Fast Packet Processing with eBPF and XDP部分
本文整理了读了Fast Packet Processing with eBPF and XDP中有关eBPF的部分内容后的相关知识
BPF产生背景
- 互联网流量的增加和数据中心网络中提供的服务的日益复杂要求越来越高的数据包处理速率。
- 服务需求的动态性要求网络快速适应,以保持足够的服务质量水平,并有效地使用可用资源。
- 计算机网络传统上是静态发展的,通信协议的实现嵌入到网络设备的硬件中,难以适应当前的需求。
BPF是什么
- Berkeley Packet Filter (BPF)是由Steven McCanne和Van Jacobson在1992年提出的,作为在Unix BSD系统内核上执行信息包过滤的解决方案。
- 它由一组指令和一个用于执行用那种语言编写的程序的虚拟机(VM)组成。
eBPF是什么
- Extended Berkeley Packet Filter(eBPF)是Linux内核内的指令集和执行环境。它支持在运行时进行修改、交互和内核编程。
- eBPF可以用来编程eXpress Data Path (XDP),一个内核网络层,处理数据包接近NIC的快速数据包处理。
- 开发人员可以用C或P4语言编写程序,然后编译成eBPF指令,这些指令可以由内核或可编程设备(如SmartNICs)处理。
eBPF用途
- 比如网络监控、网络流量处理、负载平衡和操作系统洞察。有几家公司已经在Facebook、Netronome和Cloudflare等项目上使用了eBPF。
eBPF的组成
- 一套指令
- 一个虚拟机(VM),用于执行用该语言编写的程序。
- BPF定义了基于包的内存模型(加载指令在被处理的包中隐式生成),
- 两个寄存器:累加器(A)和索引表(X)
- 隐含的程序计数器
- 一个临时的辅助内存
为什么设计eBPF
- BPF不仅对信息包过滤非常有用,其他领域也可以从它检测内核的能力中受益。为了将BPF机转化为通用的内核内虚拟机,对BPF机及其总体架构进行了大量改进。这个新版本称为eBPF(扩展的BPF),或简称BPF,而最初的迭代成为cBPF(经典的BPF)。
eBPF的优势
- 具有安全检查
- 应用程序的字节码从用户空间传输到内核,然后在内核中对其进行检查,以确保安全性并防止内核崩溃。
- 简单且定义良好的指令集
- BPF的即时(JIT)编译引擎
- eBPF程序在运行时修改(可编程的)内核操作,不需要重新编译内核。
JIT
JIT是一种提高程序运行效率的方法。通常,程序有两种运行方式:静态编译与动态解释。静态编译的程序在执行前全部被翻译为机器码,而动态解释执行的则是一句一句边运行边翻译。
eBPF的结构

