysql> alter table student10 modify id int(11) not null;
b. 删除主键
mysql> alter table student10
-> drop primary key;
复制表:
复制表结构+记录 (key不会复制: 主键、外键和索引)
mysql> create table new_service select * from service;
只复制表结构
mysql> select * from service where 1=2; //条件为假,查不到任何记录
Empty set (0.00 sec)
用如下表格做示例
mysql> desc task_summary_record; +-----------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-----------------+--------------+------+-----+---------+----------------+ | task_summary_id | int(11) | NO | PRI | NULL | auto_increment | | summary_id | int(11) | NO | MUL | NULL | | | total_data | char(20) | YES | | NULL | | | p_id | int(11) | YES | MUL | NULL | | | done_date | date | NO | | NULL | | | remarks | varchar(300) | YES | | NULL | | +-----------------+--------------+------+-----+---------+----------------+
用select * 复制结果对比 仔细看key和extra这两列信息
mysql> create table tb_0 select * from task_summary_record where 1=2;
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> desc tb_0;
+-----------------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------------+--------------+------+-----+---------+-------+
| task_summary_id | int(11) | NO | | 0 | |
| summary_id | int(11) | NO | | NULL | |
| total_data | char(20) | YES | | NULL | |
| p_id | int(11) | YES | | NULL | |
| done_date | date | NO | | NULL | |
| remarks | varchar(300) | YES | | NULL | |
+-----------------+--------------+------+-----+---------+-------+
6 rows in set (0.00 sec)
用like命令复制结果对比
这里复制的是完整的表结构,用like命令复制结果。如下是完整表结构复制对比,用desc命令查看表结构,仔细看key和extra这两列信息
mysql> create table tb4 like task_summary_record;
Query OK, 0 rows affected (0.01 sec)
mysql> desc tb4;
+-----------------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-----------------+--------------+------+-----+---------+----------------+
| task_summary_id | int(11) | NO | PRI | NULL | auto_increment |
| summary_id | int(11) | NO | MUL | NULL | |
| total_data | char(20) | YES | | NULL | |
| p_id | int(11) | YES | MUL | NULL | |
| done_date | date | NO | | NULL | |
| remarks | varchar(300) | YES | | NULL | |
+-----------------+--------------+------+-----+---------+----------------+
这里是插入更新操作:
ON DUPLICATE KEY UPDATE
向数据库中插入一条数据,如果插入的这条数据中的联合主键已经存在了,就执行update后面的更新操作,否则就执行insert操作.
测试代码:先创建表格,然后插入数据,再使用这个语句看执行效果.
DROP TABLE IF EXISTS `mRowUpdate`;
CREATE TABLE `mRowUpdate` (
`id` int(11) NOT NULL,
`value` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
一行语句插入多条数据:
INSERT INTO `mRowUpdate` VALUES ('1', 'sss'), ('2', 'szh'), ('3', '9999');
一行语句插入一条数据:
INSERT INTO `mRowUpdate` VALUE ('11', '1sss');
INSERT INTO mRowUpdate(id,`value`) VALUES(3, 'SuperMan') ON DUPLICATE KEY UPDATE `value`='SuperMan';
最后执行结果就是insert的最后一条数据,'9999'变成了SuperMan.
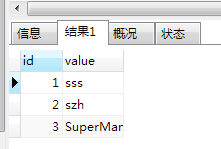
这里就是结果
这种操作一般适用于多行数据插入更新.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号