DS博客作业---线性表
0. PTA得分截图

1. 本周学习总结
1.1总结线性表内容
1.1.1顺序表结构体定义、顺序表插入、删除的代码操作
顺序表结构定义
typedef struct List{
int data[MAX];//保存线性表元素
int Length;//保存线性表长度
}List,*SqList;
顺序表插入
for (i = L->length - 1; i >= 0; i--)//从后面开始找插入位置,不满足元素则往后移,满足则插入
{
if (x > L->data[i])
{
L->data[i + 1] = x;
L->length++;
return;
}
else
{
L->data[i + 1] = L->data[i];
}
if (i == 0)
{
L->data[i] = x;
L->length++;
return;
}
}
顺序表删除元素操作
int i,j,k;
k = 0;
j = L->length;
L->length = 0;//重构顺序表
for (i = 0; i < j; i++)
{
if (!(L->data[i]>=min && L->data[i]<=max))//不在删除区间内的,写入重构顺序表
{
L->data[k++] = L->data[i];
L->length++;
}
}
顺序表删除重复元素,并且顺序不变
//一般都是用选择排序或冒泡排序来做,但学了数据结构,就要追求更高效的算法,降低时间复杂度
int i, j,len;
i = 0; j = 0;
static int hash[maxsize];//新建一个哈希数组,牺牲空间来换取时间
len = L->length;
L->length = 0;
for (i = 0; i < len; i++)
{
hash[L->data[i]]++;
if (hash[L->data[i]] == 1)
{
L->data[j++] = L->data[i];
