
day16 函数的用法:内置函数,匿名函数
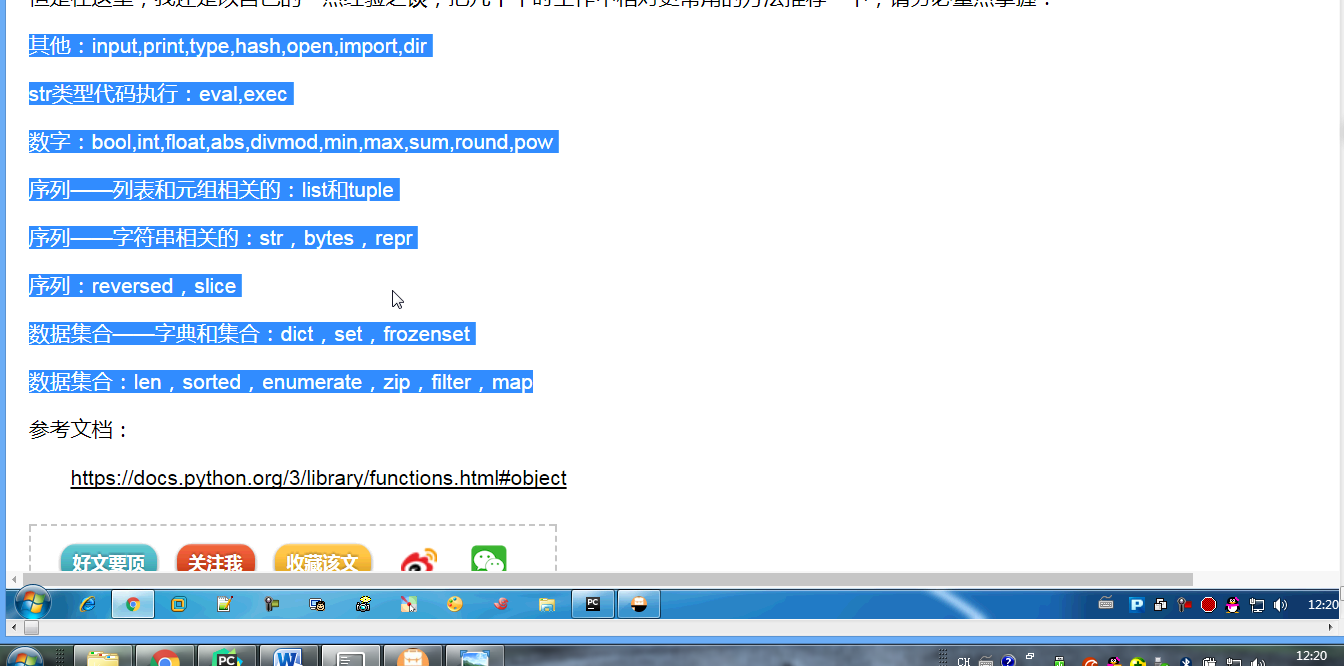
思维导图需要补全 :

一共有68个内置函数:



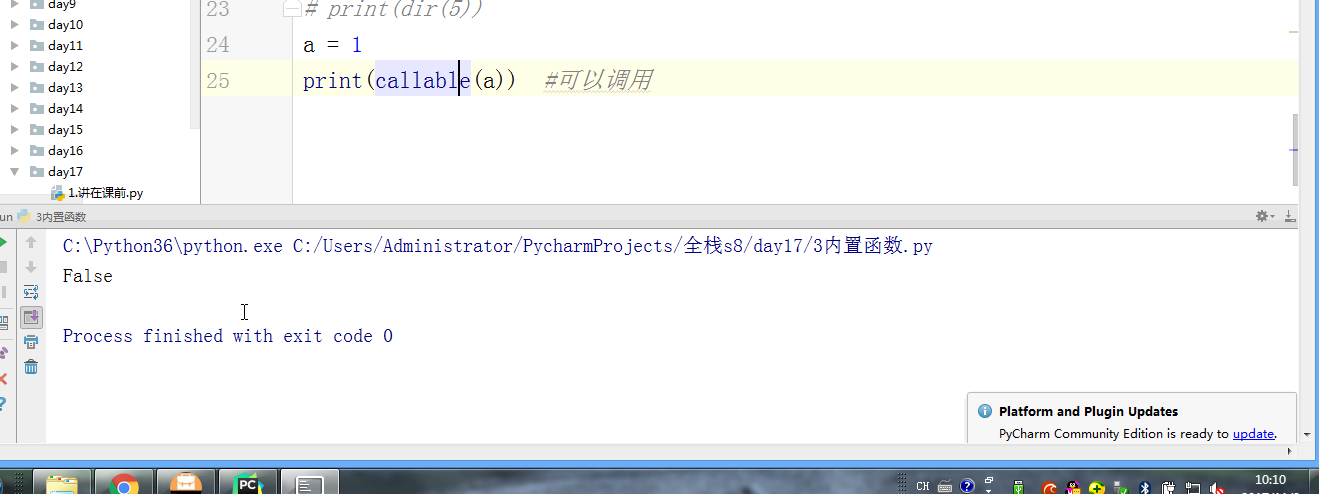
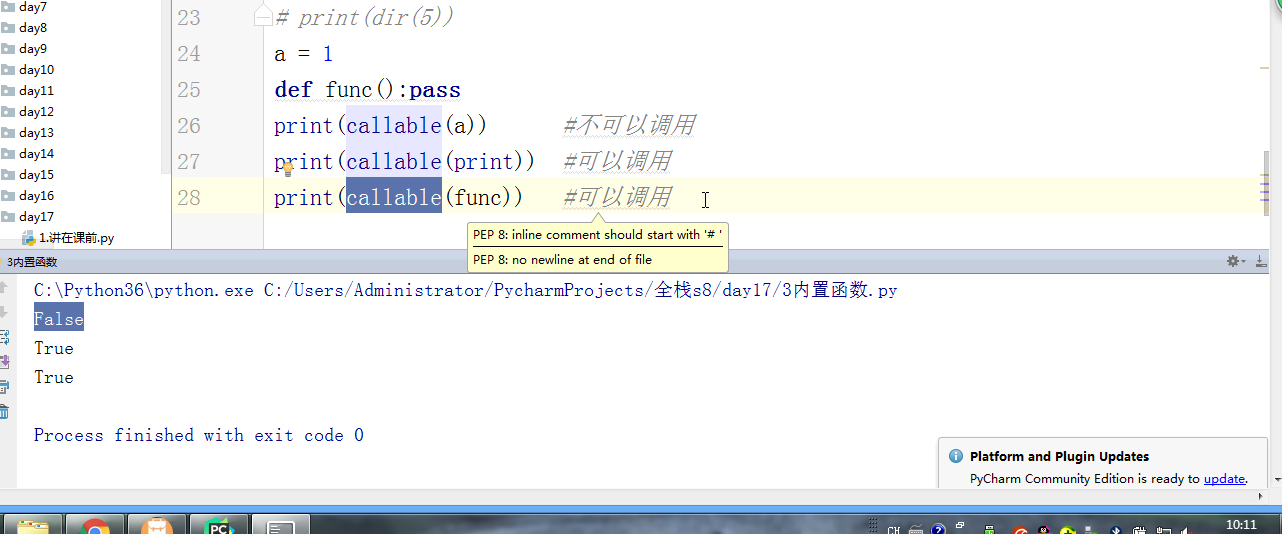
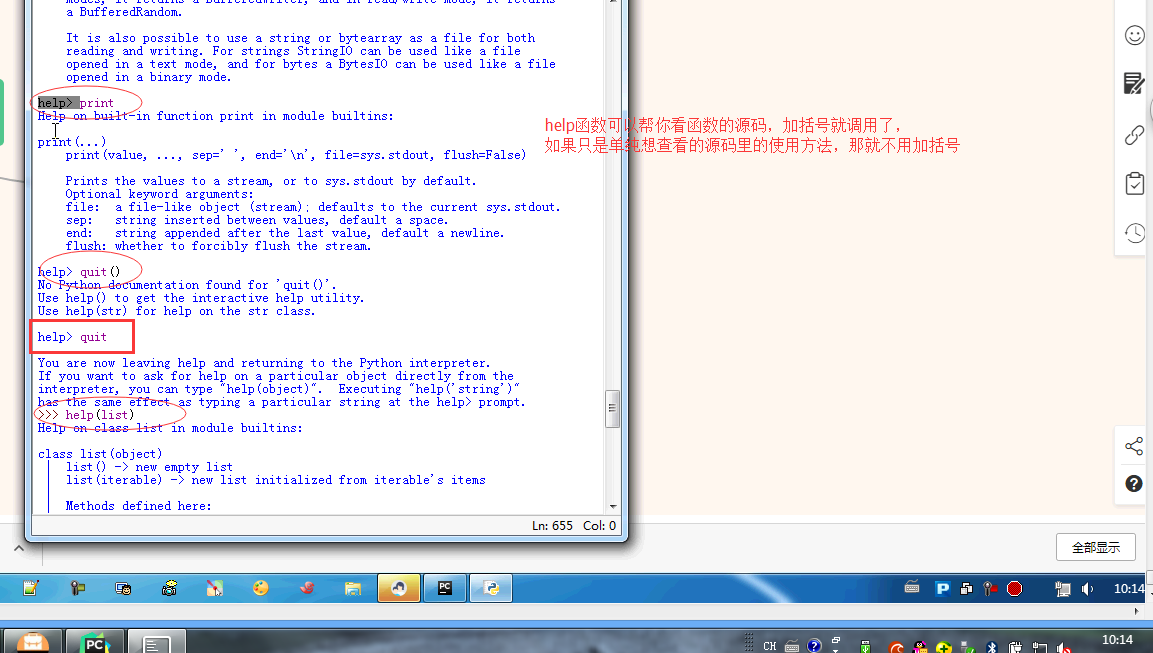
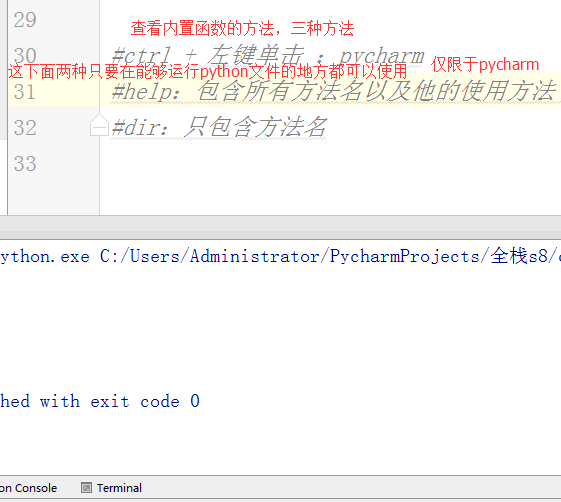
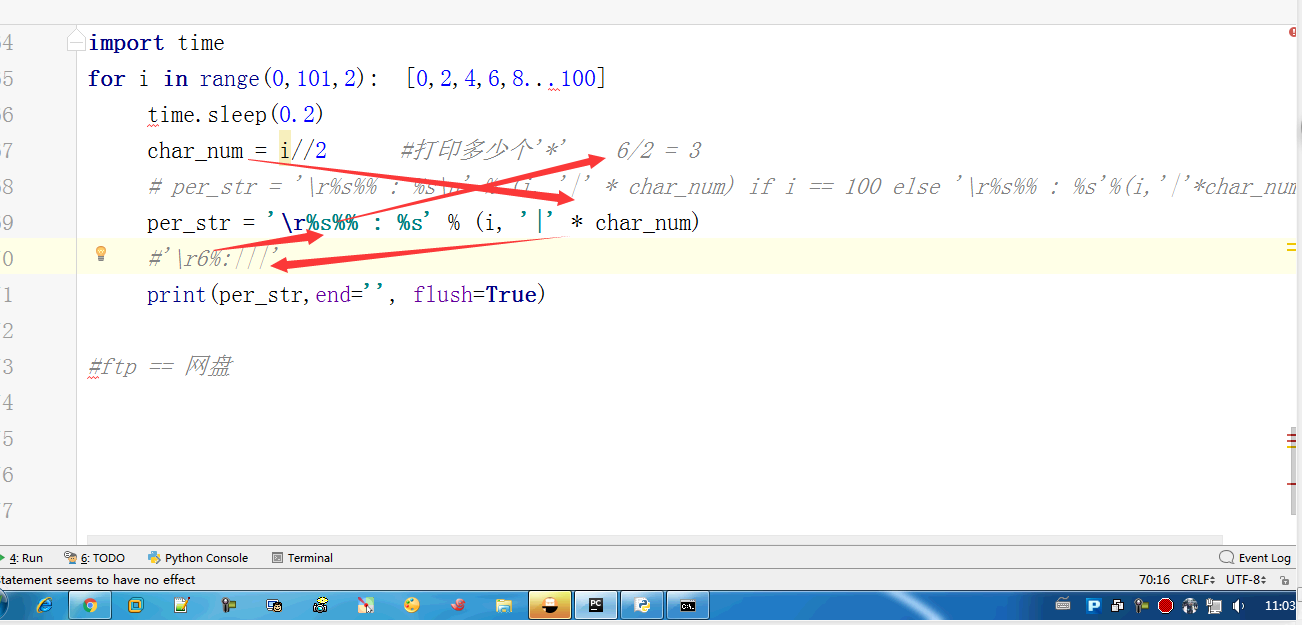
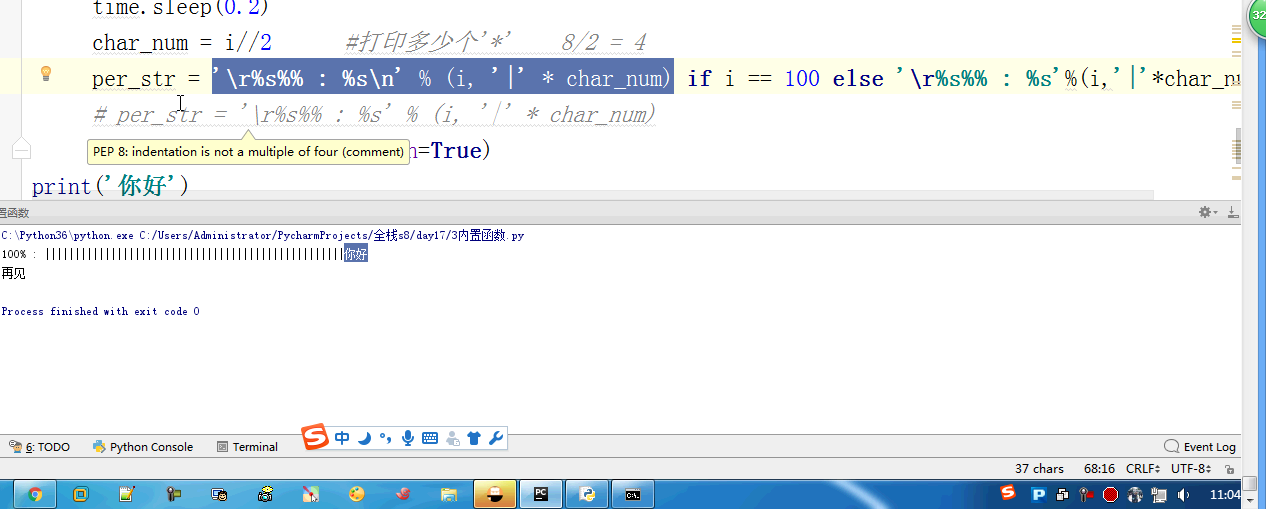
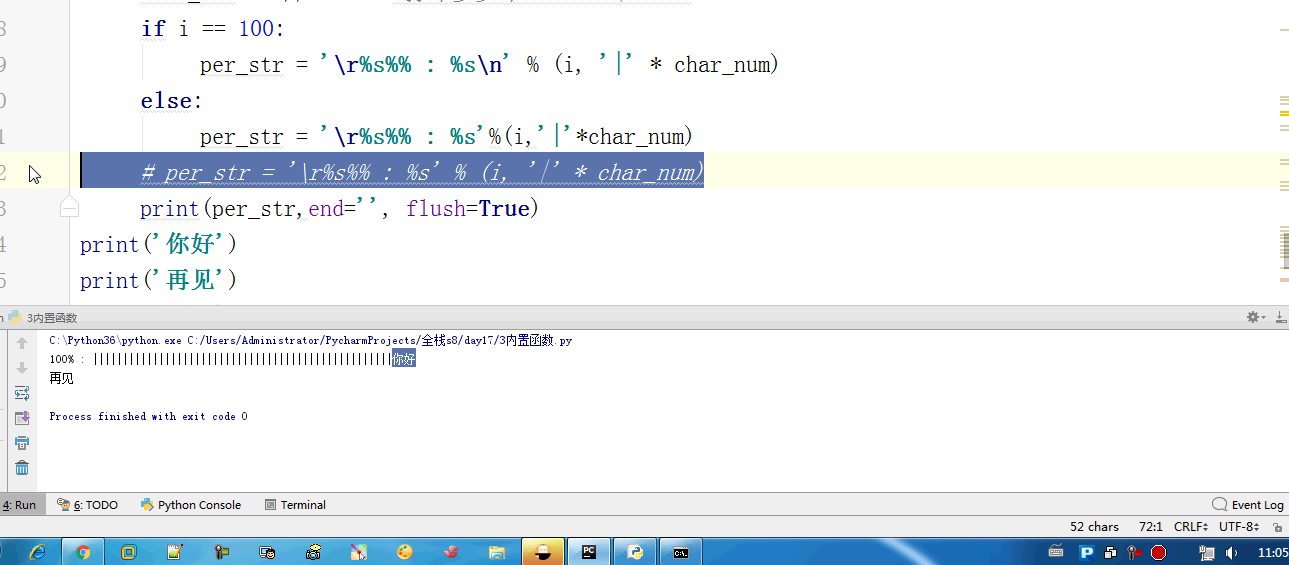
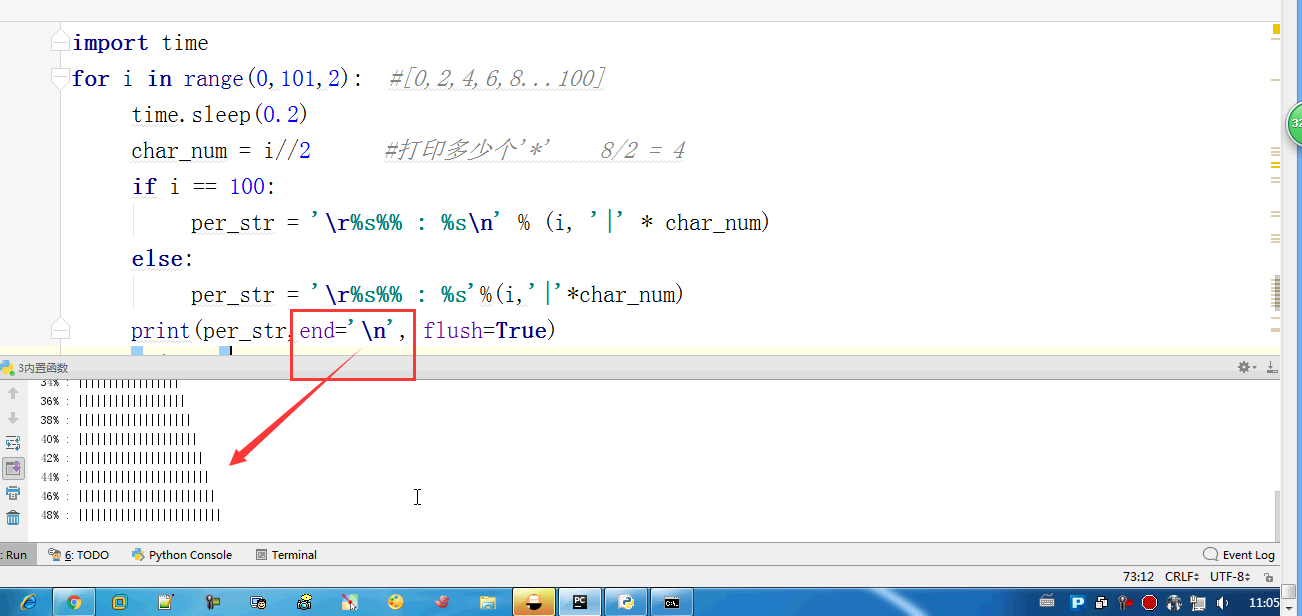
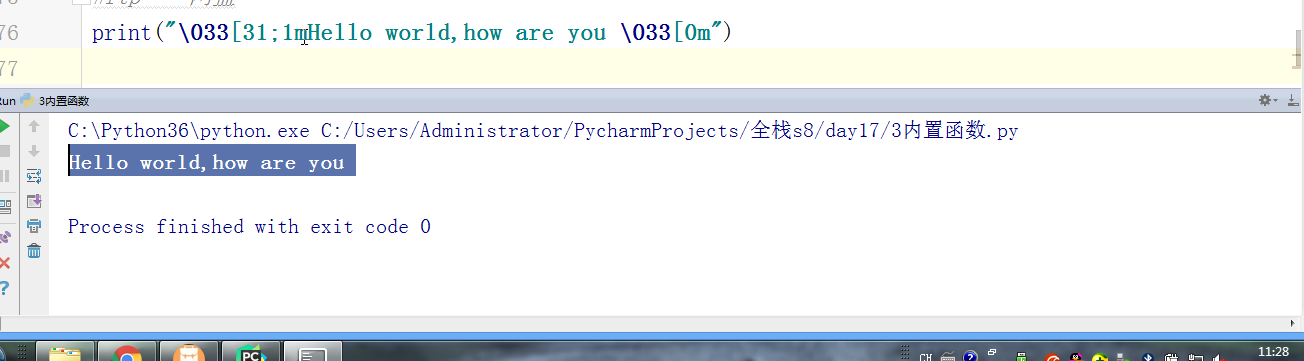
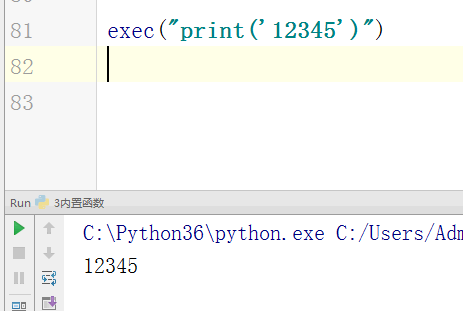
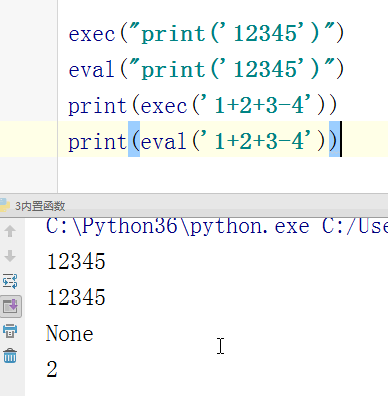
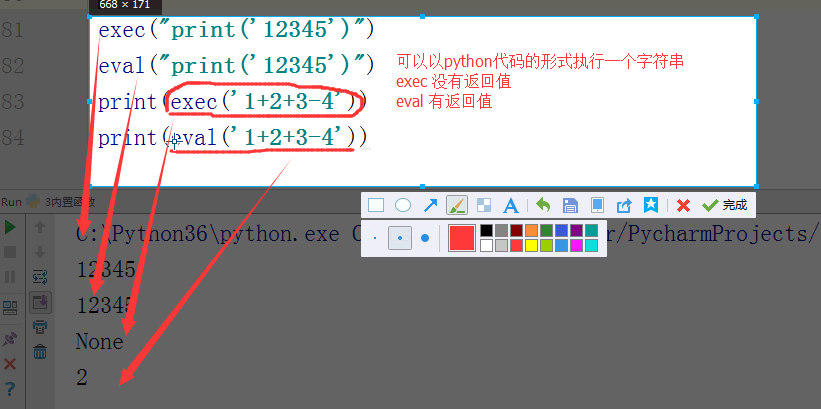
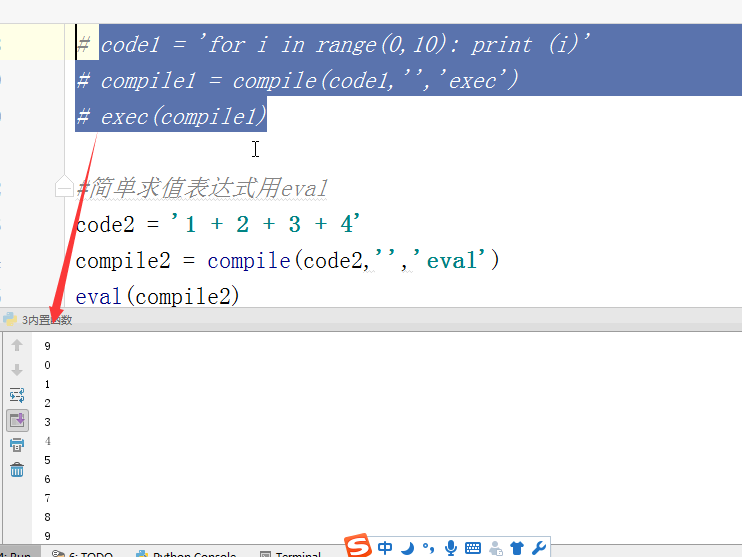
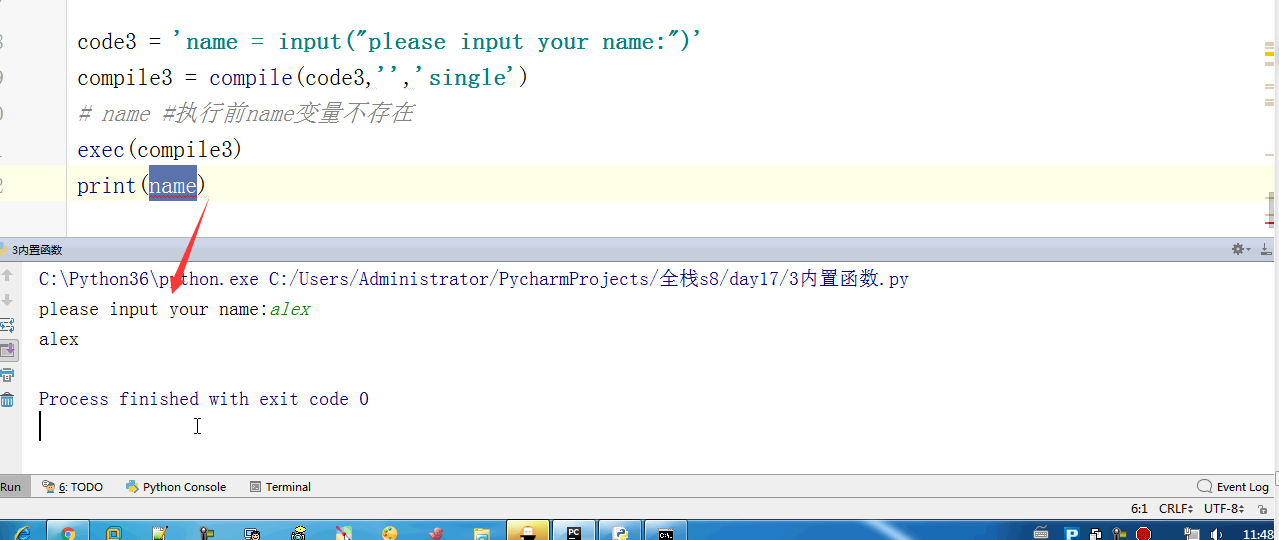
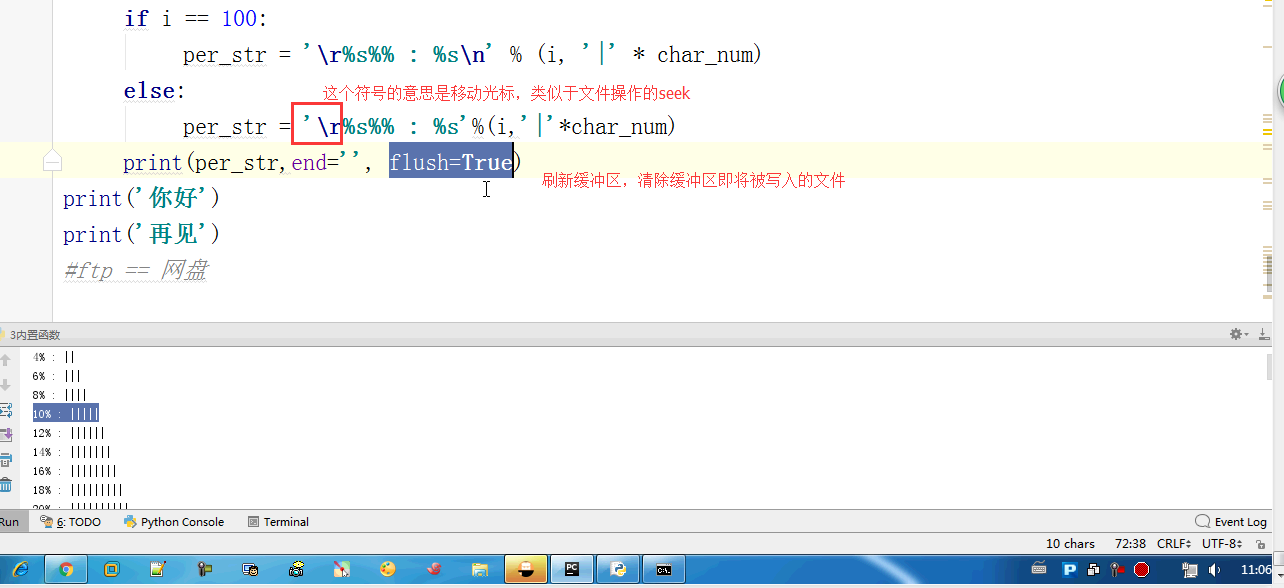
#内置:python自带 # def func(): # a = 1 # b = 2 # print(locals()) # print(globals()) # func() # range(100) #[0,100) # range(5,100) #[5,100) # range(1,100,2) #可迭代对象,可以for循环,惰性运算 # range(100).__iter__() # iterator = iter(range(100)) #拿到一个迭代器 # print(iterator.__next__()) # print(next(iterator)) # for i in range(100): # print(i) # def iter(): # return range(100).