数字挖掘学习笔记
数字挖掘的的四大主要任务:
①分类 /回归 ②聚类 ③关联规则 ④异常检测
什么是分类?
分类:根据一组对象和其类标签,构建分类模型,并用于预测另一组对象的类别标签(有监督方法)。
什么是聚类?
聚类:将一组样本分配到一个子集(簇),这样同一簇中的样本在某种意义上是相似的(无监督方法)。通常作为其他数字挖掘或建模的前奏
分类边界 : 特征空间中的一个特征表达


过拟合:对某一类的特征过于细化,表现过好,这样模型就会缺少泛化能力,不能够很好地适用于其他特征过于特征化;
欠拟合:模型表现太差,可能是获取地特征太少,模型无法很好地匹配,存在理解不够透彻这样的一种状态
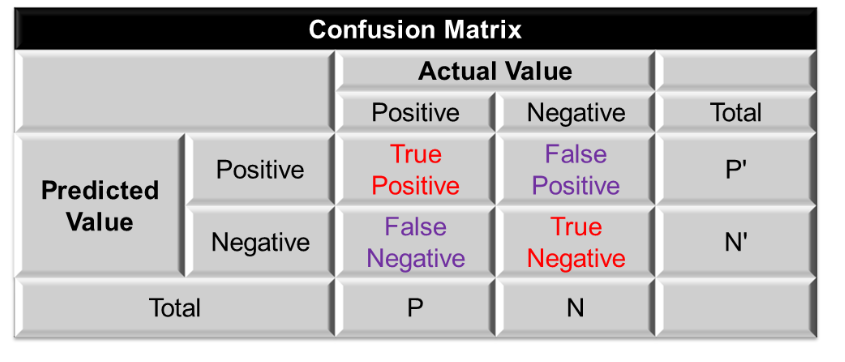
混淆矩阵:
![]() 0
0
 0
0
- 混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;
- 每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目;每一列中的数值表示真实数据被预测为该类的数目。
True Positive(TP):真正类。样本的真实类别是正类,并且模型识别的结果也是正类。
False Negative(FN):假负类。样本的真实类别是正类,但是模型将其识别为负类。
False Positive(FP):假正类。样本的真实类别是负类,但是模型将其识别为正类。
True Negative(TN):真负类。样本的真实类别是负类,并且模型将其识别为负类。
TPR:true positive rate,描述识别出的所有正例占所有正例的比例
