
Python爬虫爬取北京空气质量数据并分析
一.选题背景
空气质量(Air quality)是依据空气中污染物浓度的高低来判断的,其好坏反映了空气污染程度。空气污染是一个复杂的现象,在特定时间和地点空气污染物浓度受到许多因素影响。空气质量不达标的危害有很多,例如1、危害人体:当大气中污染物的浓度很高时,会造成人体急性污染中毒,或使病状恶化,甚至在几天内夺去几千人的生命。2、对植物的危害:当污染物浓度很高时,会对植物产生急性危害,使植物叶表面产生伤斑,导致枝叶枯萎脱落;3、影响气候:空气污染会减少阳光到达地面的太阳辐射量,增加大气降水量,同时也会增加下酸雨的机率,而酸雨能使大片森林和农作物毁坏,能使纸品、纺织品、皮革制品等腐蚀破碎,能使金属的防锈涂料变质而降低保护作用,还会腐蚀污染建筑物。
二.大数据分析设计方案
从网址中爬取完数据后,在python环境中导入pandas、plotly等库进行数据整理,经过数据清洗,检查数据等,然后进行可视化处理,找到空气质量的关系完成数据分析。
数据来源:'http://tianqihoubao.com/aqi/beijing-{year}0{month}.html'
思路:对数据集进行分析,进行数据清洗,根据所需内容对数据进行可视化最后得到图像并分析结果。
三.大数据分析步骤
爬取网站生成csv文件的过程。
import csv import random import time import pandas as pd import requests from bs4 import BeautifulSoup import matplotlib.pyplot as plt plt.rcParams["font.sans-serif"] = ["SimHei"] plt.rcParams["axes.unicode_minus"] = False class Spider(object): def __init__(self): pass def get_data_and_save(self): with open('data.csv', 'w', encoding='utf-8', newline='') as f: csv_writer = csv.writer(f) csv_writer.writerow(['日期', '质量等级', 'AQI指数', '当天AQI排名', 'PM2.5', 'PM10', 'So2', 'No2', 'Co', 'O3']) years = [2020, 2021, 2022] #2020年到2022年 months = range(1, 13) #1月到12月 for year in years: for month in months: if month < 10: url = f'http://tianqihoubao.com/aqi/beijing-{year}0{month}.html' else: url = f'http://tianqihoubao.com/aqi/beijing-{year}{month}.html' res = requests.get(url).text soup = BeautifulSoup(res, 'html.parser') for attr in soup.find_all('tr')[1:]: one_day_data = list() for index in range(0, 10): one_day_data.append(attr.find_all('td')[index].get_text().strip()) csv_writer.writerow(one_day_data) time.sleep(2 + random.random()) print(year, month) def drawing(self): csv_df = pd.read_csv('data.csv', encoding='GBK') csv_df['日期'] = pd.to_datetime(csv_df['日期']) csv_df.index = csv_df['日期'] del csv_df['日期'] str_data = '2020-01-01' end_data = '2020-01-31' new_split_df = csv_df[str_data:end_data] values_count = new_split_df['质量等级'].value_counts().items() total = new_split_df['质量等级'].value_counts().tolist() label = new_split_df['质量等级'].value_counts().index explode = [0.01 for i in range(len(total))] fig, axes = plt.subplots(3, 1, figsize=(10, 8)) if __name__ == '__main__': spider = Spider() # 获取数据,保存数据 spider.get_data_and_save() # 画分析图
spider.drawing()
运行结果:
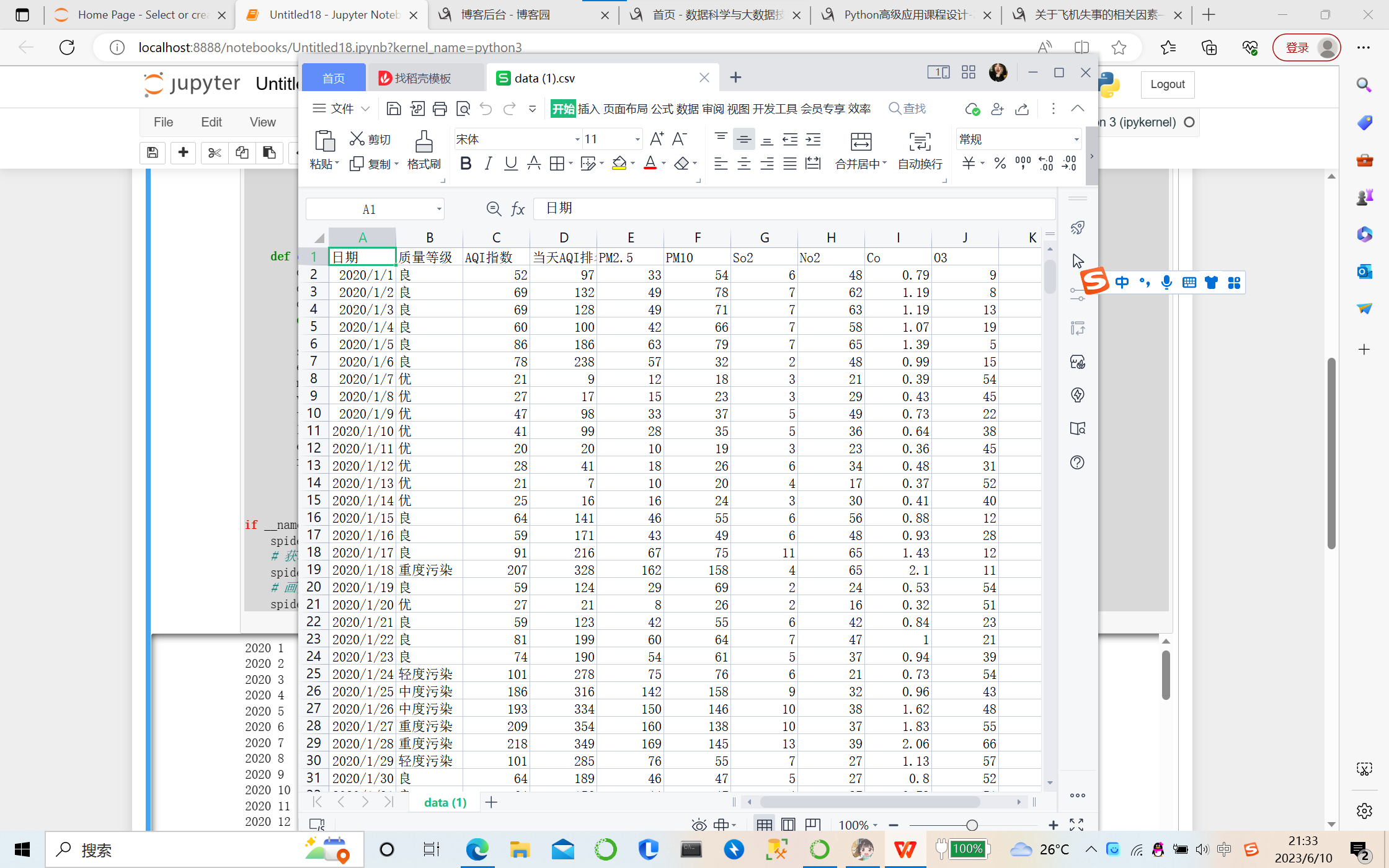
数据清洗
①导入相应模块以及数据集
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
df=pd.read_csv('data.csv')
df

②处理缺失值
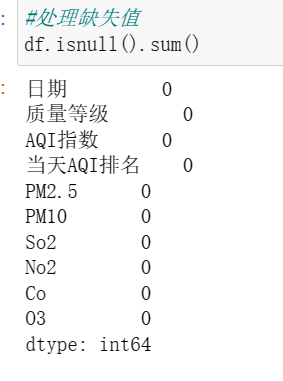
发现无缺失值
③重复值处理
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
df=pd.read_csv('data.csv')
#重复值处理
df=df.drop_duplicates()
df
④清除空值
import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt df=pd.read_csv('data.csv') #清除空值 datas = df.dropna() display(datas)
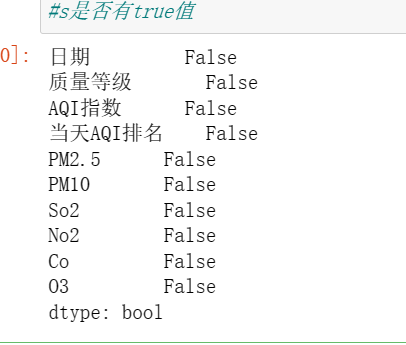
⑤查看是有有true
import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt df=pd.read_csv('data.csv') df.isna().any() #s是否有true值
数据分析与数据可视化:
字典统计法:
# Author:xueling # 先打开一篇我们要统计的文章,并读取内容 f = open(r'data.csv', 'r', encoding='utf-8') article = f.read() # 建立一个空字典来存储统计结果 d = {} # 遍历整篇文章 for i in article: d[i] = d.get(i,0) + 1 # 字频统计 # 在此基础上我们还可以做一个排序: ls = sorted(list(d.items()), key= lambda x:x[1], reverse=True) print(d) f.close()

哈希表统计法
# Author:xueling # 在colletions 导入哈希表的包 from collections import defaultdict # 打开一个要统计的文件 f = open(r'data.csv', 'r', encoding='utf-8') article = f.read() # d是通过defaultdict生成的一个哈希表,其中value我们给int型的数据类型,来记录字符数 d = defaultdict(int) # article里每一个字我们把它当做哈希表里的key,每有一个字就给value + 1,value默认值就是0 for key in article: d[key] += 1 print(d)

数据分类