L->length++;
}
}
1.1.2 链表结构体定义、头插法、尾插法、链表插入、删除操作
链表结构定义
typedef struct LNode //定义单链表结点类型
{
ElemType data;
struct LNode *next; //指向后继结点
} LNode,*LinkList;
头插法代码
void CreateListF(LinkList& L, int n)//头插法建链表,L表示带头结点链表,n表示数据元素个数
{
int i;
LinkList tempptr;
L = new LNode;
L->next = NULL;
for (i = 0; i < n; i++)
{
tempptr = new LNode;
cin >> tempptr->data;
tempptr->next = L->next;
L->next = tempptr;
}
}//顺序与输入数据顺序相反,无需尾指针
尾插法
void CreateListR(LinkList& L, int n)//尾插法建链表,L表示带头结点链表,n表示数据元素个数
{
LinkList tailptr,tempptr;
L = new LNode;
L->next = NULL;
tailptr = L;
int i;
for (i = 0; i < n; i++)
{
tempptr = new LNode;
cin >> tempptr->data;
tailptr->next = tempptr;
tailptr = tempptr;
}
tailptr->next = NULL;
}//需要尾指针,输入顺序与输出顺序相同
链表插入数据代码
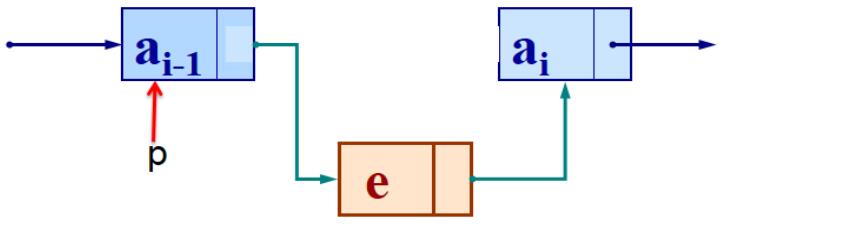
{
s=new LNode;
s->data=e;//插入节点
s->next=p->next;
p->next=s;
}
链表删除数据
