
day7 [id],[is],编码
老师的笔记:
字典:dic = {'name':'alex'} 1,增 dic['k'] = 'v' 有键值对,则覆盖 setdefault 有键值对,不添加 dic.setdefault('k1','v1') 可以 dic.setdefault('name','barry')
2,删 pop dic.pop('name') 有返回值,返回得是对应的值 dic.pop('k2',None) dic.popitem()随机删除 del dic['name'] del dic clear 清空
3,改 dic['name'] = 'v' dic = {'name':'alex'} dic2 = {'name':'barry','age':18} dic.update(dic2) print(dic) {'name':'barry','age':18} print(dic2) {'name':'barry','age':18} a,b = [1,2] print(a,b) # 1,2
a = 1 b = 2 a,b=b,a
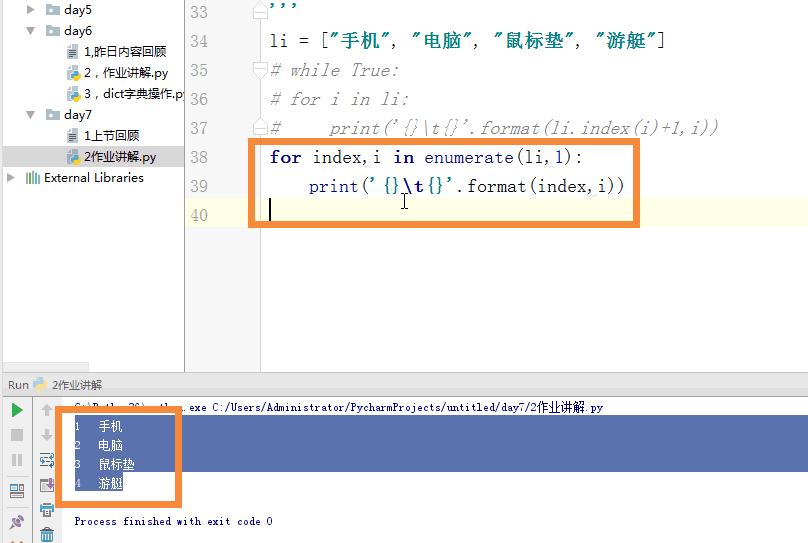
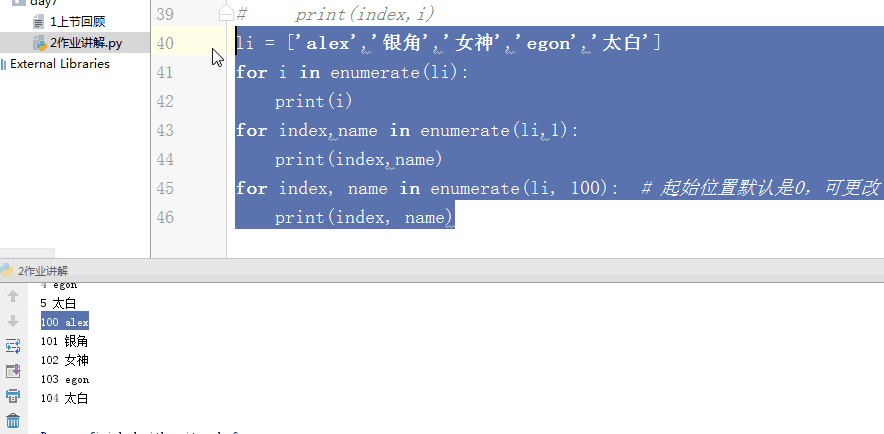
4,查 print(dic.keys()) print(dic.values()) print(dic.items()) # for k,v in dic.items(): #以上三个 都可以for循环 dic['name'] dic.get('name')
5,数据类型补充。
6,深浅拷贝。
7,文件操作。
今天的内容梗概:
1,上节回顾 2,作业讲解 3,id() (is == 区别) 4,编码。
py3: int
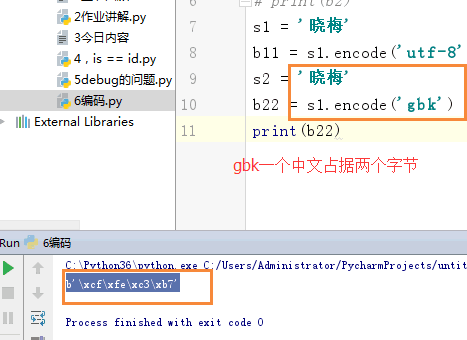
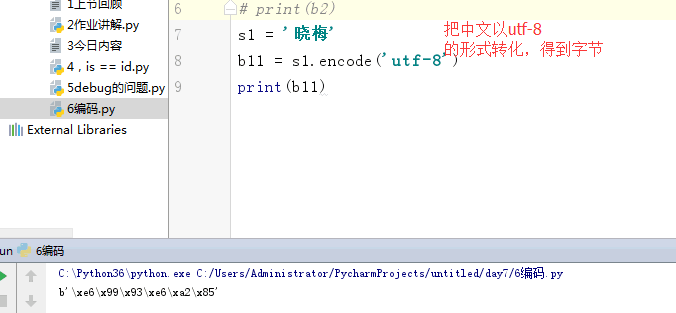
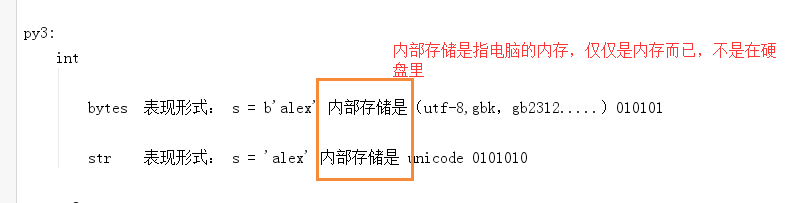