__iter__() # print(dir([])) # print(dir(5)) # a = 1 # def func():pass # print(callable(a)) #不可以调用 # print(callable(print)) #可以调用 # print(callable(func)) #可以调用 #ctrl + 左键单击 :pycharm #help:包含所有方法名以及他的使用方法 —— 不知道用法 #dir:只包含方法名 —— 想查看某方法是否在这个数据类型中 import time #时间 import os #操作系统 # f = open('文件名','w',encoding='utf-8') #打开模式:r、w、a、rb、wb,ab #编码 utf-8/GBK # print(id(1)) # print(id(2)) # print(hash('sajghfj;eyrwodnvjnz,.jifupwk')) #算法 # print(hash(125342)) # print(hash((1,2,3,4))) #数据的存储和查找 #模块:hashlib # {'k':'v'} # [1,2,3,4,5,6,] # hash([1,2,3,4,5,6,]) #hash 判断一个数据类型是否可以hash #在一个程序执行的过程中,对同一个值hash的结果总是不变 #多次执行,对同一个值的hash结果可能改变 # s = input('提示:') # print(1,2,3,4,5,sep='*') #sep是指定多个要打印的内容之间的分隔符 # print(1,2,sep=',') #print('%s,%s'%(1,2)) # f = open('a','w') # print('abc\n') # print(2) # import time # for i in range(0,101,2): #[0,2,4,6,8...100] # time.sleep(0.2) # char_num = i//2 #打印多少个'*' 8/2 = 4 # if i == 100: # per_str = '\r%s%% : %s\n' % (i, '|' * char_num) # else: # per_str = '\r%s%% : %s'%(i,'|'*char_num) # print(per_str,end='', flush=True) # print('你好') # print('再见') #ftp == 网盘 # print("\033[31;1mHello world,how are you \033[0m") # print('\033[4;32;41m金老师') # print('egon') # print('alex \033[0m') # exec("print('12345')") # eval("print('12345')") # print(exec('1+2+3-4')) # print(eval('1+2+3-4')) # a = 1+2+3-4 # print(1+2+3-4) # code1 = 'for i in range(0,10): print (i)' # compile1 = compile(code1,'','exec') # exec(compile1) #简单求值表达式用eval # code2 = '1 + 2 + 3 + 4' # compile2 = compile(code2,'','eval') # print(eval(compile2)) # code3 = 'name = input("please input your name:")' # compile3 = compile(code3,'','single') # # name #执行前name变量不存在 # exec(compile3) # print(name) #exec #eval #compile # print(abs(5)) # ret = divmod(10,2) #商余 # print(ret) # ret = divmod(3,2) # print(ret) # ret = divmod(7,2) # print(ret) # 107 # 10 # divmod(107,10) # print(round(3.14159,2)) # print(pow(2,3.5)) #幂运算 # print(pow(3,2)) # print(pow(2,3,2)) # print(pow(2,3,3)) #x**y%z # print(sum([1,2,3,4,5,6],-2)) # print(sum(range(100))) #sum接收一个可迭代对象 #min # print(min([1,4,0,9,6])) # print(min([],default=0)) print(min([-9,1,23,5],key=abs))#匿名函数 # print(min({'z':1,'a':2})) # t = (-25,1,3,6,8) # print(max(t)) # print(max(t,key = abs)) # print(max((),default=100))
前情概要:
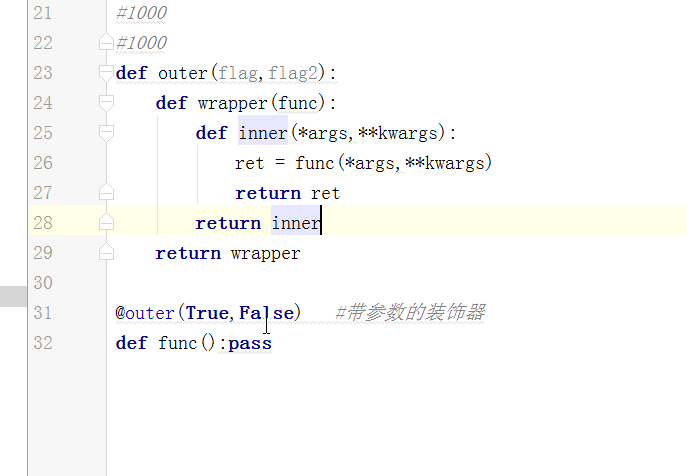