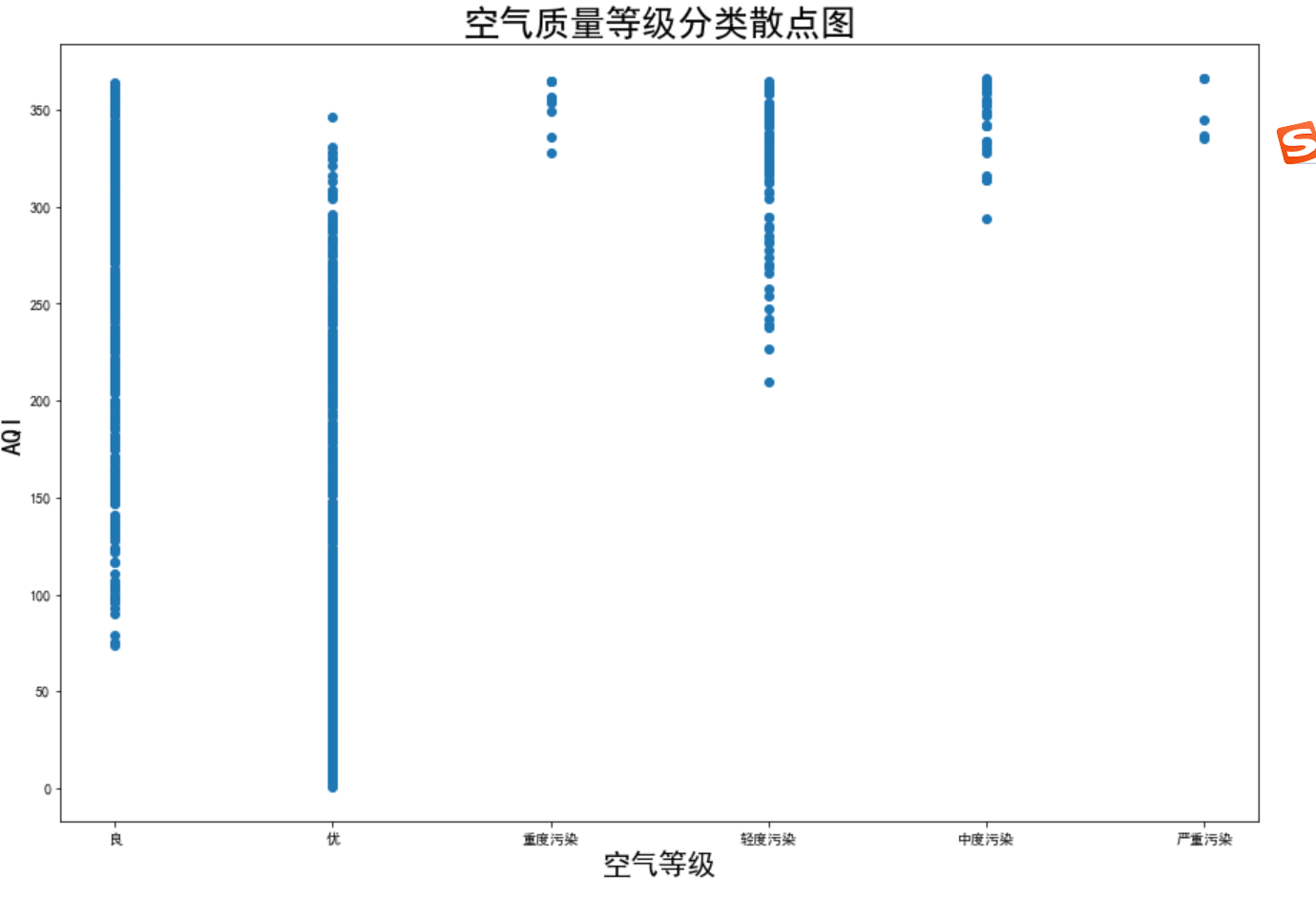
绘制AQI与PM2.5的关系散点图
import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt df=pd.read_csv('data.csv') #绘制 aqi 和 pm2.5 的关系散点图 # 设置图像尺寸 plt.figure(figsize=(15, 10)) # 绘制散点图,横坐标为aqi数据的第二列,纵坐标为aqi数据的第四列 plt.scatter(df[df.columns[1]], df[df.columns[3]]) # 设置横轴标签为'AQI',字体大小为20 plt.xlabel('空气等级', fontsize=20) # 设置纵轴标签为'PM2.5',字体大小为20 plt.ylabel('AQI', fontsize=20) # 设置图像标题为'AQI和PM2.5的关系散点图',字体大小为25 plt.title('空气质量等级分类散点图', fontsize=25) # 显示图像 plt.show()
绘制空气等级质量的单变量分布图
import pandas as pd import numpy as np import seaborn as sns import seaborn as sn import matplotlib.pyplot as plt df=pd.read_csv('data.csv') # 绘制空气质量等级单变量分布图 # 绘制以第三列为 x 轴,数据来源为 aqi 的计数图 sn.countplot(x=df.columns[2], data=df) # 设置标题为“空气质量等级单变量分布图” plt.title("空气质量等级单变量分布图") # 设置 x 轴标签为“质量等级” plt.xlabel("质量等级") # 设置 y 轴标签为“aqi” plt.ylabel("aqi") # 显示图像 plt.show()
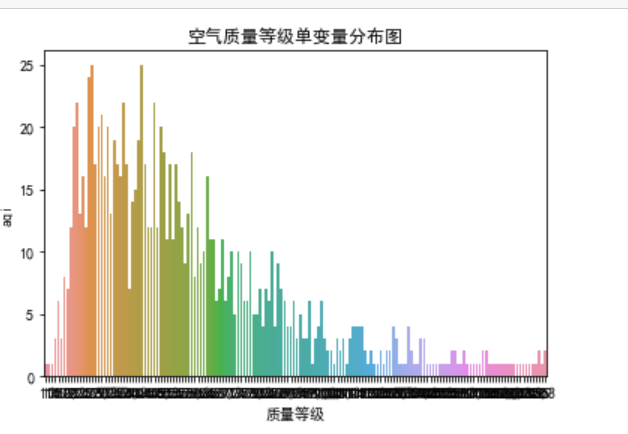
可知,AQI指数越高,空气质量越差。
制作2020-2022年空气质量饼图
import numpy as np import pandas as pd import matplotlib import matplotlib.pyplot as plt # 读文件,去无用字段 bj_date = pd.read_csv('data.csv') # print(bj_date.head(30)) # 数据清洗 #bj_date.drop(bj_date[np.isnan(bj_date['PM_US Post'])].index, inplace=True) # 空气质量定级 def get_level(AQI指数): if AQI指数 < 35: return '优' elif AQI指数 < 75: return '良' elif AQI指数 < 150: return '轻度污染' elif AQI指数 < 250: return '中度污染' elif AQI指数 >= 250: return '高度污染' # 给原始数据添加新列表level bj_date.loc[:, 'level'] = bj_date['AQI指数'].apply(get_level) print(bj_date) # 统计各种空气质量的比列 bj_level=bj_date.groupby(['level']).size() / len(bj_date) print(bj_level) #画图 matplotlib.rcParams['font.sans-serif'] = 'SimHei' l=['中度污染','优','良','轻度污染','高度污染'] plt.pie(bj_level,labels=l,autopct='%.2f%%') plt.title('北京空气质量指数') plt.show()

这三年中,优良空气占比高。
绘制PM2.5与AQI的线性回归图
