

day8数据类型补充,集合,深浅拷贝
思维导图:
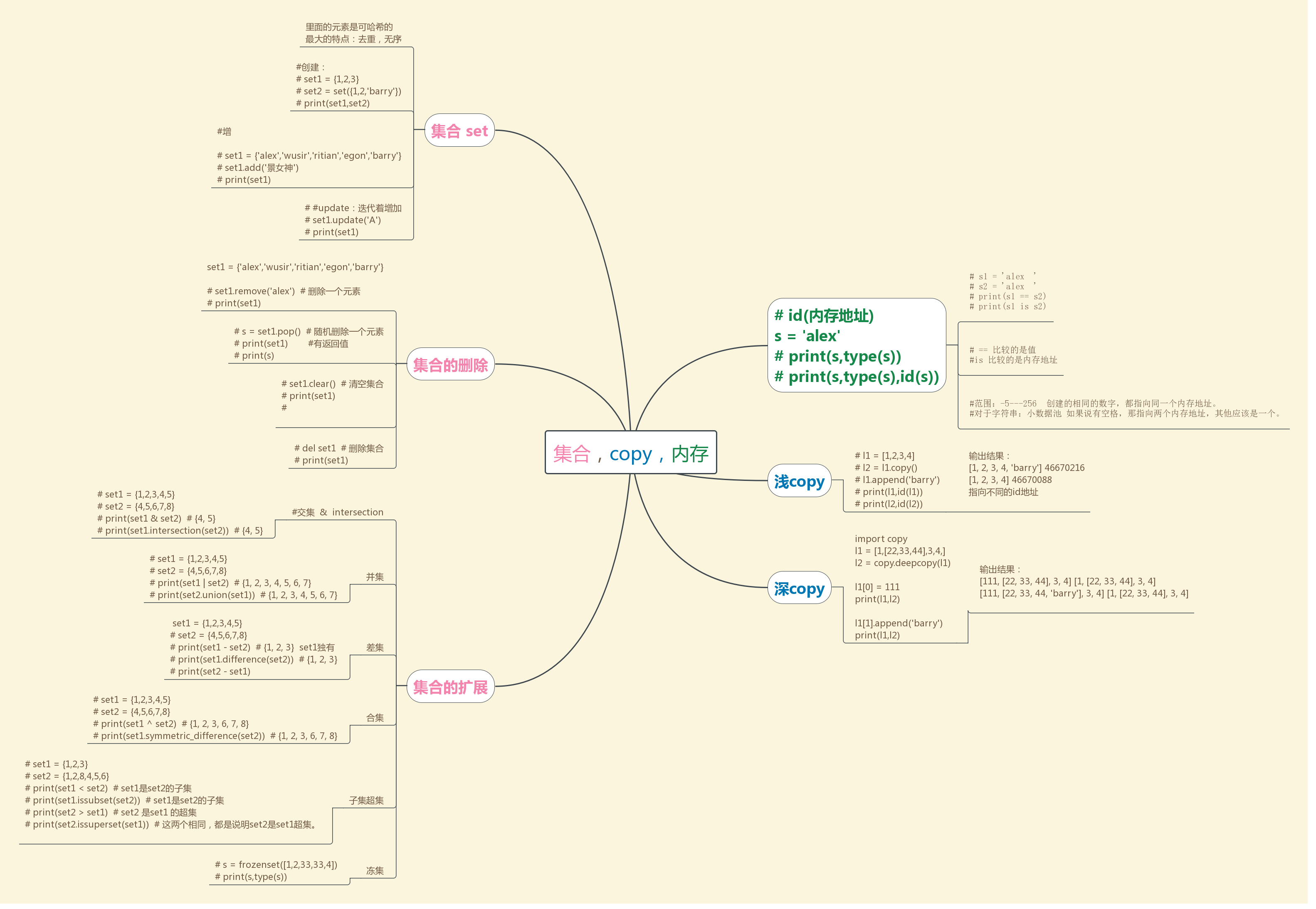
集合的补充:下面的思维导图有一个点搞错了,在这里纠正一下,没有合集,是反交集,^这个是反差集的意思 。
交集&,反交集^,差集-,并集|,然后就是子集和超集

数据类型补充:


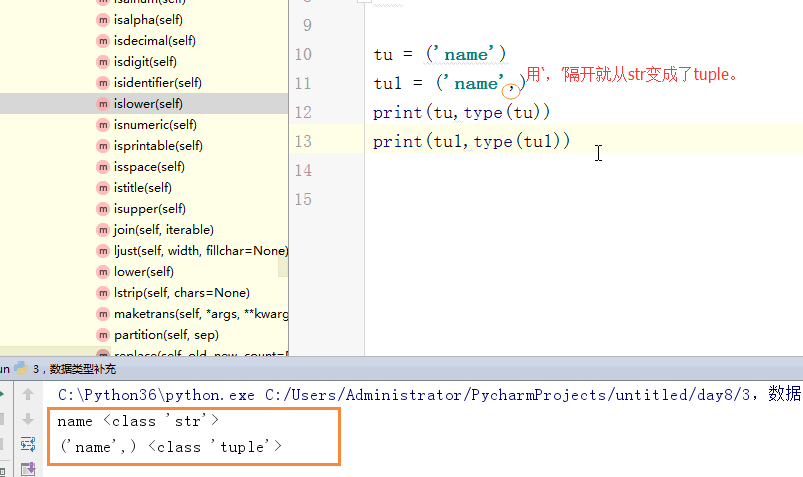
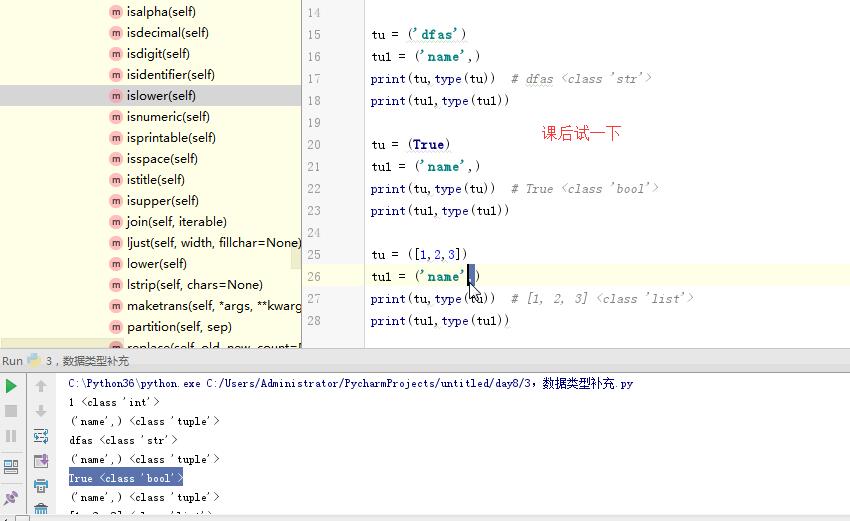
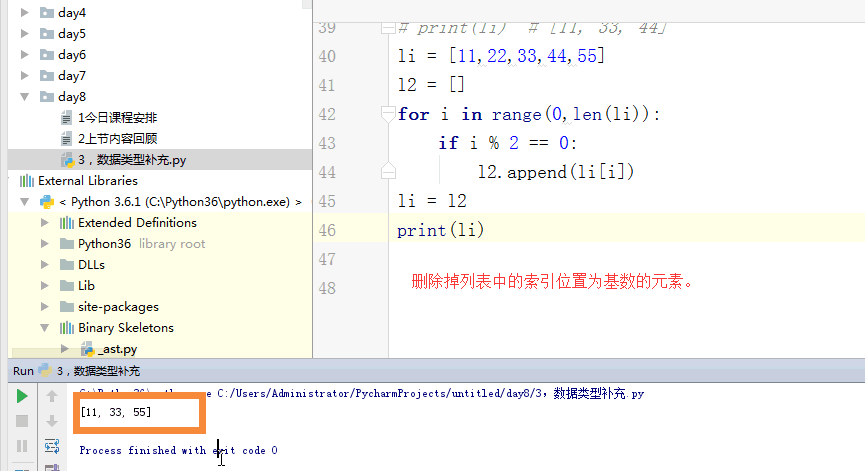
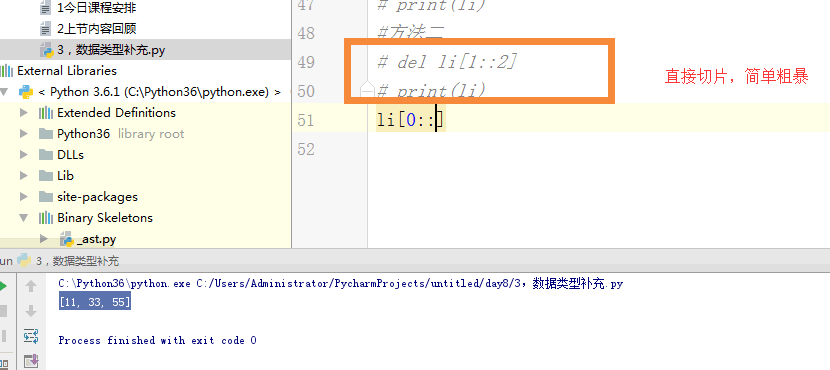
1 ''' 2 1,int 3 2,str 4 3,tuple 5 tu = (1) 6 tu1 = ('name',) 7 print(tu,type(tu)) # 1 <class 'int'> 8 print(tu1,type(tu1)) 9 10 tu = ('dfas') 11 tu1 = ('name',) 12 print(tu,type(tu)) # dfas <class 'str'> 13 print(tu1,type(tu1)) 14 15 tu = (True) 16 tu1 = ('name',) 17 print(tu,type(tu)) # True <class 'bool'> 18 print(tu1,type(tu1)) 19 20 tu = ([1,2,3]) 21 tu1 = ('name',) 22 print(tu,type(tu)) # [1, 2, 3] <class 'list'> 23 print(tu1,type(tu1)) 24 4,列表 25 当循环列表时,如果在循环中删除某个或者某些元素,列表元素个数改变,索引改变,容易出错。 26 27 5,字典 28 当循环字典时,如果在循环中删除某个或者某些键值对,字典的键值对个数改变,长度改变,容易出错。 29 30 转化: 31 1,int --> str :str(int) 32 2, str ---> int:int(str) 字符串必须全部由数字组成 33 3,bool ---> str:str(bool) 34 4,str ----> bool(str) 除了空字符串,剩下的都是True 35 5,int ---> bool 除了0,剩下的全是True 36 6,bool ---> int True ---> 1 False ----> 0 37 7,str ---> list split 38 8,list ---> str() join 39 9,元祖列表: 40 tu = (1,2,3) 41 l = list(tu) 42 print(l,type(l)) 43 44 li = [4,5,6] 45 print(tuple(li),type(tuple(li))) 46 