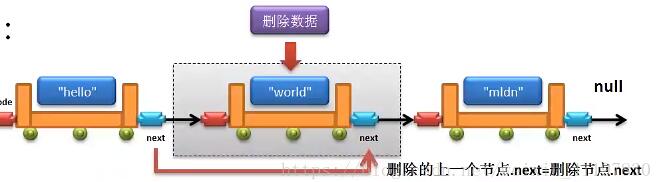
{
q=p->next;//保存删除节点
p->next=q->next;//将节点连向下一个节点
delete q;//销毁删除节点
}
1.1.3 有序表,尤其有序单链表数据插入、删除,有序表合并
有序单链表数据插入
void ListInsert(LinkList& L, ElemType e)//有序链表插入元素e
{
LinkList nodePtr,tailPtr;
tailPtr = new LNode;
tailPtr->data = e;
tailPtr->next = NULL;
nodePtr = L;
while (nodePtr->next&&nodePtr->next->data<e) //找到插入的位置
{
nodePtr = nodePtr->next;
}
tailPtr->next = nodePtr->next;
nodePtr->next = tailPtr;
}
有序单链表数据删除
void ListDelete(LinkList& L, ElemType e)//链表删除元素e
{
LinkList DeletePtr,p;
DeletePtr = L;
while (DeletePtr->next)
{
if (DeletePtr->next->data == e)//找到删除节点,销毁节点
{
p = DeletePtr->next;
DeletePtr->next = DeletePtr->next->next;
delete p;
return;
}
DeletePtr = DeletePtr->next;
}
if (L->next==NULL) return;
cout << e << "找不到!"<<endl;
}
有序表合并
void MergeList(LinkList& L1, LinkList L2)//合并链表
{
while 遍历两个链表,直到一个为空
if (tempLink->data > L2->data)
{
尾插法将该节点写入新链表;
L2 = L2->next;
}
else if (tempLink->data < L2->data)
{
尾插法将该节点写入新链表;
tempLink = tempLink->next;
}
else if (tempLink->data == L2->data)
{
tailptr->next = L2;
tailptr = L2;
L2 = L2->next;
tempLink = tempLink->next;
}
if 判断链表tempptr是否为空,不为则将剩下写入新链表
if 判断链表tL2是否为空,不为则将剩下写入新链表
tailptr->next = NULL;
}
1.1.4 循环链表、双链表结构特点
循环链表:将表中尾节点的指针域改为指向表头节点,整个链表形成一个环。由此从表中任意节点出发,都可以找到其他节点

双链表:每个节点中有两个指针域,一个指向后继节点,一个指向前驱结点。从任意节点出发都可以快速找到其前驱和后继
其结构示意图如下:
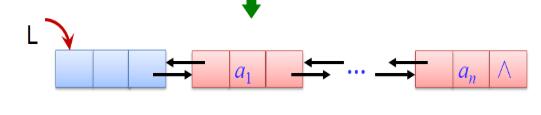
1.2谈谈你对线性表的认识及学习体会。
经过一两周的学习,从刚开始对创建链表都很费劲的我,现在对链表基本操作都可以掌握了,最主要还是要画图来看,会更加清晰。
在看到第一章时,各种时间复杂度的差异,纵使在小数据量时差距不大,但在大数据量的作用下,都会使得差距很大。
而在以后的工作中,面临的肯定都是大数据,所以关注其时间成本才是重中之重。以及在做PTA时,我会经常考虑它的时间复杂度,看有没有更节约时间的做法,学这本书,我觉得更重要的是学习它的算法,如何更快的节省时间,降低时间复杂度。
在做PTA时,经常会遇到在保存节点后,容易把节点后的给丢失掉。后面再进行保存节点时,我得及时把节点给移到下一个节点处,这样才不会让它丢失,也可以将该节点的数据保存下来,这样也是可以的。
还有就是以往有一个习惯就是不喜欢画图来做链表,经常导致链表关系丢失,画图之后,确实感觉链表关系明确了好多,丢失这种错误也很少再犯。
2. PTA实验作业
2.1 题目1: jmu-ds-链表倒数第m个数
2.1.1 代码截图

2.1.2 本题PTA提交列表说明
第一次是用遍历一次链表,再重新找他的倒数第m个数的做法
多种错误:①第二次找他的倒数m个数据时,L没有循环到下一个节点②j=n-m+1,第一次没有加一,导致读出的数据往前了一位,修改后便正确
第二次用老师上课讲的做法,节约了更多时间。即新建两个指针,第一个指向正数第m个节点,第二次两个指针一起往前走,直到第一个指针结束。也是相当于做了减法,但巧妙地节约了时间
部分正确:没有考虑无效位置的情况下,就是在输入0或者负数时的情况。在前面加上一个判断m的情况就可以了
2.2 题目2: jmu-ds-有序链表合并 (20分)
2.2.1代码截图
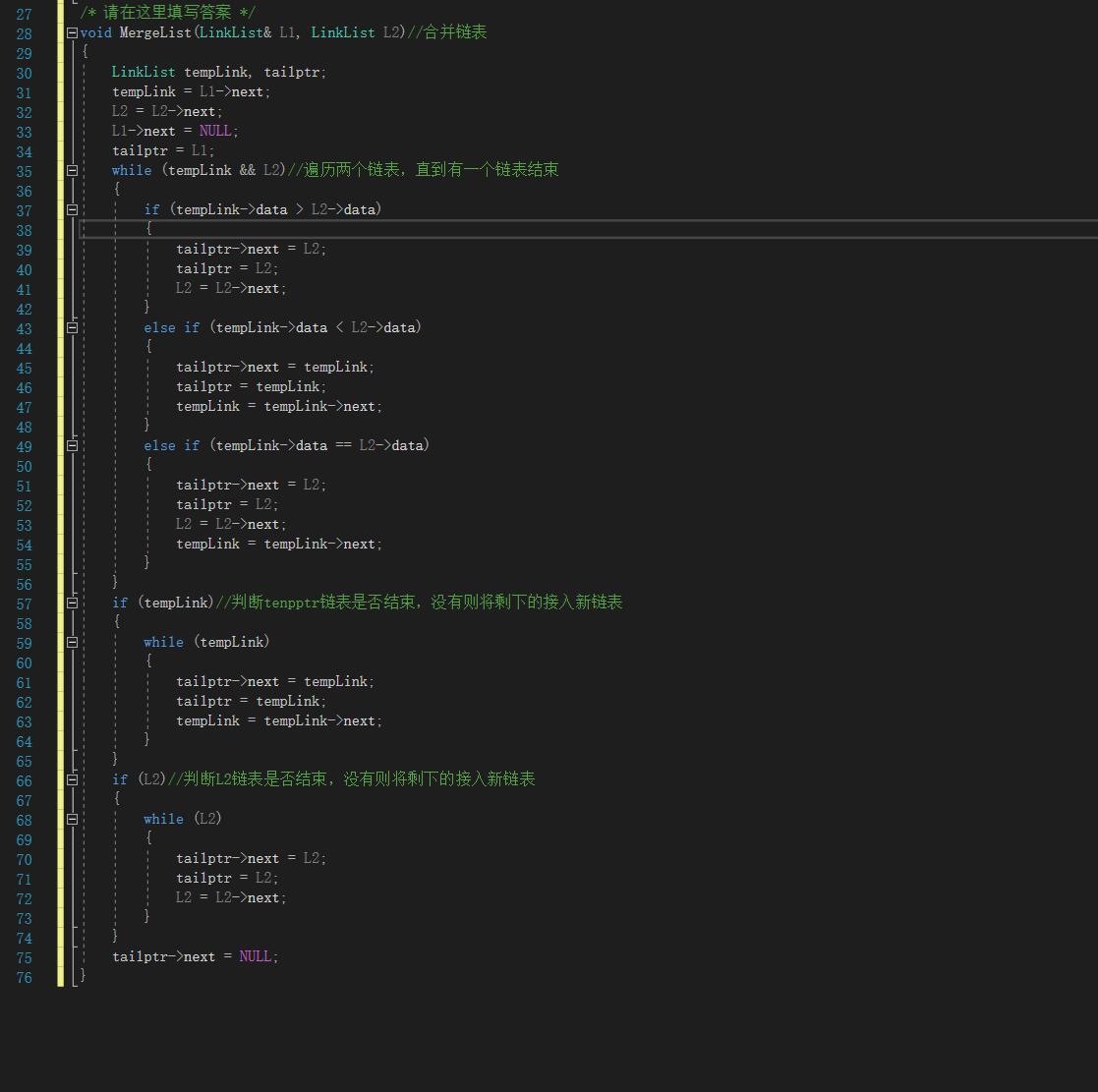
2.2.2 本题PTA提交列表说明
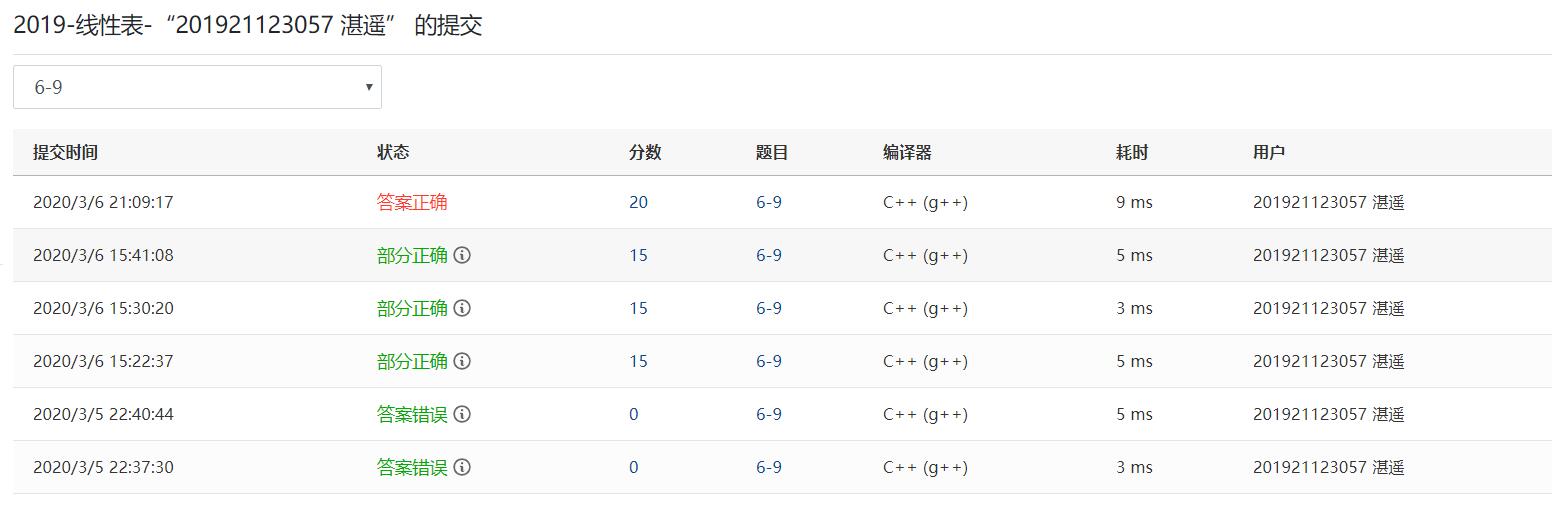
答案错误:考虑的是两个链表一样长时的情况,没有考虑一条走完,另一条还有的情况。解决:在后面判断两个链表是否已经到了尾部,没到则将剩下的接到新链表上;
部分正确:第二次错误则是看错题意,题目写的是“合并后需要去除重复元素”,我理解的就是要去除重复的元素,自然就错了。后面将重复元素写一个进去就好啦,
2.3 题目三:7-1 两个有序序列的中位数 (25分)
2.3.1 代码截图

2.3.2本题PTA提交列表说明
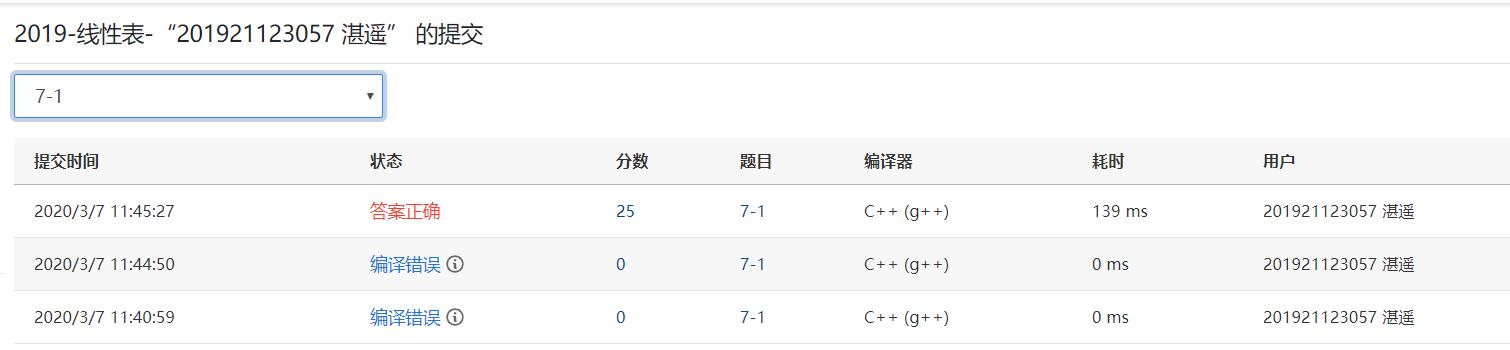
在做本题时,一开始想到的是将两个链表合并在一起后,找出它的中位数。在课上老师的讲解后,有了这种做法,时间比以前节省了不少,也节省了空间