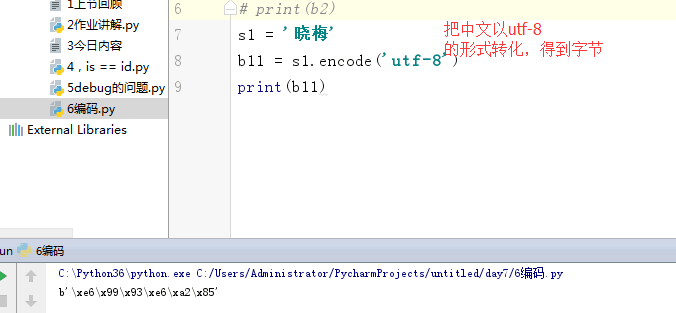
bytes 表现形式: s = b'alex' 内部存储是(utf-8,gbk,gb2312.....)010101 s1 = '晓梅' b11 = s1.encode('utf-8') 表现形式: s = b'\xe6\x99\x93\xe6\xa2\x85' (utf-8,gbk,gb2312.....)010101 0000 1000 0000 0000 0000 0001 0000 1001 0000 0000 0000 0001 s2 = '晓梅' b22 = s1.encode('gbk') print(b22) b'\xcf\xfe\xc3\xb7' 表现形式: s = b'\xcf\xfe\xc3\xb7' (utf-8,gbk,gb2312.....)010101 0000 1000 0000 0000 0000 0001 0000 1001 str 表现形式: s = 'alex' 内部存储是 unicode 0101010
py3: unicode A :00000000 00000000 00000000 00001001 四个字节 中 :00000000 00001000 00000000 00000001 四个字节
utf-8 A :00000001 一个字节 欧洲@ : 00000010 00000001 两个字节 亚洲 中 : 00001000 00000000 00000001 三个字节 中国:00001000 00000000 00000001 00001001 00000000 00000001
gbk A :00000000 00001001 两个字节 中 :00000000 00100001 两个字节 不同的编码之间是不能相互识别,会产生乱码。
存储,传输的:utf-8,或者 gbk,或者是gb2312,或者是其他(绝对不是unicode)。
......
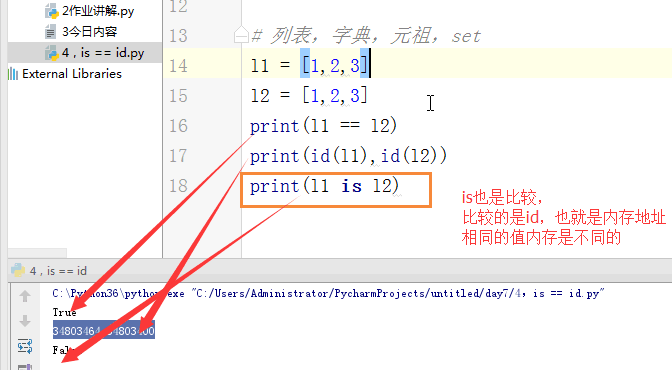
bool list tuple dict
set