47 #str ---> list 48 print(list('ab_c')) 49 50 #str ---> list 51 print(tuple('ab_c')) 52 53 # 0,"",{},[],(),set() ---->False 54 55 56 57 58 ''' 59 ''' 60 # li = [11,22,33,44,55] 61 # for i in range(0,len(li)): 62 # # i = 0 i= 1 i = 2 i = 3 63 # del li[li] 64 #li[22,33,44,55] li [22,44,55] li [22,44] 65 66 # for i in li: 67 # if li.index(i) % 2 == 1: # i = 11 i = 22 i = 44 68 # del li[li.index(i)] # li [11,22,33,44,55] li = [11,33,44,55] [11,33,44,55] 69 # print(li) # [11, 33, 44] 70 li = [11,22,33,44,55] 71 # 方法一 72 # l2 = [] 73 # for i in range(0,len(li)): 74 # if i % 2 == 0: 75 # l2.append(li[i]) 76 # li = l2 77 # print(li) 78 #方法二 79 # del li[1::2] 80 # print(li) 81 # li = li[0::2] 82 # print(li) 83 84 #方法三 85 # li = [11,22,33,44,55] 86 # for i in range(0,len(li)//2): 87 # # i = 0 # i = 1 88 # del li[i+1] 89 # # li = [11,33,44,55] li = [11,33,55] 90 # print(li) 91 92 # li = [11,22,33,44,55] 93 # # for i in range(len(li)-1,0,-1): 94 # # print(i) 95 # for i in range(len(li)-1,0,-1): 96 # if i % 2 == 1: 97 # del li[i] 98 # print(li) 99 ''' 100 # dic = dict.fromkeys([1,2,3],'杨杰') 101 # # dic1 = dict.fromkeys('abc','杨杰') 102 # print(dic) 103 # dic[4] = 'dfdsa' 104 105 # print(dic1) 106 # dic = dict.fromkeys(['barry','alex',],[]) 107 # dic['ritian'] = [] 108 # dic['barry'] = [] 109 # dic['barry'].append(11) 110 # print(dic) 111 112 113 dic = {'k1':'barry','k2':'alex','name':'ritian'} 114 ''' 115 # for i in dic: 116 # if 'k' in i: 117 # del dic[i] 118 # a = dic.keys() 119 # for i in list(a): 120 # if 'k' in i: 121 # del dic[i] 122 # print(dic) 123 ''' 124 # for i in dic: 125 # if 'k' in i: 126 # del dic[i] 127 # print(dic) 128 # for key in dic: 129 # print(key) 130 # li = [] 131 # for key in dic: 132 # li.append(key) 133 # print(li) 134 # for i in li: 135 # if 'k' in i: 136 # del dic[i] 137 # print(dic) 138 # lis = [] 139 # dic = {} 140 # i = 1 141 # dic["k1"] = i 142 # print("此时字典为%s:"%dic) 143 # lis.append(dic) 144 # print("此时列表为%s:"%lis) 145 # j = 2 146 # dic["k1"] = j 147 # print("此时字典为%s:"%dic) 148 # lis.append(dic) 149 # print("此时列表为%s:"%lis) 150 151 # tu = (1,2,3) 152 # l = list(tu) 153 # print(l,type(l)) 154 # 155 # li = [4,5,6] 156 # print(tuple(li),type(tuple(li))) 157 158 # #str ---> list 159 # print(list('ab_c')) 160 # 161 # #str ---> list 162 # print(tuple('ab_c')) 163 164 # 0,"",{},[],(),set() ---->False
今日内容梗概:
1,上节内容回顾 2,数据类型补充 3,集合。 4,深浅拷贝。
上节内容回顾:
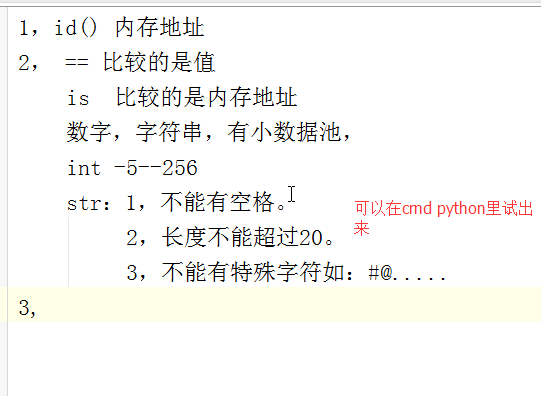
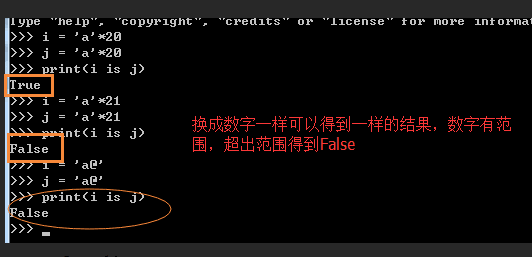
1,id() 内存地址 2, == 比较的是值 is 比较的是内存地址 数字,字符串,有小数据池, int -5--256 str:1,不能有空格。 2,长度不能超过20。 3,不能有特殊字符如:#@.....