计算公式为:TPR=TP/ (TP+ FN
TNR:true negative rate,描述识别出的负例占所有负例的比例
计算公式为:TNR= TN / (FP + TN)
精确率(Accuracy):精确率是最常用的分类性能指标。可以用来表示模型的精度,即模型识别正确的个数/样本的总个数。一般情况下,模型的精度越高,说明模型的效果越好。
Accuracy = (TP+TN)/(TP+FN+FP+TN)
ROC曲线/AUC评价标准
在正式介绍ROC/AUC之前,我们还要再介绍两个指标,这两个指标的选择也正是ROC和AUC可以无视样本不平衡的原因。这两个指标分别是:灵敏度和(1-特异度),也叫做真正率(TPR)和假正率(FPR)。
灵敏度(Sensitivity) = TP/(TP+FN)
特异度(Specificity) = TN/(FP+TN)
其实我们可以发现灵敏度和召回率是一模一样的,只是名字换了而已。
由于我们比较关心正样本,所以需要查看有多少负样本被错误地预测为正样本,所以使用(1-特异度),而不是特异度。
真正率(TPR) = 灵敏度 = TP/(TP+FN)
假正率(FPR) = 1- 特异度 = FP/(FP+TN)
代价敏感学习
代价敏感的学习是分类中错误产生导致不同的惩罚力度时该如何训练分类器。
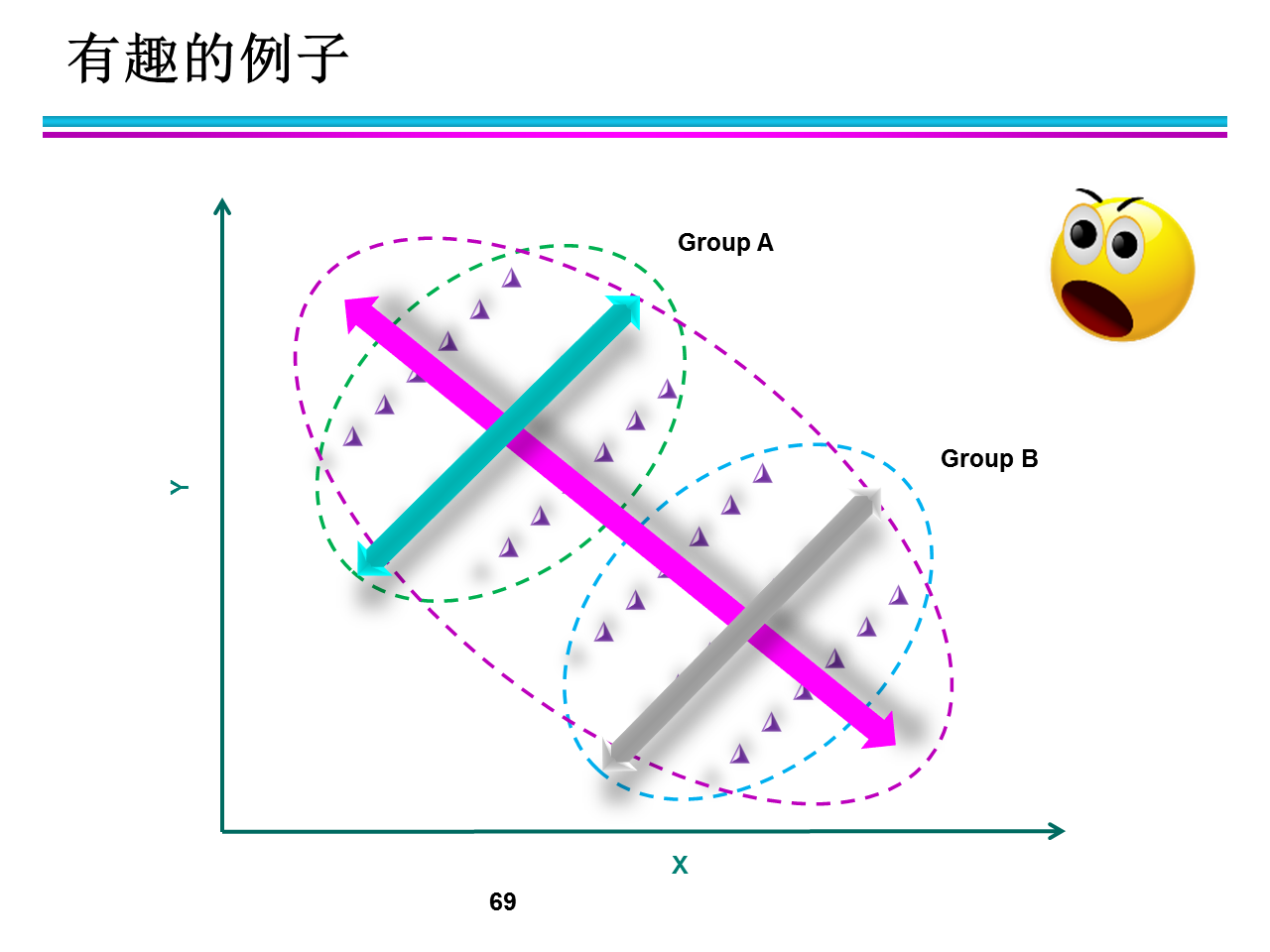
若x为户外运动时间 y为身体状况 Group A 可看作年轻人 Group B可看作老年人的 特征曲线。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号