import pandas as pd import numpy as np import seaborn as sns import seaborn as sn import matplotlib.pyplot as plt df=pd.read_csv('data.csv') # 绘制PM2.5与AQI的线性回归拟合图 # 调用seaborn库的regplot函数,将PM2.5含量(ppm)作为x轴,AQI作为y轴,数据源为aqi sn.regplot(x='PM2.5', y='AQI指数', data=df) # 设定图表标题为 'PM2.5与AQI的线性回归拟合图' plt.title('PM2.5与AQI的线性回归拟合图') # 设定图表x轴标签为'PM2.5含量(ppm)' plt.xlabel('PM2.5含量(ppm)') # 设定图表y轴标签为'AQI' plt.ylabel('AQI') # 显示图表 plt.show()
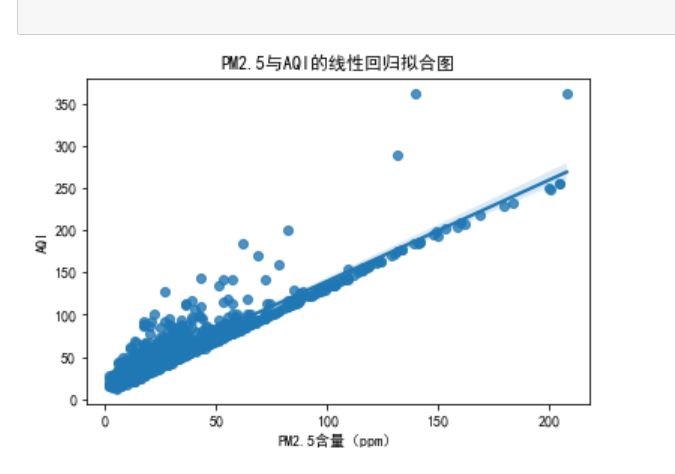
可以看出,AQI排放量与PM2.5成正比,AQI排放越高PM2.5指数越大,空气越差。
绘制各污染物之间的特征相关性热力分布图
import pandas as pd import numpy as np import seaborn as sns import seaborn as sn import matplotlib.pyplot as plt df=pd.read_csv('data.csv') # 绘制特征相关性热力图 # 设置画布大小 plt.figure(figsize=(17, 14)) # 计算相关系数并赋值给变量 corr corr = df[['AQI指数', 'PM2.5', 'PM10', 'So2', 'Co', 'No2', 'O3']].corr() # 以热图的形式展示相关性,并用蓝红色调表示,同时在每个方格中显示数值,并设置线宽为1 sn.heatmap(corr, cmap='RdBu_r', annot=True, linewidths=1) # 设置热图的标题,并设置字体大小为25 plt.title("各污染物之间的特征相关性热力分布图", fontsize=25) # 设置x轴标签字体大小为15 plt.xticks(fontsize=15) # 设置y轴标签字体大小为15 plt.yticks(fontsize=15) # 展示画布 plt.show()

绘制每日So2与AQI排放量的条形图
# 打开清洗后的数据文件'data.csv' import pandas as pd df_new = pd.read_csv('data.csv') df_new import matplotlib.pyplot as plt #导入matplotlib库中的pyplot模块,pyplot是用于创建图表的主要函数 df_new['当天AQI排名'].value_counts().nlargest(10).plot.bar(figsize=(14,6),fontsize= 13) plt.title('柱形图',fontsize= 20) plt.xlabel('AQI',fontsize= 16) plt.xticks(rotation=0) #设置X轴刻度标签的旋转角度。xticks是指X轴上的刻度,rotation参数指定刻度标签的旋转度数,0表示不旋转。若刻度标签内容过长,旋转角度可以调整为其他角度,以便更好地展示文本。 plt.ylabel('So2',fontsize= 16) plt.legend() #显示标签 plt.rcParams['font.sans-serif'] = ['SimHei'] #设置显示中文字符的字体 plt.grid() #显示网格线 plt.show() #s显示图形,

So2排放量越高,AQI指数越大。
总代码:
1 import csv 2 #导入CSV文件库 3 import random 4 #导入标准库 5 import time 6 import requests 7 #可爬取http文件库 8 from bs4 import BeautifulSoup 9 import matplotlib.pyplot as plt 10 import seaborn as sns 11 import jieba 12 from wordcloud import WordCloud 13 # 导入WordCloud模块,用于生成词云 14 from PIL import Image 15 # 导入PIL库,用于处理图像 16 import numpy as np 17 # 导入numpy库,用于数值计算 18 from matplotlib import cm 19 # 导入cm模块,用于颜色映射 20 21 plt.rcParams["font.sans-serif"] = ["SimHei"] 22 plt.rcParams["axes.unicode_minus"] = False 23 import pandas as pd 24 # 导入pandas库,用于数据处理和操作 25 import matplotlib.pyplot as plt 26 # 导入matplotlib库,用于绘图 27 from wordcloud import WordCloud 28 # 导入WordCloud模块,用于生成词云 29 from PIL import Image 30 # 导入PIL库,用于处理图像 31 import numpy as np 32 # 导入numpy库,用于数值计算 33 from matplotlib import cm 34 # 导入cm模块,用于颜色映射 35 36 37 class Spider(object): 38 def __init__(self): 39 pass 40 41 def get_data_and_save(self): 42 with open('data.csv', 'w', encoding='utf-8', newline='') as f: 43 csv_writer = csv.writer(f) 44 csv_writer.writerow(['日期', '质量等级', 'AQI指数', '当天AQI排名', 'PM2.5', 'PM10', 'So2', 'No2', 'Co', 'O3']) 45 years = [2020, 2021, 2022] 46 #2020年到2022年 47 months = range(1, 13) 48 #1月到12月 49 for year in years: 50 for month in months: 51 if month < 10: 52 url = f'http://tianqihoubao.com/aqi/beijing-{year}0{month}.html' 53 else: 54 url = f'http://tianqihoubao.com/aqi/beijing-{year}{month}.html' 55 res = requests.get(url).text 56 soup = BeautifulSoup(res, 'html.parser') 57 for attr in soup.find_all('tr')[1:]: 58 one_day_data = list() 59 for index in range(0, 10): 60 one_day_data.append(attr.find_all('td')[index].get_text().strip()) 61 csv_writer.writerow(one_day_data) 62 time.sleep(2 + random.random()) 63 print(year, month) 64 65 def drawing(self): 66 csv_df = pd.read_csv('data.csv', encoding='GBK') 67 csv_df['日期'] = pd.to_datetime(csv_df['日期']) 