- 寄存器的数量从2个增加到11个(其中10个是写寄存器)
- 寄存器的宽度从32位变为64位
- 指令集现在是64位,新的引擎有512字节的堆栈。
- 它包括被称为地图的全球数据存储。
- 它添加了帮助函数。
- eBPF的指令集架构(ISA)
ISA被更新为包括遵循C调用约定的函数调用。 - 参数通过寄存器传递给函数。这允许将一个eBPF函数调用映射到一个硬件指令,这几乎没有开销。
- eBPF虚拟机支持动态加载和程序重新加载。
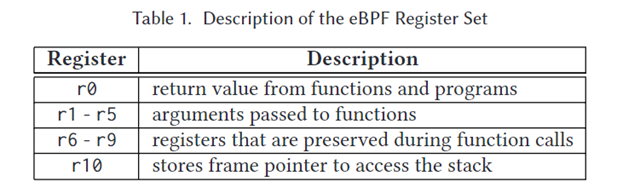
- 寄存器r0存储函数返回值,表示在计算结束时,在转发数据包时将采取什么动作。
- 寄存器r10是唯一的只读寄存器,它将地址存储到BPF堆栈中。
- 参数作为寄存器值传递给函数。寄存器r1-r5是为此保留的,而寄存器r6-r9在函数调用之间预先提供了它们的值。
eBPF系统
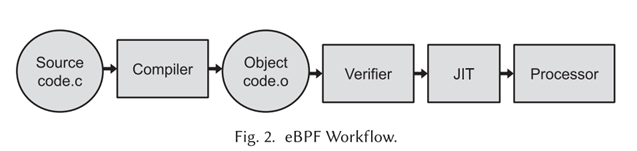
-
一个eBPF程序是用高级语言(主要限制为C语言)编写的。clang编译器将其转换为ELF/目标代码。ELF/eBPF加载程序可以使用特殊的系统调用将其插入到内核中。在这个过程中,验证者分析程序,核通过后执行动态转换(JIT)。程序可以卸载到硬件上,否则由处理器本身执行。
-
从3.7版本开始,LLVM编译器集合有一个用于eBPF平台的后端。它允许在C的子集中开发eBPF程序,并通过clang编译器生成eBPF格式的可执行代码。
C的这个子集排除了一些系统调用和库,但是它提供了帮助函数来操作eBPF映射和执行其他常见任务。 -
eBPF的一些限制
eBPF只能使用C语言库的一个子集。例如,printf()函数不可用 不允许使用非静态全局变量; 只允许有界循环。 堆栈空间被限制为512字节
eBPF内核验证器
工作原理
-
验证者使用两个方法来决定是否拒绝一个程序。
- 在第一轮中,它使用深度优先搜索来检查程序指令是否可以被解析成一个有向无环图(DAG)。以保证其中没有循环存在;除此之外,一旦在代码中发现以下特征,verifier 也会拒绝注入:
1.代码长度超过上限,目前(内核版本 4.12)eBPF 的代码长度上限为 4K 条指令——这在 cBPF 时代很难达到,但别忘了 eBPF 代码是可以用 C 实现的;
2.存在可能会跳出 eBPF 代码范围的 JMP,这主要是为了防止恶意代码故意让程序跑飞;
3.存在永远无法运行(unreachable)的 eBPF 令,例如位于 exit 之后的指令;
- 次轮检查(Second pass,实现于do_check())较之于首轮则要细致很多:在本轮检测中注入代码的所有逻辑分支从头到尾都会被完全跑上一遍,所有的指令的参数(寄存器)、访问的内存、调用的函数都会被仔细的捋一遍,任何的错误都会导致注入程序被退货。由于过分细致,本轮检查对于注入程序的复杂度也有所限制:首先程序中的分支(branch)不允许超过 1024 个;其次经检测的指令数也必须在 96K 以内。 -
关于eBPF验证器还有两点。
- 第一个与以下事实有关:一些eBPF函数只能由具有GPL兼容许可证的程序调用。
- 最后,验证器不允许访问超出本地变量和数据包界限的内存,以确保内核的完整性和安全性。
如果eBPF程序不做这种类型的检查,那么验证者拒绝它,因此它不能加载到内核。
eBPF程序是如何以及何时执行的
要执行一个eBPF程序,首先需要把它附加到允许自定义编程的接口上。这个接口称为钩子。钩子允许程序注册某些事件。如两个可以附加eBPF程序的Linux内核钩子:XDP和TC。
eBPF机制思维导图

LLVM与Clang
什么是LLVM
LLVM项目是模块化、可重用的编译器以及工具链技术的集合。
LLVM架构

- 不同的前端后端使用统一的中间代码LLVM Intermediate Representation (LLVM IR)
- 如果需要支持一种新的编程语言,那么只需要实现一个新的前端
- 如果需要支持一种新的硬件设备,那么只需要实现一个新的后端
- 优化阶段是一个通用的阶段,它针对的是统一的LLVM IR,不论是支持新的编程语言,还是支持新的硬件设备,都不需要对优化阶段做修改
- 相比之下,GCC的前端和后端没分得太开,前端后端耦合在了一起。所以GCC为了支持一门新的语言,或者为了支持一个新的目标平台,就 变得特别困难
- LLVM现在被作为实现各种静态和运行时编译语言的通用基础结构(GCC家族、Java、.NET、Python、Ruby、Scheme、Haskell、D等)
什么是Clang
LLVM项目的一个子项目,基于LLVM架构的C/C++/Objective-C编译器前端。
相比于GCC,Clang具有如下优点
- 编译速度快:在某些平台上,Clang的编译速度显著的快过GCC(Debug模式下编译OC速度比GGC快3倍)
- 占用内存小:Clang生成的AST所占用的内存是GCC的五分之一左右
- 模块化设计:Clang采用基于库的模块化设计,易于 IDE 集成及其他用途的重用
- 诊断信息可读性强:在编译过程中,Clang 创建并保留了大量详细的元数据 (metadata),有利于调试和错误报告
- 设计清晰简单,容易理解,易于扩展增强
Clang与LLVM关系

- LLVM整体架构,前端用的是clang,广义的LLVM是指整个LLVM架构,一般狭义的LLVM指的是LLVM后端(包含代码优化和目标代码生成)。
- 源代码(c/c++)经过clang--> 中间代码(经过一系列的优化,优化用的是Pass) --> 机器码


 浙公网安备 33010602011771号
浙公网安备 33010602011771号