pandas-数据结构转换-纵转横
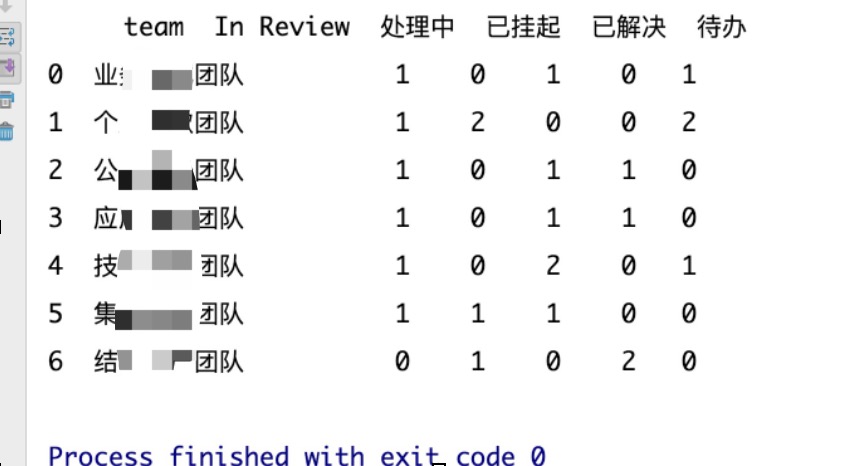
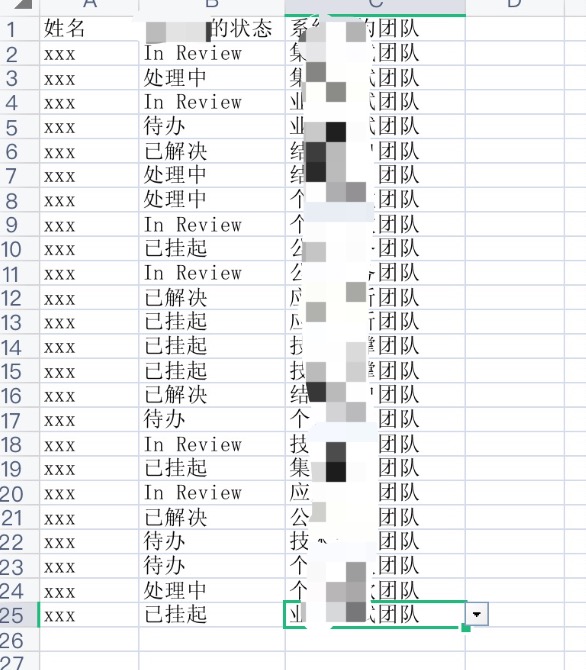
如下代码,亲测有效,后面会附上入口以及出口数据结构截图
def test_func(file_path): """ 把pandas数据结构-dataframe,横向的索引,转成纵向的 :return: """ pd_obj = pandas.read_excel(file_path, engine="openpyxl") groupby_df = pd_obj.groupby(["任务状态", "团队名称"]).agg( {"团队名称": "count"} ) # 拿到分组后,第一层数据,团队名称字典下面的value sys_team = groupby_df.get("团队名称") # 二次分组,拿到每个任务状态下的所有团队名称数据 sys_team_type_df = sys_team.groupby("任务状态") li = [] for name, group_ in sys_team_type_df: # 拿到每个分组的数据,每个分组就是每个任务状态下的所有团队名称数据 each_group_dic = {"team": [], } # 拿到每个分组的索引list,每个list里面是一个个tuple, # 每个tuple---('In Review', 'A团队') each_group_index_li = group_.index type_li = [] for each_index_row in each_group_index_li: # 拿到每个tuple中,任务状态值以及团队名称值 current_team_value = each_index_row[-1] current_type_value = each_index_row[0] # 把每个group里面的团队名称,按照顺序,添加到字典的team里面 each_group_dic["team"].append(current_team_value) # 把每个分组中的具体count值,提取出来,根据二维索引提取, # 二维索引就是任务状态索引和团队名称索引 type_team_matched_value = group_.loc[current_type_value, current_team_value] # 把每个分组中提取出来的具体的count值,存入一个type-list type_li.append(type_team_matched_value) # 把type-list,作为一组键值对:key是团队名称,value是该团队对应的count值, # update到上面构件的each_group_dic字典中, each_group_dic.update({current_type_value: type_li}) # 把构件完成的each_group_dic字典,转成dataframe数据结构 each_group_df = pandas.DataFrame(each_group_dic) # 把每个分组构件完成的dataframe,存入一个list中 li.append(each_group_df) # 最后把最外层的list里面的所有dataframe拼接起来,得到转换成功的数据结构 merge_test_df = reduce( lambda left, right: pandas.merge(left, right, on="team", how="outer"), li) # 把dataframe的空值都填充为0 df_ = merge_test_df.fillna(0) # 拿到所有应该要转换成数字的列名 integer_cols = merge_test_df.columns[1:] for each_col in integer_cols: # 把所有float类型的列,都转换成数字 df_[each_col] = pandas.to_numeric(df_[each_col], downcast='integer') return df_
输入的文件结构如下截图:
输出的结构截图: