
python爬虫——爬取京东官网联想笔记本电脑评论的数据
(一)选题背景
比起台式电脑来说,笔记本电脑方便得多。随着网络的发展,现在很多事情都可以在手机上办理,很大程度上便利了人们的生活。但还是有些事情在电脑上更安全一些,所以有一台电脑还是很重要的。在淘宝、京东等网络平台上购物,逐渐成为大众化的购物方式。但假冒伪劣产品在这个摸不着实物的购物平台严重危害着消费者的购物体验,即使我们可以通过七天无理由退货退款来维护我们的合法权益,但是这样浪费大量的人力和财力。我们希望能够一次性通过网络购买到心怡的商品,其实我们可以在购买商品之前在对应商品店铺下查看以往买家的购物体验和商品评价,通过商品评价判断该商品是否值得购买。但是事实并非如此,网络购物平台的一些商家为了吸引顾客购买商品,往往会通过刷假评论诱骗买家,同时也有一大批被‘好评返现’吸引的消费者注入大量注水评论。虽然往往买家都能够筛选出大部分这样的评论,但人工筛查繁琐、复杂。其实一个好的筛选评论、重构评论的程序能够为消费者提供更真实的商品信息。那么,不懂电脑的人该怎么挑选电脑呢?随着时代的发展,几乎每个人都会买一台电脑,对不同的领域买不同的电脑。而现在电脑的质量层次不齐,这时候就需要跟该店铺其他评论看出该店铺质量如何。挑选电脑更加方便快捷!
数据来源:https://club.jd.com/comment/productPageComments.action
(二)主题网络爬虫设计方案
网络爬虫名称:爬取京东联想电脑评论单位数据
爬取的内容:评分、评论时间、评论内容
主题式网络爬虫设计方案概述(包括实现思路与技术难点):
实现思路:绕过反爬获取网页资源,使用etree解析网页,用xpath定位爬取内容标签后爬取资源并将数据保存到csv文件中。
技术难点:设置请求头,for循环实现重复爬取
(三)主题页面结构特征分析
分析网页结构
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>页面结构分析</title>
</head>
<body>
<!--header:表示头部区域的内容(用于页面,或页面中的一块区域。
footer:标记脚步区域的内容,用于整个页面或者页面当中的一块区域。
section:web页面当中的一块独立区域。
article :独立的文章内容
aside: 相关内容或应用
nav:导航辅助类的内容信息-->
<header>
<h2>网页头部</h2>
</header>
<section>
<h2>网页主体</h2>
</section>
<footer>
<h2>网页脚本</h2>
</footer>
</body>
</html>
节点查找方式和遍历方法:
在索引页上获取每个详情页url运用正则表达式的方法,然后运用BeautifulSoup,使用select方法,获取所需要的数据所在的节点。
查找方法:find_all
遍历方法:for循环遍历
(四)网络爬虫程序设计
①先爬取其中一款电脑,爬取其评分、评论时间、评论内容。
import requests
import csv
from time import sleep
import random
def main(page,f):
url = 'https://club.jd.com/comment/productPageComments.action'
params = {
'productId': 100011483893,
'score': 0,
'sortType': 5,
'page': page,
'pageSize': 10,
'isShadowSku': 0,
'fold': 1
}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.35 Safari/537.36',
'referer': 'https://item.jd.com/'
}
resp = requests.get(url,params=params,headers=headers).json()
comments = resp['comments']
for comment in comments:
content = comment['content']
content = content.replace('\n','')
comment_time = comment['creationTime']
score = comment['score']
print(score,comment_time,content)
csvwriter.writerow((score,comment_time,content))
print(f'第{page+1}页爬取完毕')
if __name__ == '__main__':
with open('4.csv','a',encoding='utf-8',newline='')as f:
csvwriter = csv.writer(f)
csvwriter.writerow(('评分','评论时间','评论内容'))
for page in range(15):
main(page,f)
sleep(5+random.random())
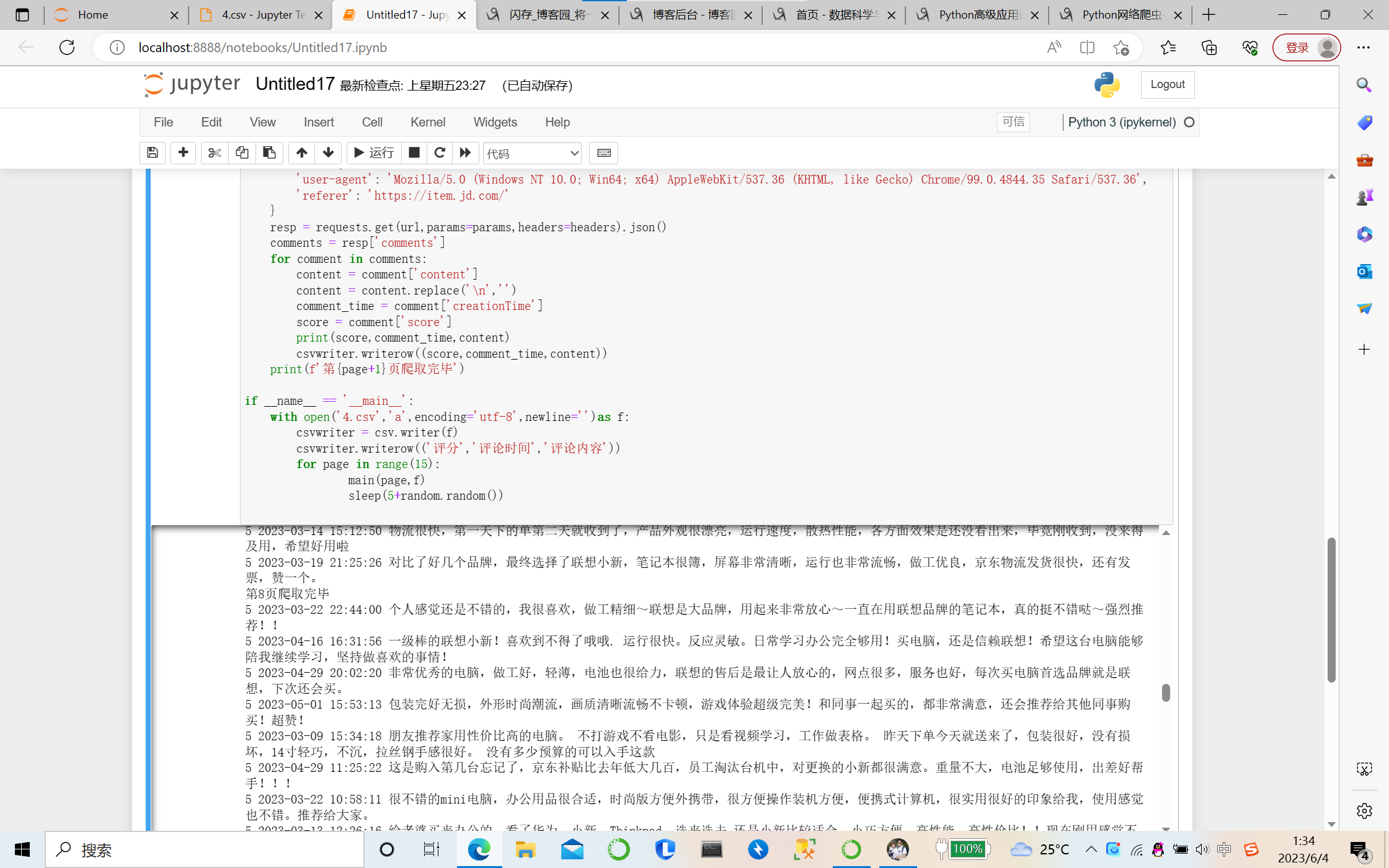
②爬取的内容生成了一个csv文件
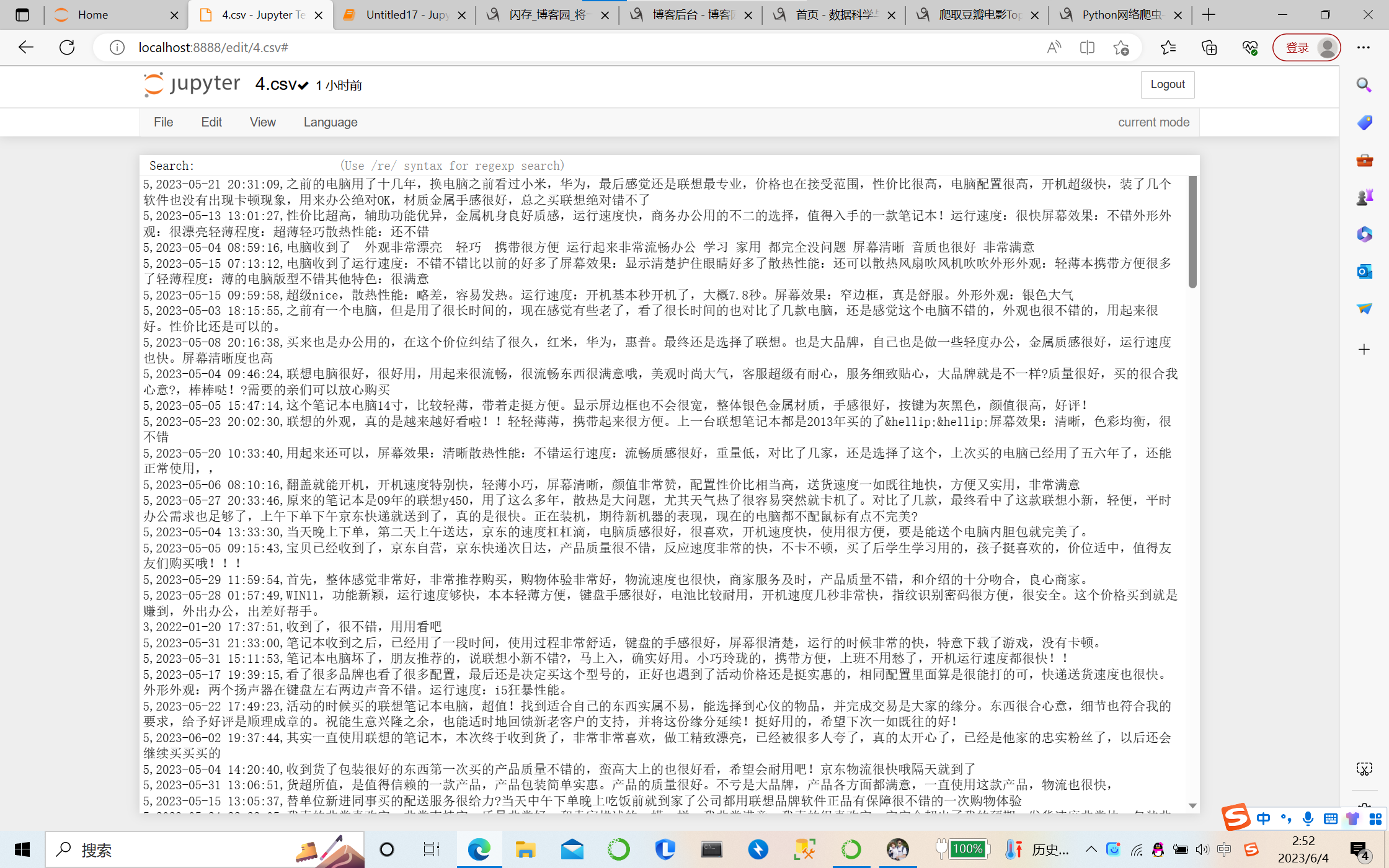
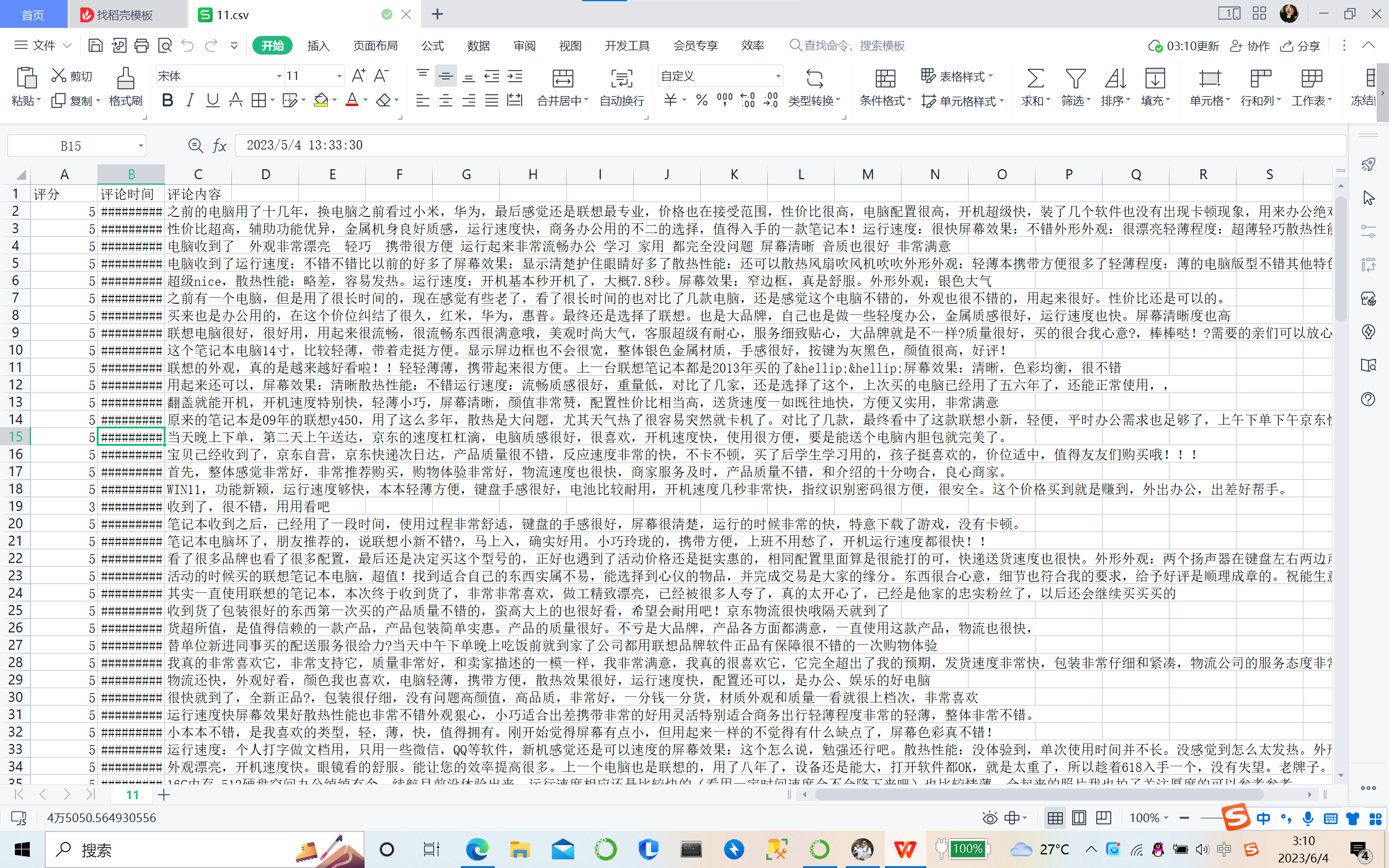
③对数据进行清洗
import pandas as pd
df = pd.read_csv("4.csv")
print(df.describe())
#查看有多少列
#print(df.shape)
# 结果 (行数,列数)
print(df.info())
# 查看索引信息
print(df.index)
# 判断重复值 返回值类型为 Boolean
print(df.duplicated())

false表示没有重复,true表示有重复,默认从上到下比较,若上一行的数据和下一行的数据重复,则下一行标记为true。如图所示没有重复的数据,没有出现TRUE。
④文本分析(jieba分词):
import os
import pandas as pd
import jieba
#csv文件读取一列,转为list
def columnOflist(datas,cName):
job_info=datas.loc[:,cName]
job_info=job_info.tolist()
return job_info
#对列表数据进行分词操作
#返回一个分词后的list
def stripWord(job_info):
#停用词表
stop=open('11.csv','r',encoding='utf-8')
stopWord=stop.read().split("\n")
#调用新词库
print("正在分词。。。。。。。")
jieba.load_userdict('计算机名词大全.txt')
wordlists=[]
for input in job_info:
seg_list=jieba.cut(input,cut_all=False)
#print('精确模式','/'.join(seg_list))
wordlist=[]
for key in seg_list:
if not(key.strip() in stopWord) and (len(key.strip()) > 1) and not(key.strip() in wordlist) :
wordlist.append(key)
wordlists.append(wordlist)
print("分词成功。。。。。。。")
return wordlists
#将分词到的数据替换成原来杂乱的数据,保存到新表中
def saveCsv(datas,cName,Keylists,file):
print("正在替换。。。。。。")
for i in range(len(Keylists)):
var = ','.join(Keylists[i])
datas.loc[i,cName]=var
print("替换成功,正在保存文件。。。。。")
datas.to_csv('自己路径'+file)
print("保存成功")
path=' ' #源文件夹路径
files=11.csv(path) #文件名
cName='job_info' #列名
for file in files:
datas=pd.read_csv(path+file)
inputlist=columnOflist(datas,cName)
keylist=stripWord(inputlist)
saveCsv(datas,cName,keylist,file)
import jieba
def file_cut(file, output_file):
with open(output_file, "w", encoding="utf-8") as f:
for line in open(file, "r", encoding="utf-8"):
line = line.strip()
o_str = " ".join(jieba.lcut(line))
f.write(o_str + "\n")
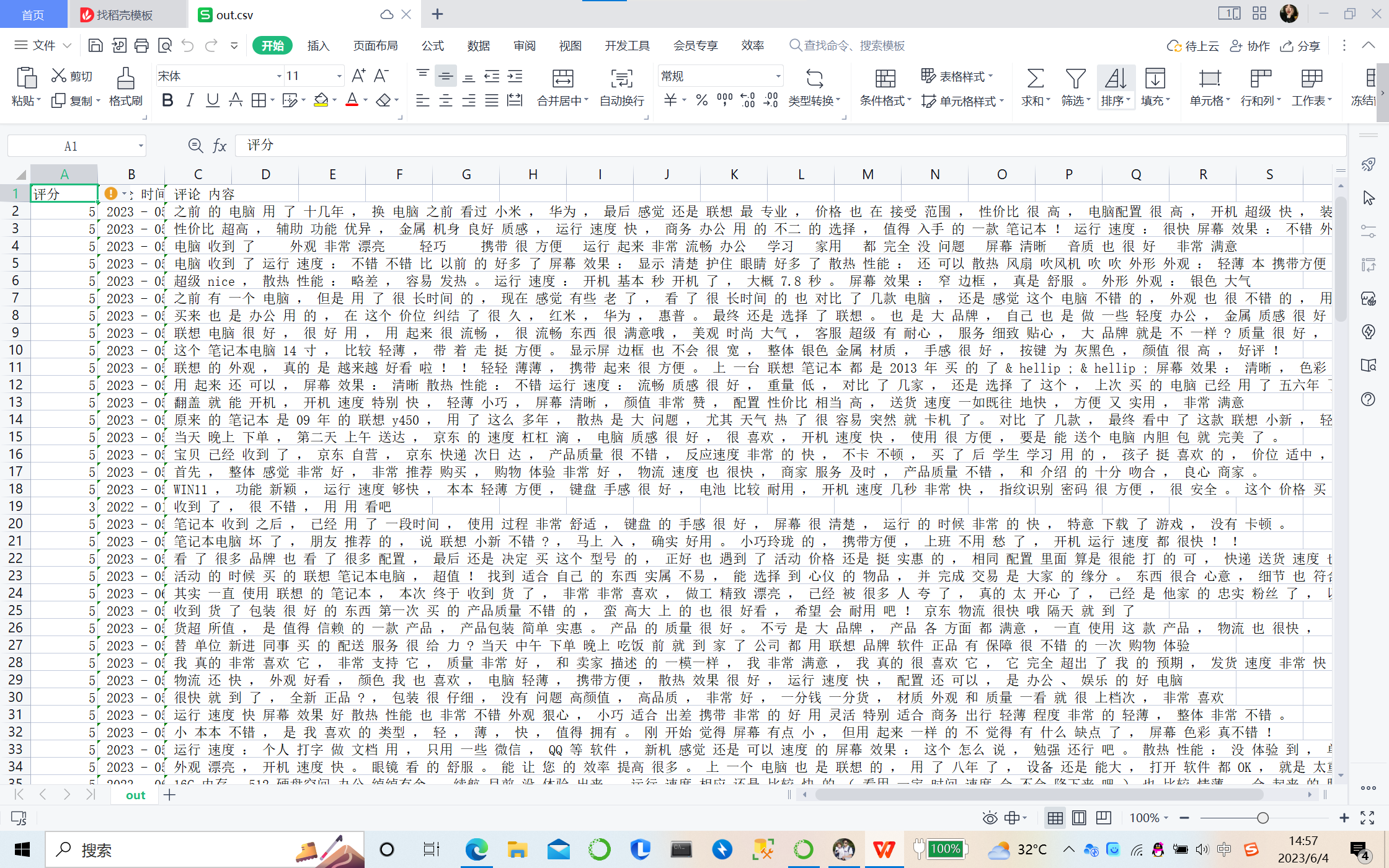
file_cut("11.csv", "out.csv")
分词效果如图:
⑤数据分析可视化
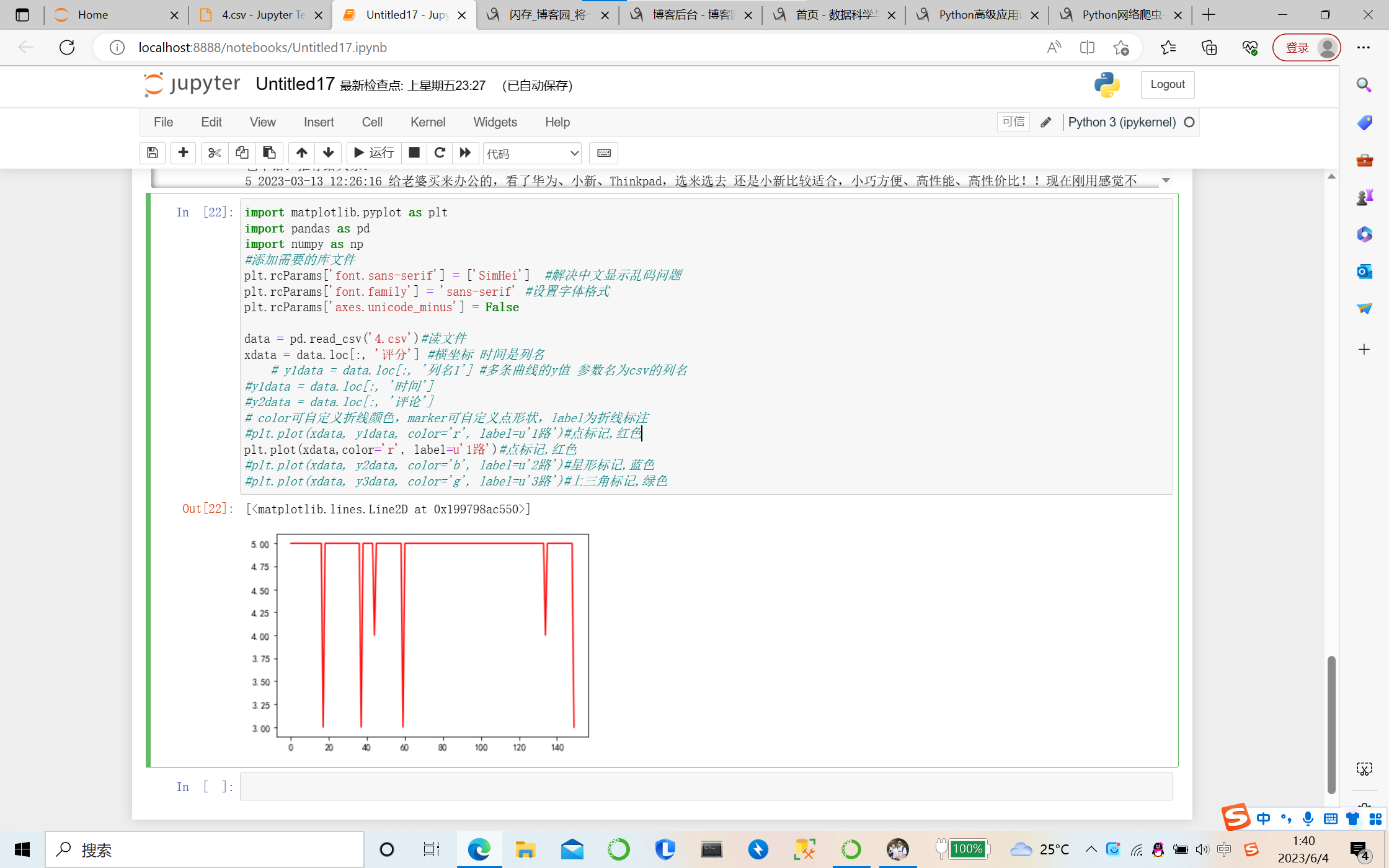
折线图
将爬出的评分制作折线图,能更明显看出评分的差距!
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
#添加需要的库文件
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示乱码问题
plt.rcParams['font.family'] = 'sans-serif' #设置字体格式
plt.rcParams['axes.unicode_minus'] = False
data = pd.read_csv('4.csv')#读文件
xdata = data.loc[:, '评分'] #横坐标 时间是列名
# y1data = data.loc[:, '列名1'] #多条曲线的y值 参数名为csv的列名
#y1data = data.loc[:, '时间']
#y2data = data.loc[:, '评论']
# color可自定义折线颜色,marker可自定义点形状,label为折线标注
#plt.plot(xdata, y1data, color='r', label=u'1路')#点标记,红色
plt.plot(xdata,color='r', label=u'1路')#点标记,红色
将爬取的内容全部制成图
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
#添加需要的库文件
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示乱码问题
plt.rcParams['font.family'] = 'sans-serif' #设置字体格式
plt.rcParams['axes.unicode_minus'] = False
data = pd.read_csv('11.csv')#读文件
xdata = data.loc[:, '评分'] #横坐标 时间是列名
# y1data = data.loc[:, '列名1'] #多条曲线的y值 参数名为csv的列名
y1data = data.loc[:, '评论时间']
y2data = data.loc[:, '评论内容']
# color可自定义折线颜色,marker可自定义点形状,label为折线标注
#plt.plot(xdata, y1data, color='r', label=u'1路')#点标记,红色
plt.plot(xdata, y1data,color='r', label=u'1路')#点标记,红色
plt.plot(xdata, y2data, color='b', label=u'2路')#星形标记,蓝色
plt.plot(xdata, y3data, color='g', label=u'3路')#上三角标记,绿色
制作散点图
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('11.csv')#导入csv文件
#.info()返回当前csv数据信息
print(df.info())
plt.scatter(df['评分'], df['评论时间'],s=0.5)#s指的是点的面积
# plt.scatter(x,y,s)
plt.xlabel(u'评分')
plt.ylabel(u"评论时间")
# #画出散点图
plt.show()
# #将散点图显示出来
⑥数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变量之间的回归方程(一元或多元)
import pandas as pd
import numpy as mp
import sklearn
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.optimize import leastsq
plt.rcParams['font.sans-serif'] = ['SimHei']#解决乱码问题
#读取文件
aodi = pd.DataFrame(pd.read_csv('11.csv'))
sns.regplot(x = '评分',y = '评论时间',data=aodi)
⑦数据持久化
数据持久化步骤:
1)确定需要持久化的数据
2)创建保存需要持久化数据的文件
3)确定文件初始内容(就是需要持久化的数据的初始值)
4)在程序中需要这个数据的时候从文件中获取这个数据
5)在程序中修改这个数据后,必须讲最新的数据写入到文件中
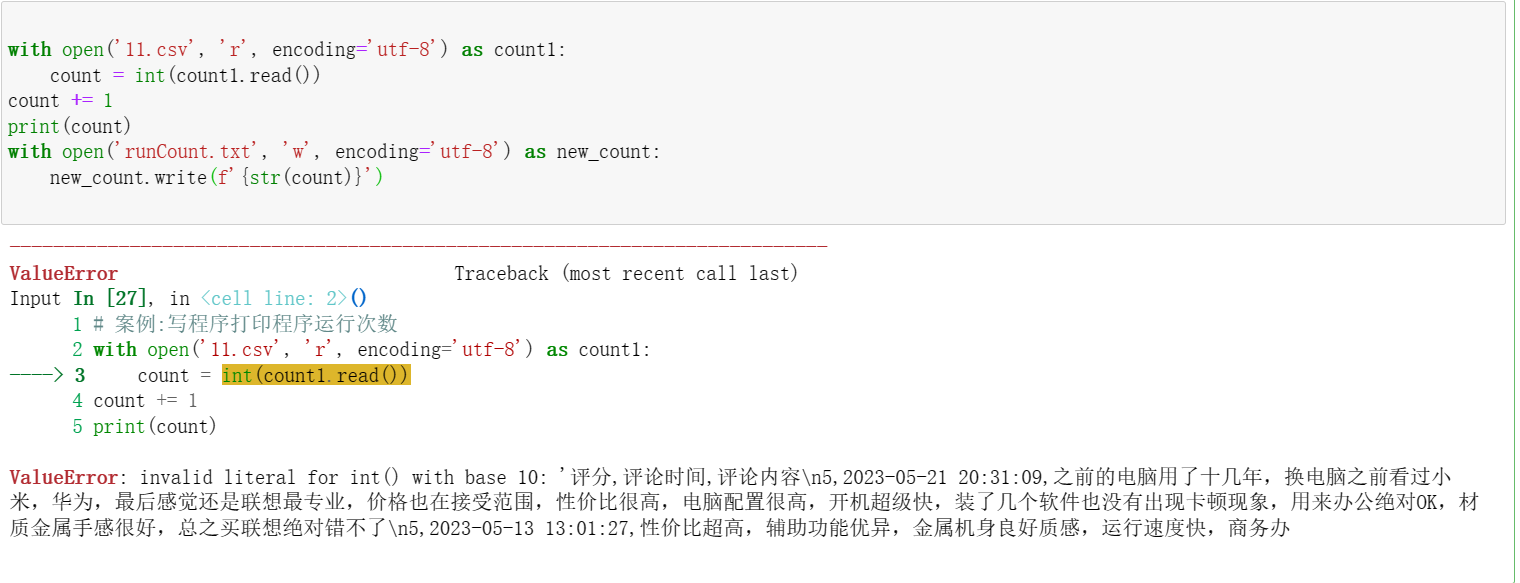
with open('11.csv', 'r', encoding='utf-8') as count1:
count = int(count1.read())
count += 1
print(count)
with open('runCount.txt', 'w', encoding='utf-8') as new_count:
new_count.write(f'{str(count)}')
完整代码:
import requests
import csv
from time import sleep
import random
import os
import jieba
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import numpy as mp
import sklearn
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.optimize import leastsq
plt.rcParams['font.sans-serif'] = ['SimHei']
#添加需要的库文件
def main(page,f):
url = 'https://club.jd.com/comment/productPageComments.action'
#数据来源
params = {
'productId': 100011483893,
'score': 0,
'sortType': 5,
'page': page,
'pageSize': 10,
'isShadowSku': 0,
'fold': 1
}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.35 Safari/537.36',
'referer': 'https://item.jd.com/'
}
resp = requests.get(url,params=params,headers=headers).json()
comments = resp['comments']
for comment in comments:
content = comment['content']
content = content.replace('\n','')
comment_time = comment['creationTime']
score = comment['score']
print(score,comment_time,content)
csvwriter.writerow((score,comment_time,content))
print(f'第{page+1}页爬取完毕')
#爬取读取结束语句
if __name__ == '__main__':
with open('11.csv','a',encoding='utf-8',newline='')as f:
#爬取完存储到4.CSV文件中
csvwriter = csv.writer(f)
csvwriter.writerow(('评分','评论时间','评论内容'))
for page in range(15):
#爬取的页数
main(page,f)
sleep(5+random.random())
plt.rcParams['font.sans-serif'] = ['SimHei']
#解决中文显示乱码问题
plt.rcParams['font.family'] = 'sans-serif'
#设置字体格式
plt.rcParams['axes.unicode_minus'] = False
data = pd.read_csv('11.csv')
#读文件
xdata = data.loc[:, '评分']
#横坐标 时间是列名
# y1data = data.loc[:, '列名1']
#多条曲线的y值 参数名为csv的列名