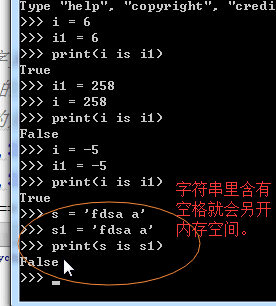
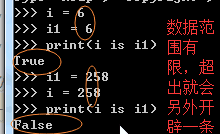
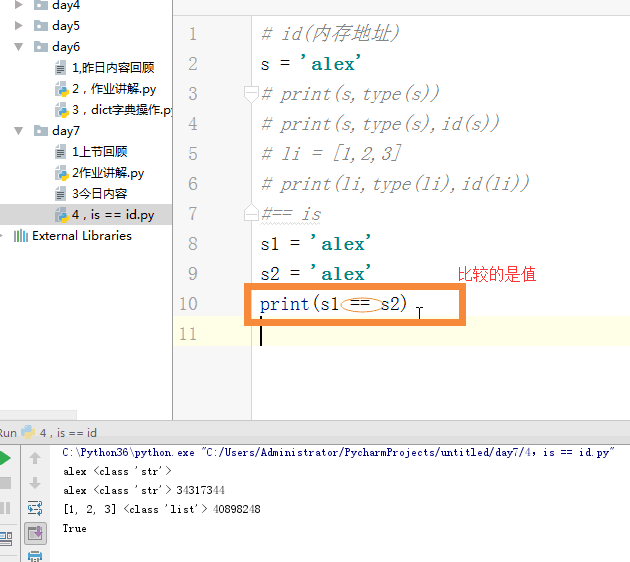
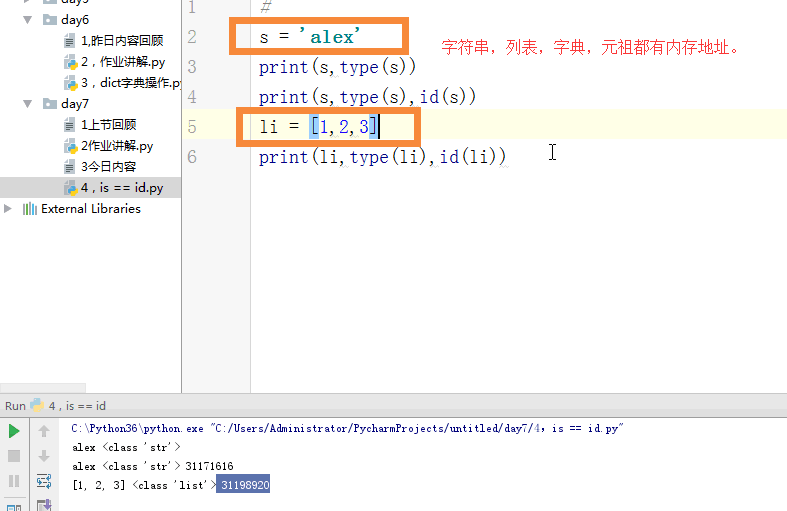
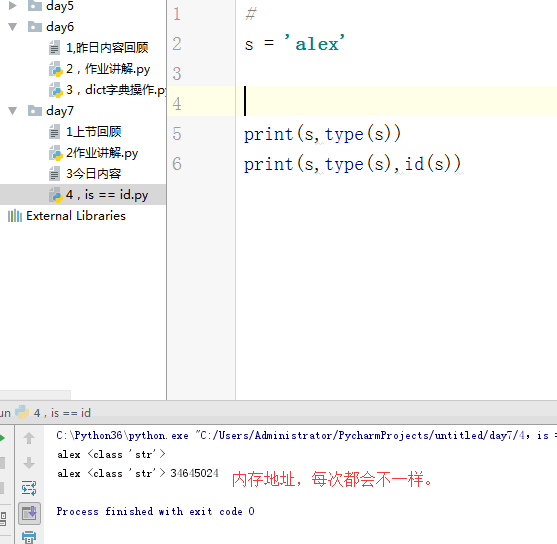
is=id


1 # id(内存地址) 2 s = 'alex' 3 # print(s,type(s)) 4 # print(s,type(s),id(s)) 5 # li = [1,2,3] 6 # print(li,type(li),id(li)) 7 #== is 8 # s1 = 'alex ' 9 # s2 = 'alex ' 10 # print(s1 == s2) 11 # print(s1 is s2) 12 #对于int 小数据池 13 #范围:-5---256 创建的相同的数字,都指向同一个内存地址。 14 #对于字符串:小数据池 如果说有空格,那指向两个内存地址,其他应该是一个。 15 16 17 # 列表,字典,元祖,set 18 # == 比较的是值 19 #is 比较的是内存地址 20 l1 = [1,] 21 l2 = [1,] 22 print(l1 == l2) # True 23 print(id(l1),id(l2)) 24 print(l1 is l2) #False
编码
1 s = 'Q' 2 # b1 = s.encode('utf-8') 3 # print(b1) 4 # 5 # b2 = s.encode('gbk') 6 # print(b2) 7 s1 = '晓梅' 8 b11 = s1.encode('utf-8') 9 s2 = '晓梅' 10 b22 = s1.encode('gbk') 11 print(b22)










 浙公网安备 33010602011771号
浙公网安备 33010602011771号