def wrapper1(func): def inner1(*args,**kwargs): print('in wrapper 1,before') ret = func(*args,**kwargs) #qqxing print('in wrapper 1,after') return ret return inner1 def wrapper2(func): #inner1 def inner2(*args,**kwargs): print('in wrapper 2,before') ret = func(*args,**kwargs) #inner1 print('in wrapper 2,after') return ret return inner2 @wrapper2 @wrapper1 def qqxing(): print('qqxing') qqxing() #inner2
内置函数补全:
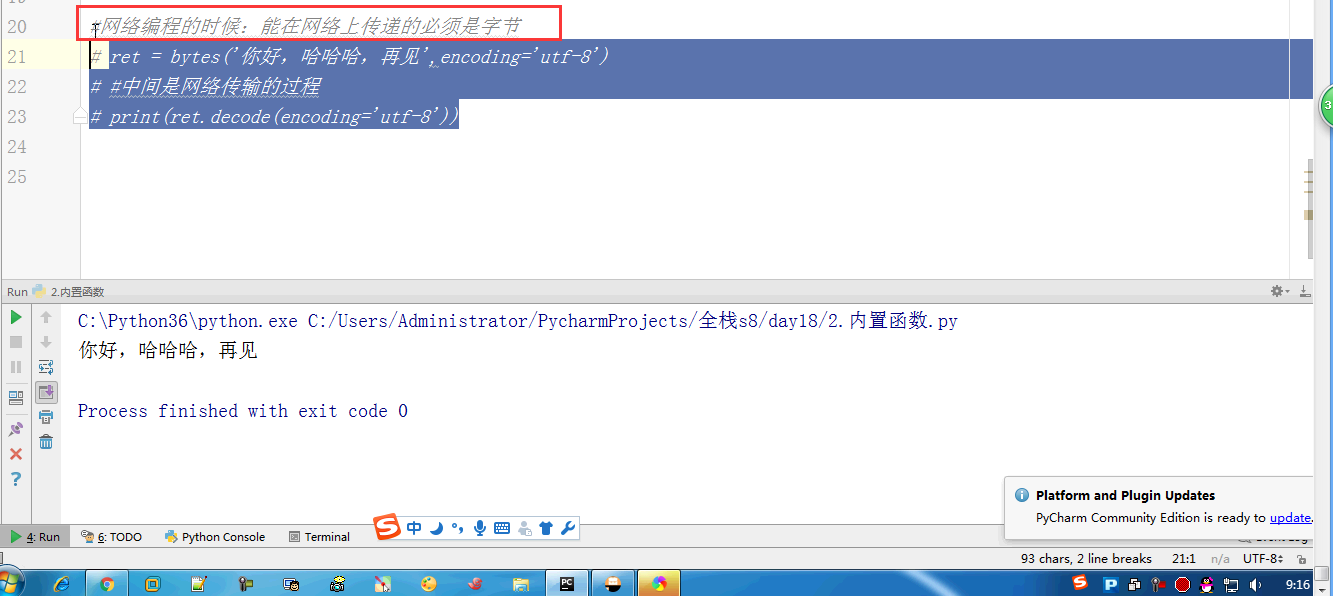
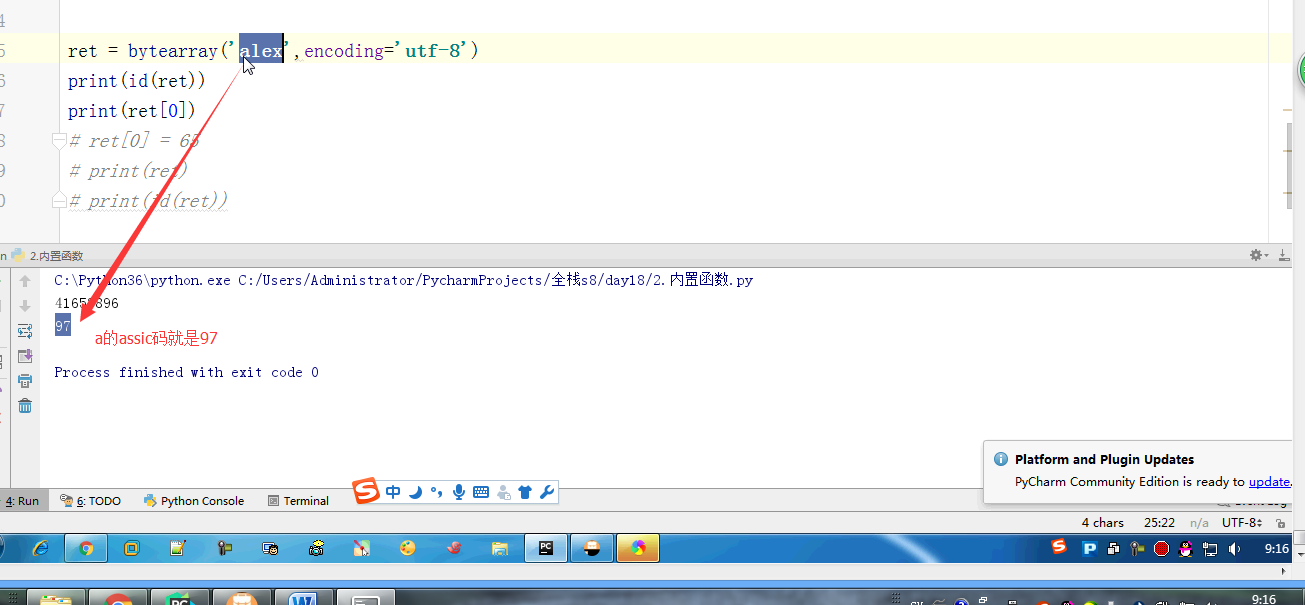
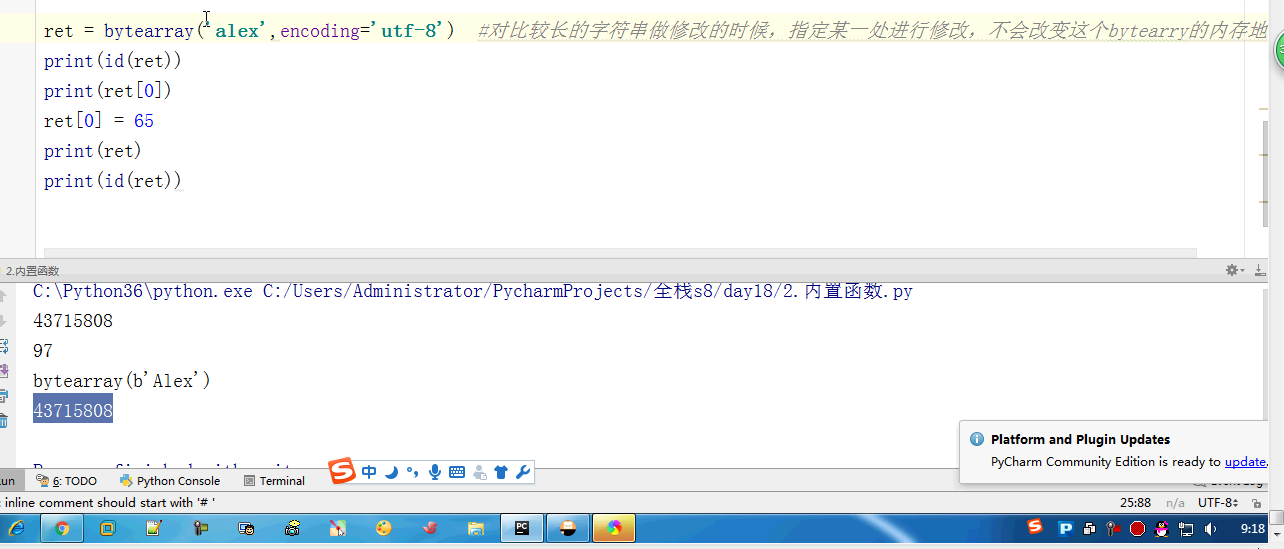
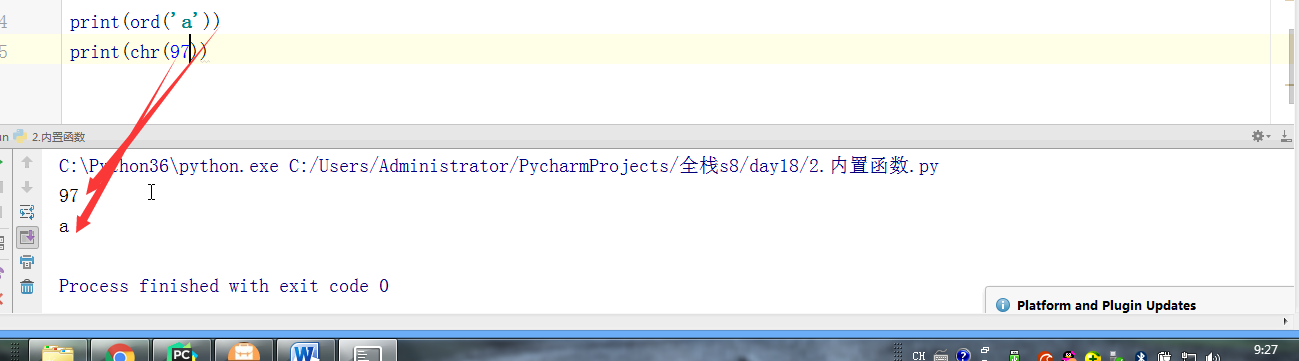
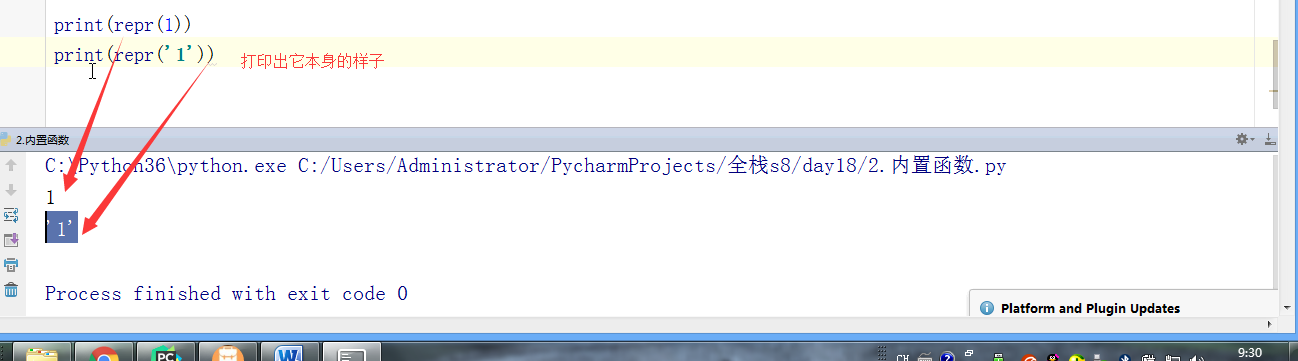
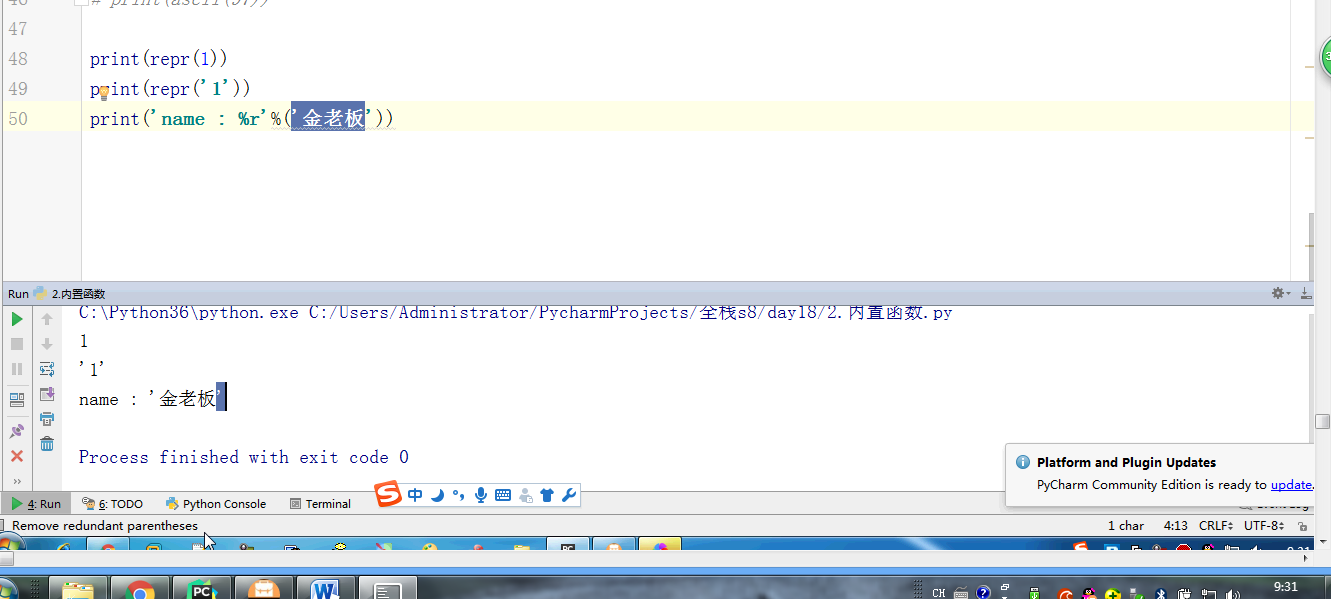
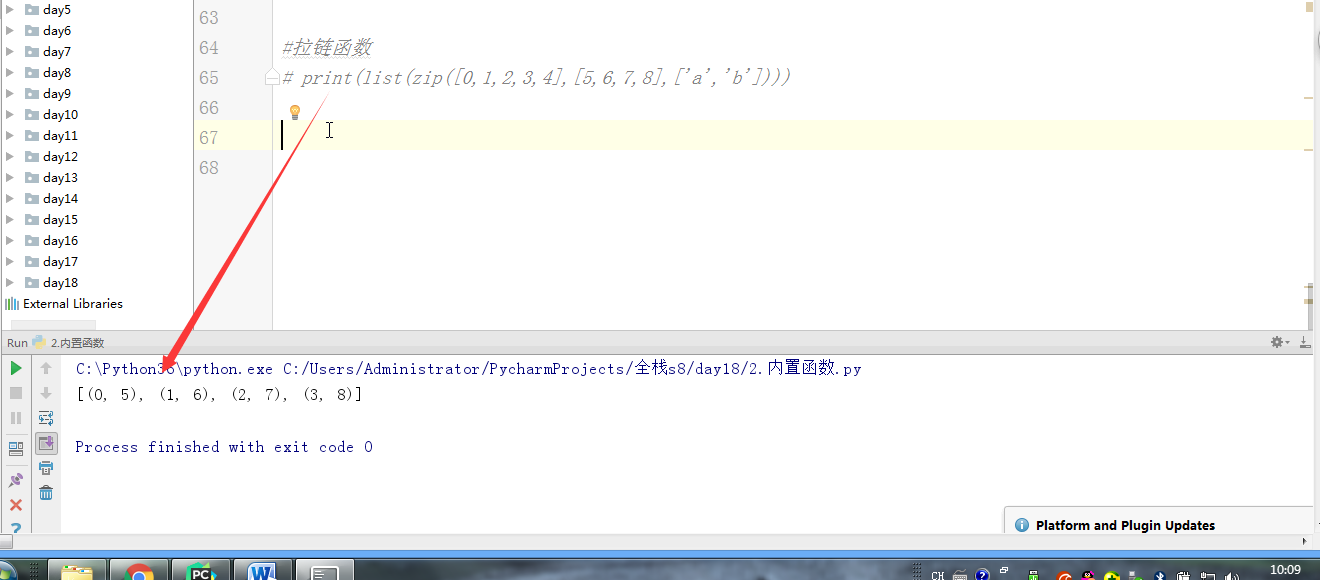
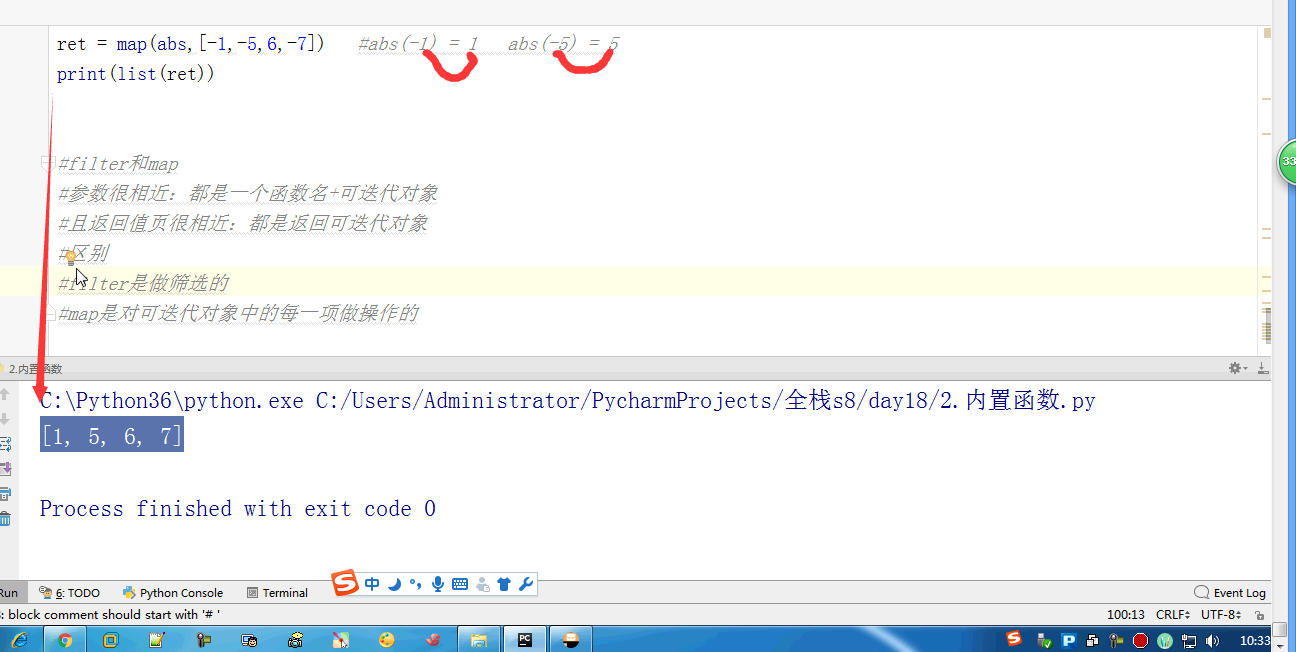
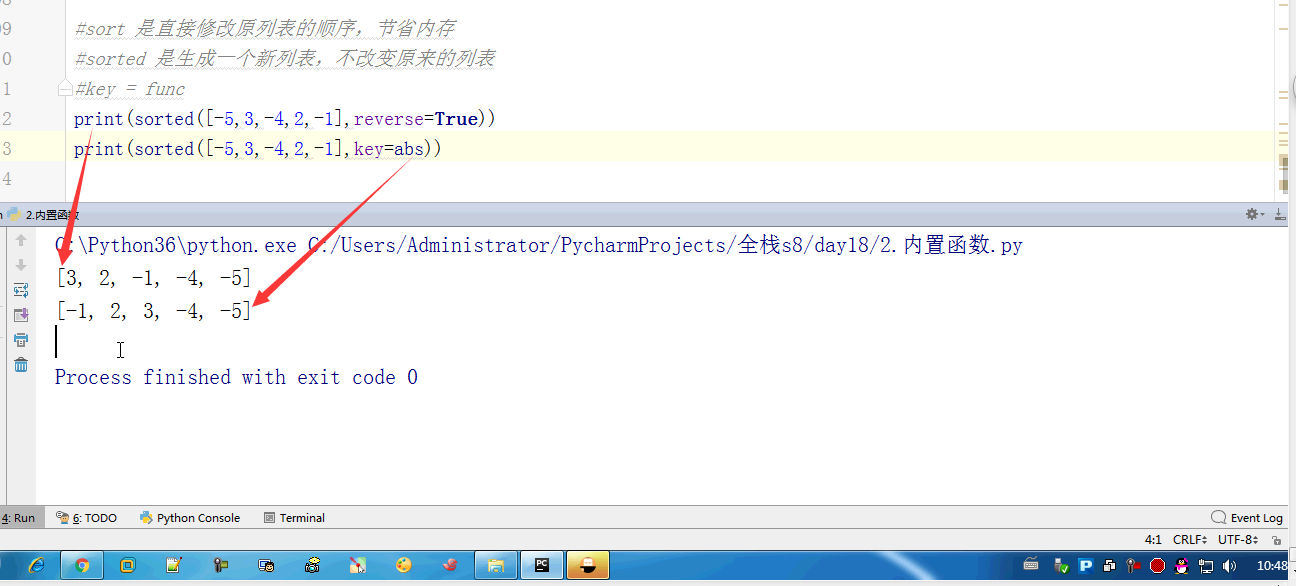
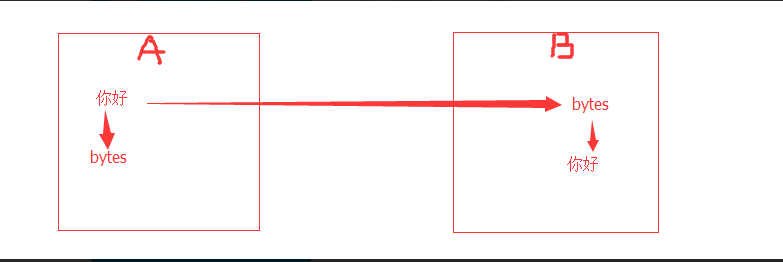
# l = [3,4,2,5,7,1,5] # # ret = reversed(l) # print(ret) # print(list(ret)) # #next ,__next__ # #for # l.reverse() # print(l) # l = (1,2,23,213,5612,342,43) # sli = slice(1,5,2) #实现了切片的函数 # print(l[sli]) # # #l[1:5:2] 语法糖 # print(format('test', '<20')) # print(format('test', '>20')) # print(format('test', '^20')) #网络编程的时候:能在网络上传递的必须是字节 # ret = bytes('你好,哈哈哈,再见',encoding='utf-8') # #中间是网络传输的过程 # print(ret.decode(encoding='utf-8')) # ret = bytearray('alex',encoding='utf-8') #对比较长的字符串做修改的时候,指定某一处进行修改,不会改变这个bytearry的内存地址 # print(id(ret)) # print(ret[0]) # ret[0] = 65 # print(ret) # print(id(ret)) #切片 # l = [1,2,3,4,5,60] # l[1:3] # ret = memoryview(bytes('你好',encoding='utf-8')) # print(ret) # print(len(ret)) # print(ret[:3]) # print(bytes(ret[:3]).decode('utf-8')) # print(bytes(ret[3:]).decode('utf-8')) # print(ord('a')) # print(chr(97)) # print(ascii(97)) # print(repr(1)) # print(repr('1')) # print('name : %r'%('金老板')) # l = ['笔记本','phone','apple','banana'] # for i,j in enumerate(l,1): # print(i,j) # print(all([1,2,3,4,0])) # print(all([1,2,3,4])) # print(all([1,2,3,None])) # print(all([1,2,3,''])) # print(any([True,None,False])) # print(any([False,None,False])) #拉链函数 # print(list(zip([0,1,2,3,4],[5,6,7,8],['a','b']))) #过滤函数 # def is_odd(x): # if x>10: # return True # ret = filter(is_odd, [1, 4, 6, 7, 9, 12, 17]) # print(list(ret)) # def is_odd(x): # if x%2 == 0: # return True # ret = filter(is_odd, [1, 4, 6, 7, 9, 12, 17]) # print(list(ret)) #filter就是有一个可迭代对象,想要一个新的内容集,是从原可迭代对象中筛选出来的 # def func(x): # #return x.strip() #‘ ’.strip() ==> '' ==> return False # # 'test'.strip() ==> 'test' # return x and x.strip() #None False and #去掉所有的空内容和字符串中的空格 # l = ['test', None, '', 'str', ' ', 'END'] # ret = filter(func,l) # print(list(ret)) #新内容少于等于原内容的时候,才能用到filter #新内容的个数等于原内容的个数 # ret = map(abs,[-1,-5,6,-7]) #abs(-1) = 1 abs(-5) = 5 # print(list(ret)) #filter和map #参数很相近:都是一个函数名+可迭代对象 #且返回值页很相近:都是返回可迭代对象 #区别 #filter是做筛选的,结果还是原来就在可迭代对象中的项 #map是对可迭代对象中的每一项做操作的,结果不一定是原来就在可迭代对象中的项 #有一个list, L = [1,2,3,4,5,6,7,8],我们要将f(x)=x^2作用于这个list上,那么我们可以使用map函数处理 # def func(x): # return x*x # ret = map(func,[1,2,3,4,5,6,7,8]) # print(list(ret)) #sort 是直接修改原列表的顺序,节省内存 #sorted 是生成一个新列表,不改变原来的列表 #key = func # print(sorted([-5,3,-4,2,-1],reverse=True)) # print(sorted([-5,3,-4,2,-1],key=abs)) # l2 = ['ajkhs',(1,2),'a',[1,2,3,4]] # print(sorted(l2,key=len,reverse=True)) # print(ascii('a')) # print(ascii(1))
匿名函数:
# def calc(n):return n**n # print(calc(10)) # cal = lambda n:n**n #lambda表达式、匿名函数 # cal = lambda: 1==2 #lambda表达式、匿名函数 # cal = lambda n: True if 1==2 else False #lambda表达式、匿名函数 # print(cal()) # def add(x,y):return x+y # add = lambda x,y:x+y # print(add(1,2)) # print(max([1,2,3,4,-5],key=abs)) # dic={'k1':10,'k2':100,'k3':30} # # print(max(dic.values())) # # print(max(dic)) # print(max(dic,key=lambda