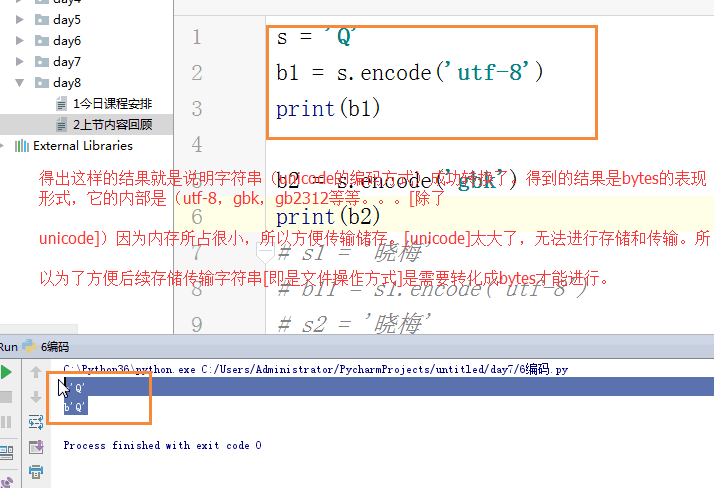
3,enmurate枚举 iterable: str,list,tuple,dict,set for i in enmurate(iterable): pirnt(i) for i in enmurate(['barry','alex']): pirnt(i) # (0,'barry') (1,'alex') for index,i in enmurate(['barry','alex']): pirnt(index,i) # 0,'barry' 1,'alex' for index,i in enmurate(['barry','alex'],100): pirnt(index,i) # 100,'barry' 101,'alex' 4,编码 py3: str:表现形式:s = 'alex' 实际编码方式:unicode bytes:表现形式:s = b'alex' 实际编码方式:utf-8,gbk,gb2312... s = b'\x2e\x2e\x2e\x2e\x2e\x2e' unicode:所有字符(无论英文,中文等) 1个字符:4个字节 gbk:一个字符,英文1个字节,中文两个字节。 utf-8:英文 1 个字节,欧洲:2个字节,亚洲:3个字节。
集合:
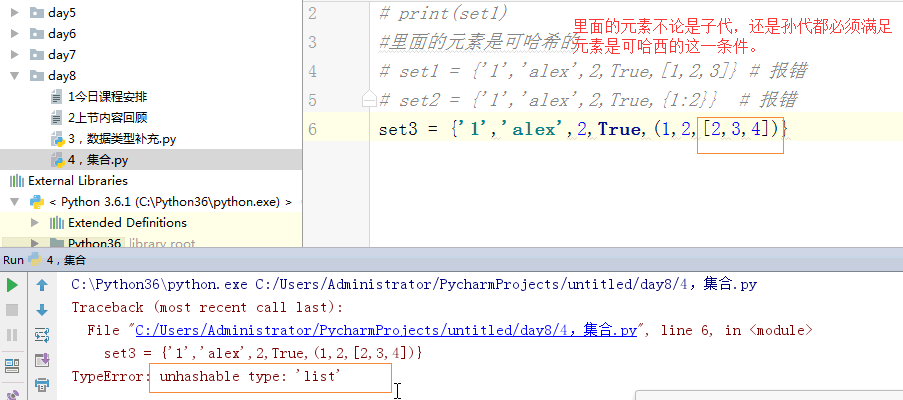
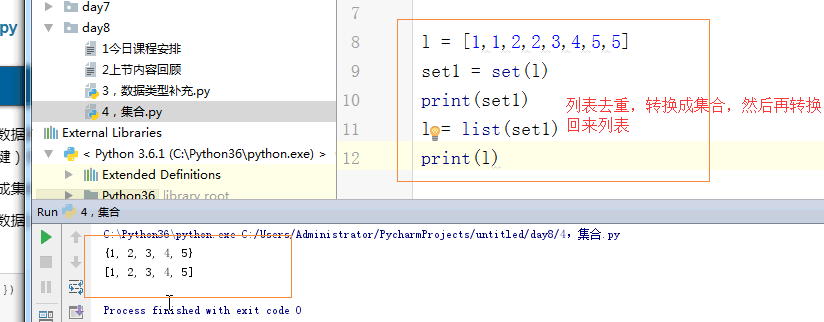
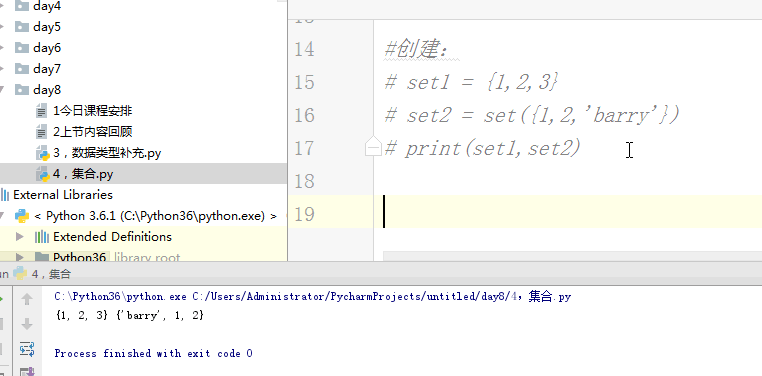
1 # set1 = {'1','alex',2,True,2,'alex'} 2 # print(set1) 3 #里面的元素是可哈希的 4 # set1 = {'1','alex',2,True,[1,2,3]} # 报错 5 # set2 = {'1','alex',2,True,{1:2}} # 报错 6 # set3 = {'1','alex',2,True,(1,2,[2,3,4])} # 报错 7 8 # l = [1,1,2,2,3,4,5,5] 9 # set1 = set(l) 10 # print(set1) 11 # l = list(set1) 12 # print(l) 13 14 #创建: 15 # set1 = {1,2,3} 16 # set2 = set({1,2,'barry'}) 17 # print(set1,set2) 18 19 #增 20 21 # set1 = {'alex','wusir','ritian','egon','barry'} 22 # set1.add('景女神') 23 # print(set1) 24 25 # #update:迭代着增加 26 # set1.update('A') 27 # print(set1) 