68 csv_df.index = csv_df['日期'] 69 del csv_df['日期'] 70 71 str_data = '2020-01-01' 72 end_data = '2020-01-31' 73 new_split_df = csv_df[str_data:end_data] 74 values_count = new_split_df['质量等级'].value_counts().items() 75 total = new_split_df['质量等级'].value_counts().tolist() 76 label = new_split_df['质量等级'].value_counts().index 77 explode = [0.01 for i in range(len(total))] 78 fig, axes = plt.subplots(3, 1, figsize=(10, 8)) 79 80 81 82 if __name__ == '__main__': 83 spider = Spider() 84 # 获取数据,保存数据 85 spider.get_data_and_save() 86 # 画分析图 87 spider.drawing() 88 89 df=pd.read_csv('data.csv') 90 df 91 #导出CSV 92 93 #处理缺失值 94 df.isnull().sum() 95 96 df=pd.read_csv('data.csv') 97 #重复值处理 98 df=df.drop_duplicates() 99 df 100 101 import pandas as pd 102 import numpy as np 103 import seaborn as sns 104 import matplotlib.pyplot as plt 105 df=pd.read_csv('data.csv') 106 df.isna().any() 107 108 109 import matplotlib.pyplot as plt 110 df=pd.read_csv('data.csv') 111 #清除空值 112 datas = df.dropna() 113 display(datas) 114 115 df=pd.read_csv('data.csv') 116 df.isna().any() 117 #s是否有true值 118 119 df=pd.read_csv('data.csv') 120 #绘制 aqi 和 pm2.5 的关系散点图 121 # 设置图像尺寸 122 plt.figure(figsize=(15, 10)) 123 # 绘制散点图,横坐标为aqi数据的第二列,纵坐标为aqi数据的第四列 124 plt.scatter(df[df.columns[1]], df[df.columns[3]]) 125 # 设置横轴标签为'AQI',字体大小为20 126 plt.xlabel('空气等级', fontsize=20) 127 # 设置纵轴标签为'PM2.5',字体大小为20 128 plt.ylabel('AQI', fontsize=20) 129 # 设置图像标题为'AQI和PM2.5的关系散点图',字体大小为25 130 plt.title('空气质量等级分类散点图', fontsize=25) 131 # 显示图像 132 plt.show() 133 134 df=pd.read_csv('data.csv') 135 # 绘制空气质量等级单变量分布图 136 # 绘制以第三列为 x 轴,数据来源为 aqi 的计数图 137 sn.countplot(x=df.columns[2], data=df) 138 # 设置标题为“空气质量等级单变量分布图” 139 plt.title("空气质量等级单变量分布图") 140 # 设置 x 轴标签为“质量等级” 141 plt.xlabel("质量等级") 142 # 