y1data = data.loc[:, '评论时间']
y2data = data.loc[:, '评论内容']
# color可自定义折线颜色,marker可自定义点形状,label为折线标注
#plt.plot(xdata, y1data, color='r', label=u'1路')
#点标记,红色
plt.plot(xdata, y1data,color='r', label=u'1路')
#点标记,红色
plt.plot(xdata, y2data, color='b', label=u'2路')
#星形标记,蓝色
plt.plot(xdata, y3data, color='g', label=u'3路')
#上三角标记,绿色
import pandas as pd
df = pd.read_csv("11.csv")
print(df.describe())
#查看有多少列
#print(df.shape)
# 结果 (行数,列数)
print(df.info())
# 查看索引信息
print(df.index)
# 判断重复值 返回值类型为 Boolean
print(df.duplicated())
!pip install jieba
#判断有没有安装jieba库
#csv文件读取一列,转为list
def columnOflist(datas,cName):
job_info=datas.loc[:,cName]
job_info=job_info.tolist()
return job_info
#对列表数据进行分词操作
#返回一个分词后的list
def stripWord(job_info):
#停用词表
stop=open('11.csv','r',encoding='utf-8')
stopWord=stop.read().split("\n")
#调用新词库
print("正在分词。。。。。。。")
jieba.load_userdict('计算机名词大全.txt')
wordlists=[]
for input in job_info:
seg_list=jieba.cut(input,cut_all=False)
#print('精确模式','/'.join(seg_list))
wordlist=[]
for key in seg_list:
if not(key.strip() in stopWord) and (len(key.strip()) > 1) and not(key.strip() in wordlist) :
wordlist.append(key)
wordlists.append(wordlist)
print("分词成功。。。。。。。")
return wordlists
#将分词到的数据替换成原来杂乱的数据,保存到新表中
def saveCsv(datas,cName,Keylists,file):
print("正在替换。。。。。。")
for i in range(len(Keylists)):