k:dic[k])) # def func(x): # return x*x # ret = map(lambda x:x*x,[1,2,3,4,5,6,7,8]) # print(list(ret)) # def func(num): # return num>99 and num<1000 ret = filter(lambda num: num>99 and num<1000,[1,4,6,823,67,23]) print(list(ret)) # def func(num): # if num > 10: # return True #return num>10 ret = filter(lambda num:num>10,[1,4,6,823,67,23]) ret = filter(lambda num:True if num>10 else False,[1,4,6,823,67,23]) print(list(ret)) #max min #map filter
这是一道经典题:关于lambda表达式加上列表生成式
def num(): return [lambda x:i*x for i in range(4)]
"""
这里的range(4)就是循环0,1,2,3到3截止,然后得到的是4个lambda函数,这个列表是列表生成式,这个生成式直接就把lambda函数对象返回给了这个列表里面,
所以我们得到的这个列表本身就是里面的for循环执行后的结果,那么这个for循环执行完这个i就是3,所以就得到下面的lambda表达式里面的i=3
[lambda x:3*x,lambda x:3*x,lambda x:3*x,lambda x:3*x]这里就是返回值,
一个列表,每一个列表中的元素都是一个lambda函数
""" print([m(2) for m in num()])这里也是一个列表生成式,里面的num()会先执行,就触发了我们上面的函数,得到返回值是一个列表,
列表里面是一个个lambda表达式的函数,
然后循环这个列表,把每一个函数进行传参调用,得到的就是我们上面的函数被调用加上参数的结果,就是lambda 2:2*3 结果就是6,
每一个lambda都是6这个结果,最终打印的结果是[6,6,6,6]
# 下面是对于面试题的拆分,拆分的是num()函数部分
def test_lambda_interview_subject():
"""
:return:
"""
li = [] # 这里初始化一个空list,对应上面num()函数返回的list
li_value = []
outer_i = None # 把循环中的变量i依次赋值给outer_i这个变量
