
Netty 编解码奥秘
Netty中编解码
Netty 的解码器有很多种,比如基于长度的,基于分割符的,私有协议的。但是,总体的思路都是一致的。
拆包思路:当数据满足了 解码条件时,将其拆开。放到数组。然后发送到业务 handler 处理。
半包思路: 当读取的数据不够时,先存起来,直到满足解码条件后,放进数组。送到业务 handler 处理。
拆包的原理
在没有netty的情况下,用户如果自己需要拆包,基本原理就是不断从TCP缓冲区中读取数据,每次读取完都需要判断是否是一个完整的数据包
- 如果当前读取的数据不足以拼接成一个完整的业务数据包,那就保留该数据,继续从tcp缓冲区中读取,直到得到一个完整的数据包
- 如果当前读到的数据加上已经读取的数据足够拼接成一个数据包,那就将已经读取的数据拼接上本次读取的数据,够成一个完整的业务数据包传递到业务逻辑,多余的数据仍然保留,以便和下次读到的数据尝试拼接
Netty中拆包的基类
Netty提供的解码器都继承于ByteToMessageDecoder,下面是ByteToMessageDecoder的uml图

netty 中的拆包也是如上这个原理,在每个SocketChannel中会一个 pipeline ,pipeline 内部会加入解码器,解码器都继承基类 ByteToMessageDecoder,其内部会有一个累加器,每次从当前SocketChannel读取到数据都会不断累加,然后尝试对累加到的数据进行拆包,拆成一个完整的业务数据包,下面我们先详细分析下这个类
看名字的意思是:将字节转换成消息的解码器。人如其名。而他本身也是一个入站 handler,所以,我们还是从他的 channelRead 方法入手。
channelRead 方法
我们先看看基类中的属性,cumulation是此基类中的一个 ByteBuf 类型的累积区,每次从当前SocketChannel读取到数据都会不断累加,然后尝试对累加到的数据进行拆包,拆成一个完整的业务数据包,如果不够一个完整的数据包,则等待下一次从TCP的数据到来,继续累加到此cumulation中
public abstract class ByteToMessageDecoder extends ChannelInboundHandlerAdapter {
//累积区
ByteBuf cumulation;
private ByteToMessageDecoder.Cumulator cumulator;
private boolean singleDecode;
private boolean decodeWasNull;
private boolean first;
private int discardAfterReads;
private int numReads;
.
.
.
}
channelRead方法是每次从TCP缓冲区读到数据都会调用的方法,触发点在AbstractNioByteChannel的read方法中,里面有个while循环不断读取,读取到一次就触发一次channelRead
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
if (msg instanceof ByteBuf) {
// 从对象池中取出一个List
CodecOutputList out = CodecOutputList.newInstance();
try {
ByteBuf data = (ByteBuf) msg;
first = cumulation == null;
if (first) {
// 第一次解码
cumulation = data;//直接赋值
} else {
// 第二次解码,就将 data 向 cumulation 追加,并释放 data
cumulation = cumulator.cumulate(ctx.alloc(), cumulation, data);
}
// 得到追加后的 cumulation 后,调用 decode 方法进行解码
// 主要目的是将累积区cumulation的内容 decode 到 out数组中
callDecode(ctx, cumulation, out);
} catch (DecoderException e) {
throw e;
} catch (Throwable t) {
throw new DecoderException(t);
} finally {
// 如果累计区没有可读字节了,有可能在上面callDecode方法中已经将cumulation全部读完了,此时writerIndex==readerIndex
// 每读一个字节,readerIndex会+1
if (cumulation != null && !cumulation.isReadable()) {
// 将次数归零
numReads = 0;
// 释放累计区,因为累计区里面的字节都全部读完了
cumulation.release();
// 便于 gc
cumulation = null;
// 如果超过了 16 次,还有字节没有读完,就将已经读过的数据丢弃,将 readIndex 归零。
} else if (++ numReads >= discardAfterReads) {
numReads = 0;
//将已经读过的数据丢弃,将 readIndex 归零。
discardSomeReadBytes();
}
int size = out.size();
decodeWasNull = !out.insertSinceRecycled();
//循环数组,向后面的 handler 发送数据
fireChannelRead(ctx, out, size);
out.recycle();
}
} else {
ctx.fireChannelRead(msg);
}
}
- 从对象池中取出一个空的数组。
- 判断成员变量是否是第一次使用,将 unsafe 中传递来的数据写入到这个 cumulation 累积区中。
- 写到累积区后,在callDecode方法中调用子类的 decode 方法,尝试将累积区的内容解码,每成功解码一个,就调用后面节点的 channelRead 方法。若没有解码成功,什么都不做。
- 如果累积区没有未读数据了,就释放累积区。
- 如果还有未读数据,且解码超过了 16 次(默认),就对累积区进行压缩。将读取过的数据清空,也就是将 readIndex 设置为0.
- 调用 fireChannelRead 方法,将数组中的元素发送到后面的 handler 中。
- 将数组清空。并还给对象池。
下面来说说详细的步骤。
写入累积区
如果当前累加器没有数据,就直接跳过内存拷贝,直接将字节容器的指针指向新读取的数据,否则,调用累加器累加数据至字节容器
ByteBuf data = (ByteBuf) msg;
first = cumulation == null;
if (first) {
cumulation = data;
} else {
cumulation = cumulator.cumulate(ctx.alloc(), cumulation, data);
}
我们看看构造方法
protected ByteToMessageDecoder() {
this.cumulator = MERGE_CUMULATOR;
this.discardAfterReads = 16;
CodecUtil.ensureNotSharable(this);
}
可以看到 this.cumulator = MERGE_CUMULATOR;,那我们接下来看看 MERGE_CUMULATOR
public static final ByteToMessageDecoder.Cumulator MERGE_CUMULATOR = new ByteToMessageDecoder.Cumulator() {
public ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) {
ByteBuf buffer;
if (cumulation.writerIndex() <= cumulation.maxCapacity() - in.readableBytes() && cumulation.refCnt() <= 1) {
buffer = cumulation;
} else {
buffer = ByteToMessageDecoder.expandCumulation(alloc, cumulation, in.readableBytes());
}
buffer.writeBytes(in);
in.release();
return buffer;
}
};
MERGE_CUMULATOR是基类ByteToMessageDecoder中的一个静态常量,其重写了cumulate方法,下面我们看一下 MERGE_CUMULATOR 是如何将新读取到的数据累加到字节容器里的
netty 中ByteBuf的抽象,使得累加非常简单,通过一个简单的api调用 buffer.writeBytes(in); 便将新数据累加到字节容器中,为了防止字节容器大小不够,在累加之前还进行了扩容处理
static ByteBuf expandCumulation(ByteBufAllocator alloc, ByteBuf cumulation, int readable) {
ByteBuf oldCumulation = cumulation;
cumulation = alloc.buffer(oldCumulation.readableBytes() + readable);
cumulation.writeBytes(oldCumulation);
oldCumulation.release();
return cumulation;
}
扩容也是一个内存拷贝操作,新增的大小即是新读取数据的大小
将累加到的数据传递给业务进行拆包
当数据追加到累积区之后,需要调用 decode 方法进行解码,代码如下:
public boolean isReadable() {
//写的坐标大于读的坐标则说明还有数据可读
return this.writerIndex > this.readerIndex;
}
protected void callDecode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {
// 如果累计区还有可读字节,循环解码,因为这里in有可能是粘包,即多次完整的数据包粘在一起,通过换行符连接
// 下面的decode方法只能处理一个完整的数据包,所以这里循环处理粘包
while (in.isReadable()) {
int outSize = out.size();
// 上次循环成功解码
if (outSize > 0) {
// 处理一个粘包就 调用一次后面的业务 handler 的 ChannelRead 方法
fireChannelRead(ctx, out, outSize);
// 将 size 置为0
out.clear();//
if (ctx.isRemoved()) {
break;
}
outSize = 0;
}
// 得到可读字节数
int oldInputLength = in.readableBytes();
// 调用 decode 方法,将成功解码后的数据放入道 out 数组中
decode(ctx, in, out);
if (ctx.isRemoved()) {
break;
}
if (outSize == out.size()) {
if (oldInputLength == in.readableBytes()) {
break;
} else {
continue;
}
}
if (isSingleDecode()) {
break;
}
}
}
我们看看 fireChannelRead
static void fireChannelRead(ChannelHandlerContext ctx, List<Object> msgs, int numElements) {
if (msgs instanceof CodecOutputList) {
fireChannelRead(ctx, (CodecOutputList)msgs, numElements);
} else {
//将所有已解码的数据向下业务hadder传递
for(int i = 0; i < numElements; ++i) {
ctx.fireChannelRead(msgs.get(i));
}
}
}
该方法主要逻辑:只要累积区还有未读数据,就循环进行读取。
- 调用 decodeRemovalReentryProtection 方法,内部调用了子类重写的 decode 方法,很明显,这里是个模板模式。decode 方法的逻辑就是将累积区的内容按照约定进行解码,如果成功解码,就添加到数组中。同时该方法也会检查该 handler 的状态,如果被移除出 pipeline 了,就将累积区的内容直接刷新到后面的 handler 中。
- 如果 Context 节点被移除了,直接结束循环。如果解码前的数组大小和解码后的数组大小相等,且累积区的可读字节数没有变化,说明此次读取什么都没做,就直接结束。如果字节数变化了,说明虽然数组没有增加,但确实在读取字节,就再继续读取。
- 如果上面的判断过了,说明数组读到数据了,但如果累积区的 readIndex 没有变化,则抛出异常,说明没有读取数据,但数组却增加了,子类的操作是不对的。
- 如果是个单次解码器,解码一次就直接结束了,如果数据包一次就解码完了,则下一次循环时 in.isReadable()就为false,因为 writerIndex = this.readerIndex 了
所以,这段代码的关键就是子类需要重写 decode 方法,将累积区的数据正确的解码并添加到数组中。每添加一次成功,就会调用 fireChannelRead 方法,将数组中的数据传递给后面的 handler。完成之后将数组的 size 设置为 0.
