【数据挖掘学习笔记】第三章数据预处理
一、为什么需要数据预处理?

二、数据预处理的主要任务
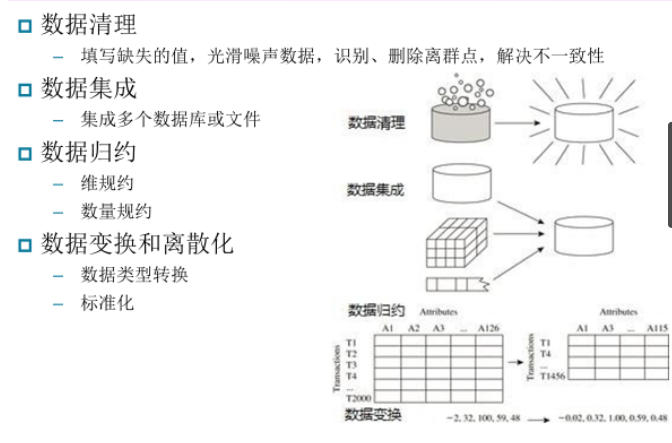
(1)数据清理

——缺失数据

——如何处理缺失数据?

——异常数据

离群点
——回归:让数据适应回归函数来平滑数据
——聚类:通过聚类来检测并删除离群点
(2)数据转换
——数据变换:①类型转换 ②采样 ③标准化
——属性类别:①连续的 (例:实值:温度,高度,宽度)
②离散的(整数值:有多少人)
③序数的(排名:{矮,中,高})
④标称的(职业:{老师,工人,销售员},颜色:{红,绿,蓝})
⑤字符串(非结构化)
——离散化:离散化是将连续属性转化成有序属性的过程
—应用于分类和关联任务中
—离散化涉及2个子任务:
①通过指定n-1个分割点,划分为n个区间;
②将一个区间中的所有值都映射到相同的分类值。
主要:决定选择多少个分割点,以及确定分割点的位置。
—根据是否使用类信息,分为:

——采样

——标准化:
—最大-最小标准化(Min-max)标准化: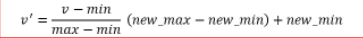
—Z-score标准化:
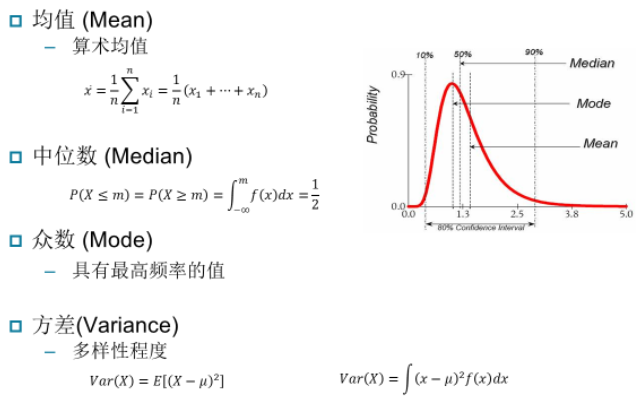
(3)数据统计描述和可视化:
——数据描述的统计量:

(4)特征选取与提取
为什么要进行特征选择? ——避免维度灾难
如何判断属性好坏?
——类别分别图:定性判断连续属性好不好
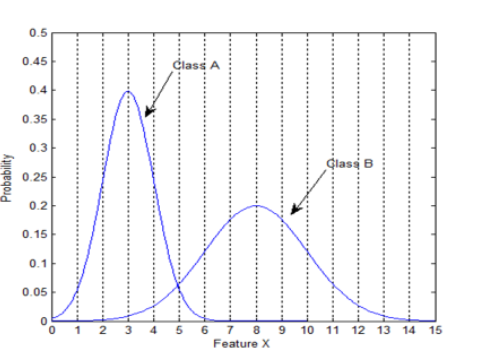
——类别柱状图:定性判断离散属性好不好
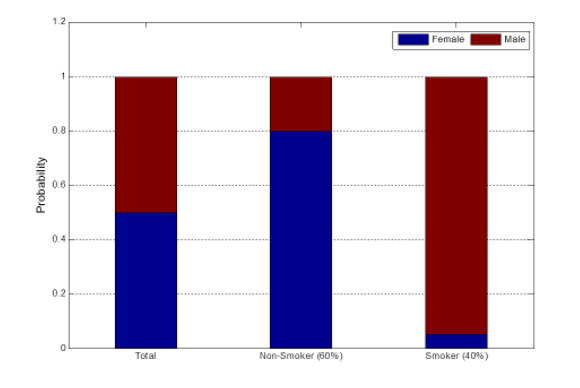
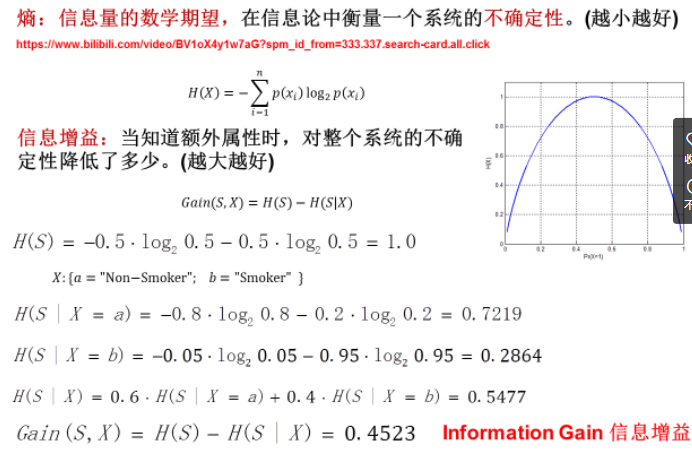
——熵:定量判断属性的好坏
——特征子集寻找
—穷举: 将所有可能的组合combinations
—分枝定界法
特征提取:
——主成分分析:同一物体,降到低维空间中,都会存在信息损失。但从不同角度映射,丢失的信息将不同。
目标:使信息损失最少
PCA(无监督方法):将原始的数据投影到特征向量上,对应的特征值最大的特征向量上。
——线性判别分析:给定一组点x1,x2,…,xn.所有可能的投影y=wTx,关键需要找到最大的具有可分性的投影。 ![]()
目标:保持尽可能多的类别信息的同时进行降维。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号