28 # set1.update('老师') 29 # print(set1) 30 # set1.update([1,2,3]) 31 # print(set1) 32 33 34 # set1 = {'alex','wusir','ritian','egon','barry'} 35 36 # set1.remove('alex') # 删除一个元素 37 # print(set1) 38 39 # s = set1.pop() # 随机删除一个元素 有返回值 40 # print(set1) 41 # print(s) 42 # 43 # set1.clear() # 清空集合 44 # print(set1) 45 # 46 # del set1 # 删除集合 47 # print(set1) 48 49 # for i in set1: 50 # print(i) 51 # tu = () 52 # print(tu,type(tu)) 53 54 #交集 & intersection 55 # set1 = {1,2,3,4,5} 56 # set2 = {4,5,6,7,8} 57 # print(set1 & set2) # {4, 5} 58 # print(set1.intersection(set2)) # {4, 5} 59 60 # set1 = {1,2,3,4,5} 61 # set2 = {4,5,6,7,8} 62 # print(set1 | set2) # {1, 2, 3, 4, 5, 6, 7} 63 # print(set2.union(set1)) # {1, 2, 3, 4, 5, 6, 7} 64 65 # set1 = {1,2,3,4,5} 66 # set2 = {4,5,6,7,8} 67 # print(set1 - set2) # {1, 2, 3} set1独有 68 # print(set1.difference(set2)) # {1, 2, 3} 69 # print(set2 - set1) 70 71 # set1 = {1,2,3,4,5} 72 # set2 = {4,5,6,7,8} 73 # print(set1 ^ set2) # {1, 2, 3, 6, 7, 8} 74 # print(set1.symmetric_difference(set2)) # {1, 2, 3, 6, 7, 8} 75 # set1 = {1,2,3} 76 # set2 = {1,2,8,4,5,6} 77 # print(set1 < set2) # set1是set2的子集 78 # print(set1.issubset(set2)) # set1是set2的子集 79 # print(set2 > set1) # set2 是set1 的超集 80 # print(set2.issuperset(set1)) # 这两个相同,都是说明set2是set1超集。 81 82 # s = frozenset([1,2,33,33,4]) 83 # print(s,type(s))