所以,如果你的业务 handler 在这个地方可能会被多次调用。也可能一次也不调用。取决于数组中的值。
「解码器最主要的逻辑」:
❝将 read 方法的数据读取到累积区,使用解码器解码累积区的数据,解码成功一个就放入到一个数组中,并将数组中的数据一次次的传递到后面的handler。
❞
清理字节容器
业务拆包完成之后,只是从累积区中取走了数据,但是这部分空间对于累积区来说依然保留着,而字节容器每次累加字节数据的时候都是将字节数据追加到尾部,如果不对累积区做清理,那么时间一长就会OOM,清理部分的代码如下
finally {
// 如果累计区没有可读字节了,有可能在上面callDecode方法中已经将cumulation全部读完了,此时writerIndex==readerIndex
// 每读一个字节,readerIndex会+1
if (cumulation != null && !cumulation.isReadable()) {
// 将次数归零
numReads = 0;
// 释放累计区,因为累计区里面的字节都全部读完了
cumulation.release();
// 便于 gc
cumulation = null;
// 如果超过了 16 次,还有字节没有读完,就将已经读过的数据丢弃,将 readIndex 归零。
} else if (++ numReads >= discardAfterReads) {
numReads = 0;
//将已经读过的数据丢弃,将 readIndex 归零。
discardSomeReadBytes();
}
int size = out.size();
decodeWasNull = !out.insertSinceRecycled();
//循环数组,向后面的 handler 发送数据
fireChannelRead(ctx, out, size);
out.recycle();
}
- 如果累积区没有可读数据了,将计数器归零,并释放累积区。
- 如果不满足上面的条件,且计数器超过了 16 次,就压缩累积区的内容,压缩手段是删除已读的数据。将 readIndex 置为 0。还记得 ByteBuf 的指针结构吗?
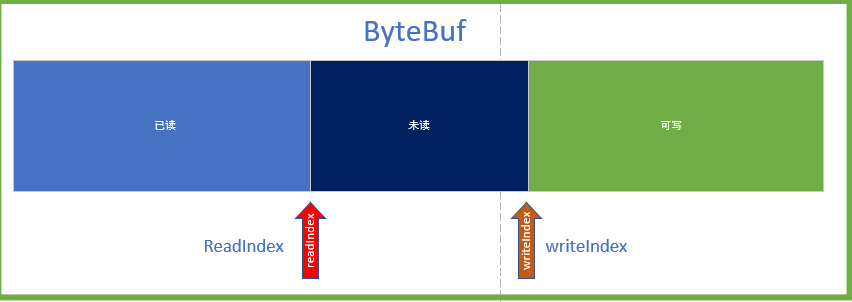 ByteBuf
ByteBuf
public ByteBuf discardSomeReadBytes() {
this.ensureAccessible();
if (this.readerIndex == 0) {
return this;
} else if (this.readerIndex == this.writerIndex) {
this.adjustMarkers(this.readerIndex);
this.writerIndex = this.readerIndex = 0;
return this;
} else {
//读指针超过了Buffer容量的一半时做清理工作
if (this.readerIndex >= this.capacity() >>> 1) {
//拷贝,从readerIndex开始,拷贝this.writerIndex - this.readerIndex 长度
this.setBytes(0, this, this.readerIndex, this.writerIndex - this.readerIndex);
//writerIndex=writerIndex-readerIndex
this.writerIndex -= this.readerIndex;
this.adjustMarkers(this.readerIndex);
//将读指针重置为0
this.readerIndex = 0;
}
return this;
}
}
我们看到discardSomeReadBytes 主要是将未读的数据拷贝到原Buffer,重置 readerIndex 和 writerIndex
我们看到最后还调用 fireChannelRead 方法,尝试将数组中的数据发送到后面的 handler。为什么要这么做。按道理,到这一步的时候,数组不可能是空,为什么这里还要这么谨慎的再发送一次?
如果是单次解码器,就需要发送了,因为单词解码器是不会在 callDecode 方法中发送的。
总结
可以说,ByteToMessageDecoder 是解码器的核心所做,Netty 在这里使用了模板模式,留给子类扩展的方法就是 decode 方法。
主要逻辑就是将所有的数据全部放入累积区,子类从累积区取出数据进行解码后放入到一个 数组中,ByteToMessageDecoder 会循环数组调用后面的 handler 方法,将数据一帧帧的发送到业务 handler 。完成这个的解码逻辑。
使用这种方式,无论是粘包还是拆包,都可以完美的实现。
Netty 所有的解码器,都可以在此类上扩展,一切取决于 decode 的实现。只要遵守 ByteToMessageDecoder 的约定即可。下篇文章给大家列举常用的解码器。
结束
❝识别下方二维码!回复: 「
❞入群」 ,扫码加入我们交流群!

 点赞是认可,在看是支持
点赞是认可,在看是支持



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?