编译错误则是PTA不能用void main导致的
3.阅读代码
3.1题目及解题代码
链表的中间节点(leetcode 876)

3.1.1 该题的设计思路

时间复杂度:O(n)
空间复杂度:O(1)
3.1.2 该题的伪代码
新建快指针fast;
新建慢指针slow;
while 判断快指针及快指针的下一节点是否为空 //快指针为空,慢指针则指到中间位置
慢指针指向下一节点;
快指针是慢指针速度的两倍;
return 慢指针
3.1.3运行结果

3.1.4分析该题目解题优势及难点
本来的这题我以为是跟pta上找倒数第几个数的做法类似的,但却不能用一个指针先去移,因为并不知道它的中间节点在哪。
按平常做法来的话,也可以先遍历一遍,再找出它的中间节点,但时间明显比这种做法多了一些。
这种快慢指针的做法,只需要遍历一遍,就可以找出它的中间节点。以后再遇到这种找他的哪个位置节点呀,这种方法倒简便了不少
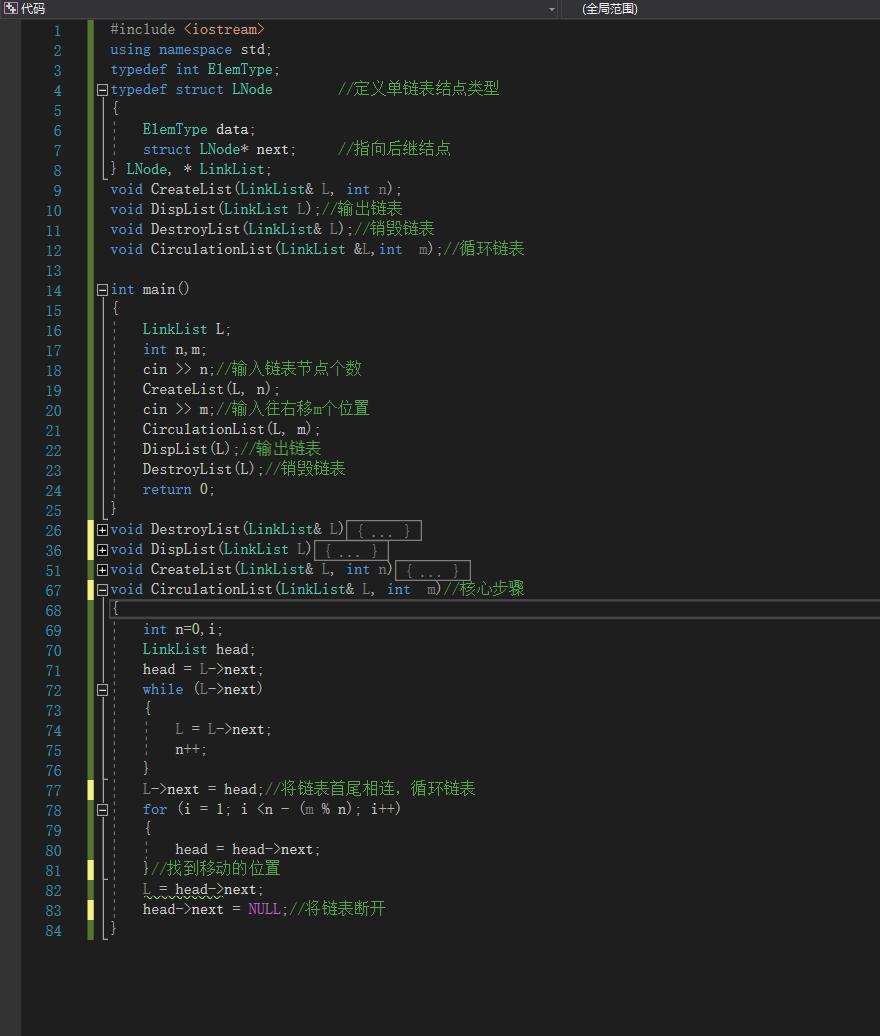
3.1题目及解题代码
题目:

解题代码:
3.1.1 该题的设计思路
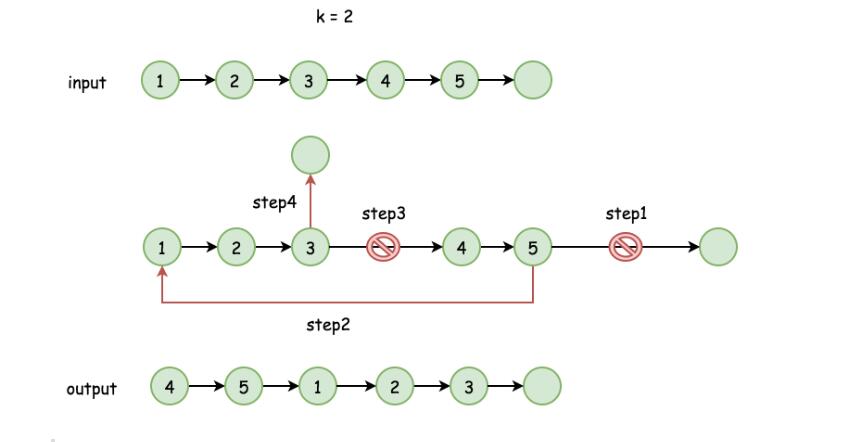
时间复杂度:O(N)
空间复杂度:O(1)
3.1.2 该题的伪代码
void CirculationList(LinkList& L, int m)
{
保存开头节点;
while遍历L到尾部
n++; //保存节点个数
L->next=head; //将链表首尾相连,循环链表
for 找到移动的位置
L = head->next;
head->next = NULL;//将链表断开
}
3.1.3运行结果

3.1.4分析该题目解题优势及难点

上面这种做法就是以往拿数组的方法来做的,时间复杂度为O(n2),用循环链表来做,时间复杂度便降了一个维度,大大提高效率;
该做法难点就是在找移动的节点时,容易找错;并且我这种做法做完时,是没有头结点的,输出时需要注意下;