集合的补充:之前的思维导图有一个点搞错了,在这里纠正一下,没有合集,是反交集,^这个是反差集的意思 。
交集&,反交集^,差集-,并集|,然后就是子集和超集
copy深浅:
1 # l1 = [1,2,3] 2 # l2 = l1 3 # l1.append('barry') 4 # print(l1) # [1,2,3,'barry'] 5 # print(l2) # [1,2,3] 6 7 # dic = {'name':'barry'} 8 # dic1 = dic 9 # dic['age'] = 18 10 # print(dic) 11 # print(dic1) 12 13 # s = 'alex' 14 # s1 = s 15 # s3 = s.replace('e','E') 16 # print(s) 17 # print(s1) 18 # print(s3) 19 # s = 'alex' 20 # s1 = s 21 # print(id(s),id(s1)) 22 # s = 'alex ' 23 # s1 = 'alex ' 24 # print(id(s),id(s1)) 25 26 # 浅copy 以list举例 27 # l1 = [1,2,3,4] 28 # l2 = l1.copy() 29 # l1.append('barry') 30 # print(l1,id(l1)) 31 # print(l2,id(l2)) 32 33 # l1 = [1,[22,33,44],3,4,] 34 # l2 = l1.copy() 35 # l1[1].append('55') 36 # # print(l1,id(l1),id(l1[1])) 37 # # print(l2,id(l2),id(l2[1])) 38 # l1[0] = 111 39 # print(l1,l2) 40 41 #深copy 42 import copy 43 l1 = [1,[22,33,44],3,4,] 44 l2 = copy.deepcopy(l1) 45 46 l1[0] = 111 47 print(l1,l2) 48 49 l1[1].append('barry') 50 print(l1,l2)
#深浅copy的区别是,浅copy的列表嵌,
从第一层开始,改变原本的,copy的那一份并不会变
从第二层的列表开始,改变原本的,copy的那一份也会跟着改变;
l = [1,2,3,[3,4]]
l1 = l.copy()
l[-1].append(8);
l.append(89)
print(l,l1)
输出结果是:[1, 2, 3, [3, 4, 8],89] [1, 2, 3, [3, 4, 8]]
#对于深copy来说,不论有几层的嵌套,随便改变里面的每一层,都不会影响原本的或者copy的那一份。