设置 y 轴标签为“aqi” 143 plt.ylabel("aqi") 144 # 显示图像 145 plt.show() 146 147 df=pd.read_csv('data.csv') 148 # 绘制PM2.5与AQI的线性回归拟合图 149 # 调用seaborn库的regplot函数,将PM2.5含量(ppm)作为x轴,AQI作为y轴,数据源为aqi 150 sn.regplot(x='PM2.5', y='AQI指数', data=df) 151 # 设定图表标题为 'PM2.5与AQI的线性回归拟合图' 152 plt.title('PM2.5与AQI的线性回归拟合图') 153 # 设定图表x轴标签为'PM2.5含量(ppm)' 154 plt.xlabel('PM2.5含量(ppm)') 155 # 设定图表y轴标签为'AQI' 156 plt.ylabel('AQI') 157 # 显示图表 158 plt.show() 159 160 df=pd.read_csv('data.csv') 161 # 绘制特征相关性热力图 162 # 设置画布大小 163 plt.figure(figsize=(17, 14)) 164 # 计算相关系数并赋值给变量 corr 165 corr = df[['AQI指数', 'PM2.5', 'PM10', 'So2', 'Co', 'No2', 'O3']].corr() 166 # 以热图的形式展示相关性,并用蓝红色调表示,同时在每个方格中显示数值,并设置线宽为1 167 sn.heatmap(corr, cmap='RdBu_r', annot=True, linewidths=1) 168 # 设置热图的标题,并设置字体大小为25 169 plt.title("各污染物之间的特征相关性热力分布图", fontsize=25) 170 # 设置x轴标签字体大小为15 171 plt.xticks(fontsize=15) 172 # 设置y轴标签字体大小为15 173 plt.yticks(fontsize=15) 174 # 展示画布 175 plt.show() 176 177 # Author:xueling 178 # 先打开一篇我们要统计的文章,并读取内容 179 f = open(r'data.csv', 'r', encoding='utf-8') 180 article = f.read() 181 # 建立一个空字典来存储统计结果 182 d = {} 183 # 遍历整篇文章 184 for i in article: 185 d[i] = d.get(i,0) + 1 # 字频统计 186 # 在此基础上我们还可以做一个排序: 187 ls = sorted(list(d.items()), key= lambda x:x[1], reverse=True) 188 print(d) 189 f.close() 190 191 # Author:xueling 192 # 在colletions 导入哈希表的包 193 from collections import defaultdict 194 # 打开一个要统计的文件 195 f = open(r'data.csv', 'r', encoding='utf-8') 196 article = f.read() 197 # d是通过defaultdict生成的一个哈希表,其中value我们给int型的数据类型,来记录字符数 198 d = defaultdict(int) 199 # article里每一个字我们把它当做哈希表里的key,每有一个字就给value + 1,value默认值就是0 200 for key in article: 201 d[key] += 1 202 print(d) 203 204 # 读文件,去无用字段 205 bj_date = pd.read_csv('data.csv') 206 # print(bj_date.head(30)) 207 # 数据清洗 208 #bj_date.drop(bj_date[np.isnan(bj_date['PM_US Post'])].index, inplace=True) 209 210 211 # 空气质量定级 212 def get_level(AQI指数): 213 if AQI指数 < 35: 214 return '优' 215 elif AQI指数 < 75: 216 return '良' 217 elif AQI指数 < 150: 218 return '轻度污染' 219 elif AQI指数 < 250: 220 return '中度污染' 221 elif AQI指数 >= 250: 222 return '高度污染' 223 224 225 # 给原始数据添加新列表level 226 bj_date.loc[:, 'level'] = bj_date['AQI指数'].apply(get_level) 227 print(bj_date) 228 # 统计各种空气质量的比列 229 bj_level=bj_date.groupby(['level']).size() / len(bj_date) 230 print(bj_level) 231 #画图 232 matplotlib.rcParams['font.sans-serif'] = 'SimHei' 233 l=['中度污染','优','良','轻度污染','高度污染'] 234 plt.pie(bj_level,labels=l,autopct='%.2f%%') 235 236 plt.title('北京空气质量指数') 237 plt.show() 238 239 # 打开清洗后的数据文件'data.csv' 240 import pandas as pd 241 df_new = pd.read_csv('data.csv') 242 df_new 243 import matplotlib.pyplot as plt 244 #导入matplotlib库中的pyplot模块,pyplot是用于创建图表的主要函数 245 df_new['当天AQI排名'].value_counts().nlargest(10).plot.bar(figsize=(14,6),fontsize= 13) 246 plt.title('柱形图',fontsize= 20) 247 plt.xlabel('AQI',fontsize= 16) 248 plt.xticks(rotation=0) 249 #设置X轴刻度标签的旋转角度。xticks是指X轴上的刻度,rotation参数指定刻度标签的旋转度数,0表示不旋转。若刻度标签内容过长,旋转角度可以调整为其他角度,以便更好地展示文本。 250 plt.ylabel('So2',fontsize= 16) 251 plt.legend() 252 #显示标签 253 plt.rcParams['font.sans-serif'] = ['SimHei'] 254 #设置显示中文字符的字体 255 plt.grid() #显示网格线 256 257 plt.show() #s显示图形
总结:
1.pm2.5,pm10,so2,no2,co,o3等有毒气体对AQI指数的影响,有毒气体排放越大,AQI指数越大,AQI指数越大,空气质量越差。
2.我们应爱护环境,减少有毒气体的排放,坚持绿色发展。
改进的建议包括:
增加更多的数据源,以获得更全面和准确的数据,可以提却更多的字段信息,从不同角度去分析“空气污染程度”的普及程度。
进一步优化爬虫程序的效率和稳定性。
进一步深入数据分析和建模,例如使用机器学习算法进行情感分析或预测模型的构建。
增加更多的数据可视化方法和图表类型,以更好地展示数据和结论。
要对所获取的文本进行更加精确的分词以及进行聚类,使所得到的分词更具有主题性。
通过不断改进和完善,可以使网络爬虫程序更具实用性和可靠性,并为空气污染相关的数据分析提供更有价值的见解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号