for i in range(5):
outer_i = i
a = lambda: i+2
li.append(a) # 这里在li中存入的是lambda函数对象
li_value.append(a()) # 这里存入的是此时,在循环体中的lambda函数的返回值,这里作用域仅局限于range(5)这个循环体中
# 当你调用lambda函数的时候,上面的range(5)已经走完了,所以你拿到的i变量是4,
# 是最后一次循环的结果,所以lambda的参数就是4,有4个lambda函数,那么每个lambda函数的参数,就都是4
print("last-round>>>", outer_i, li[0]()) # 拿到outer_i这个变量此时的值,它就是lambda的参数
# li[0] == lambda: outer_i+2
for each_func in li:
print("each_func_value>>>", each_func())
for value in li_value:
print("value>>>", value)
return li # 把存入lambda对象的list返回
匿名函数进阶的面试题:
# d = lambda p:p*2 # t = lambda p:p*3 # x = 2 # x = d(x) #4 = d(2) # x = t(x) #12 = t(4) # x = d(x) #24 = d(12) # print(x) #2.现有两元组(('a'),('b')),(('c'),('d')), # 请使用python中匿名函数生成列表[{'a':'c'},{'b':'d'}] # t1 = (('a'),('b')) # t2 = (('c'),('d')) # t3 = zip(t1,t2) #[('a','c'),('b','d')] # print(list(map(lambda t:{t[0]:t[1]},[('a','c'),('b','d')]))) #3. def multipliers(): return (lambda x:i*x for i in range(4)) print([m(2) for m in multipliers()]) # i = 0 # m = lambda x:i*x # m(2) # i = 1 # m = lambda x:i*x # m(2)
这些面试题里面最后一道题太难了,需要加上注释,要周末的时候把它搞明白,然后把加了注释的版本贴上来。


























内置函数未完待续。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号