import copy
l = [1,2,3,[3,4]]
l1 = copy.deepcopy(l)
l[-1].append(8)
print(l,l1)
[1, 2, 3, [3, 4, 8]] [1, 2, 3, [3, 4]]
l1 = [1, 2, 3, ['barry', 'alex']]
# 浅copy
l2 = l1.copy()
# l1[3].append('b')
# l1.insert(l1[0], 'abs')
# print(l1, id(l1))
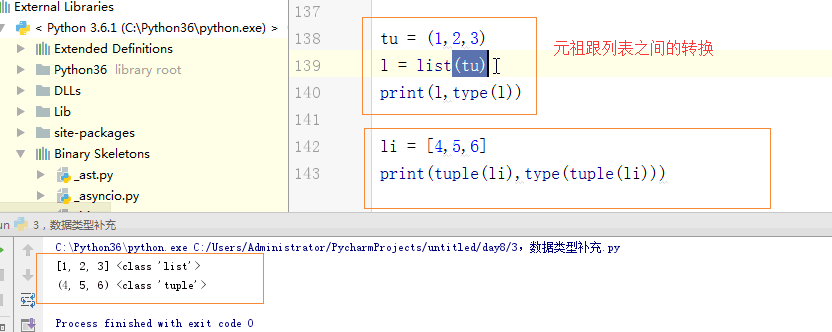
# print(l2, id(l2))
'''
[1, 2, 3, ['barry', 'alex', 'b']] 4367967368
[1, 2, 3, ['barry', 'alex', 'b']] 4367868680 l2是copy出来的,浅copy的时候,原来的内嵌列表改变,它也跟着变;
'''
'''
[1, 'abs', 2, 3, ['barry', 'alex']] 4367963272
[1, 2, 3, ['barry', 'alex']] 4367868680 原来的外层改变,它不变
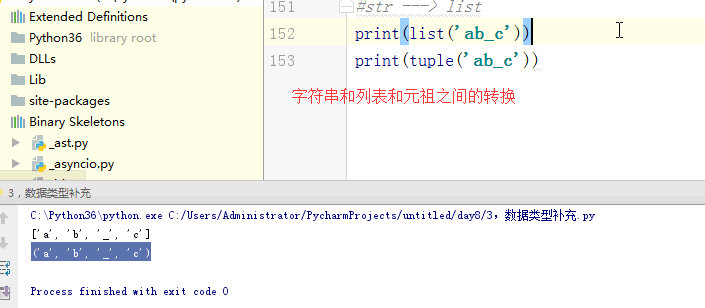
'''
# 深copy
l3 = copy.deepcopy(l1)
l1[3].append('bpo')
l1.append('bpo')
# print(l3,id(l3))
# print(l1,id(l1))
'''
[1, 2, 3, ['barry', 'alex']] 4368117640
[1, 2, 3, ['barry', 'alex', 'bpo'], 'bpo'] 4367967368 # 对于深copy来说,不论改变原来的哪一层,copy出来的都不会随之改变
'''
周末计划安排:
1,周六上午:整理知识点,+ 错题。 2,周六下午:小憩一下,做作业,看个电影。 3,周天上午:睡个懒觉,整理作业+预习。 4,周天下午:自由发挥。
周六作业: # 30、购物车 # 功能要求:要求用户输入总资产,例如:2000显示商品列表, 让用户根据序号选择商品,加入购物车购买,如果商品总额大于总资产,提示账户余额不足, 否则,购买成功。 # goods=[{"name":"电脑","price":1999}, {"name":"鼠标","price":10}, {"name":"游艇","price":20}, {"name":"美女","price":998}, ]
shopping_car = []
1 input(钱) 序号,商品,钱 序号选择:判断条件 深一步,你的 input(钱) 与 price":1999比较









 浙公网安备 33010602011771号
浙公网安备 33010602011771号