var = ','.join(Keylists[i])
datas.loc[i,cName]=var
print("替换成功,正在保存文件。。。。。")
datas.to_csv('自己路径'+file)
print("保存成功")
path=' ' #源文件夹路径
files=11.csv(path) #文件名
cName='job_info' #列名
for file in files:
datas=pd.read_csv(path+file)
inputlist=columnOflist(datas,cName)
keylist=stripWord(inputlist)
saveCsv(datas,cName,keylist,file)
def file_cut(file, output_file):
with open(output_file, "w", encoding="utf-8") as f:
for line in open(file, "r", encoding="utf-8"):
line = line.strip()
o_str = " ".join(jieba.lcut(line))
f.write(o_str + "\n")
file_cut("11.csv", "out.csv")
df = pd.read_csv('11.csv')
#导入csv文件
#.info()返回当前csv数据信息
print(df.info())
plt.scatter(df['评分'], df['评论时间'],s=0.5)
#s指的是点的面积
# plt.scatter(x,y,s)
plt.xlabel(u'评分')
plt.ylabel(u"评论时间")
# #画出散点图
plt.show()
# #将散点图显示出来
#解决乱码问题
#读取文件
aodi = pd.DataFrame(pd.read_csv('11.csv'))
sns.regplot(x = '评分',y = '评论时间',data=aodi)
with open('11.csv', 'r', encoding='utf-8') as count1:
count = int(count1.read())
count += 1
print(count)
with open('runCount.txt', 'w', encoding='utf-8') as new_count:
new_count.write(f'{str(count)}')
(五)总结
通过这次课程设计,加强了我们动手、思考和解决问题的能力。虽然有借鉴百度,但是有些运行出来还是有问题,然后进行数据处理、分析。我了解了 python 的基本数据类型、基本语句和函数等基本知识。同时,我也学会了如何运用 python 的内置函数和库来解决实际问题,比如如何读写文件、如何操作列表和画图可视化等等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号