python3爬虫-1.简单介绍及入门
网络爬虫是捜索引擎(Baidu、Google、Yahoo)抓取系统的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
网络爬虫的基本工作流程如下:
- 首先选取一部分精心挑选的种子URL;
- 将这些URL放入待抓取URL队列;
- 从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
- 分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。

爬虫是 模拟用户在浏览器或者某个应用上的操作,把操作的过程、实现自动化的程序
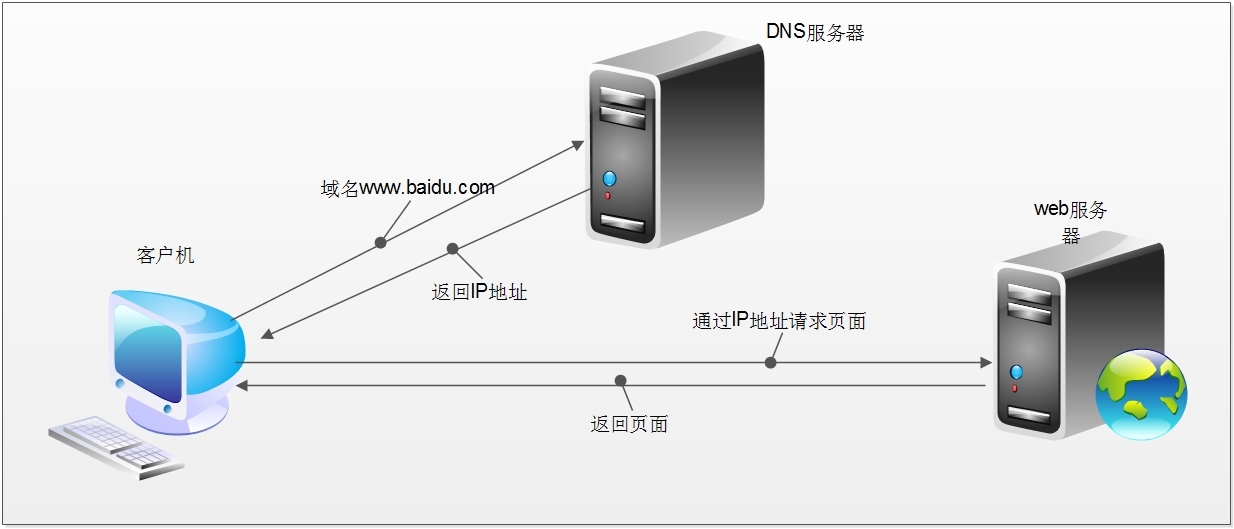
当我们在浏览器中输入一个url后回车,后台会发生什么?比如说你输入http://www.sina.com.cn/
简单来说这段过程发生了以下四个步骤:
-
查找域名对应的IP地址。
-
向IP对应的服务器发送请求。
-
服务器响应请求,发回网页内容。
-
浏览器解析网页内容。
网络爬虫本质
本质就是浏览器http请求
浏览器和网络爬虫是两种不同的网络客户端,都以相同的方式来获取网页:
网络爬虫要做的,简单来说,就是实现浏览器的功能。通过指定url,直接返回给用户所需要的数据, 而不需要一步步人工去操纵浏览器获取。
浏览器是如何发送和接收这个数据呢?
HTTP简介
HTTP协议(HyperText Transfer Protocol,超文本传输协议)目的是为了提供一种发布和接收HTML(HyperText Markup Language)页面的方法。
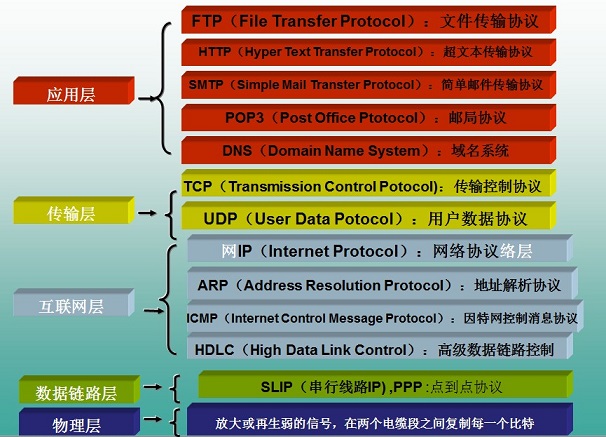
HTTP协议所在的协议层(了解)
HTTP是基于TCP协议之上的。在TCP/IP协议参考模型的各层对应的协议如下图,其中HTTP是应用层的协议。 默认HTTP的端口号为80,HTTPS的端口号为443。
HTTP工作过程
一次HTTP操作称为一个事务,其工作整个过程如下:
1 ) 、地址解析,
如用客户端浏览器请求这个页面:http://localhost.com:8080/index.htm
从中分解出协议名、主机名、端口、对象路径等部分,对于我们的这个地址,解析得到的结果如下: 协议名:http 主机名:localhost.com 端口:8080 对象路径:/index.htm
在这一步,需要域名系统DNS解析域名localhost.com,得主机的IP地址。
2)、封装HTTP请求数据包
把以上部分结合本机自己的信息,封装成一个HTTP请求数据包
3)封装成TCP包,建立TCP连接(TCP的三次握手)
在HTTP工作开始之前,客户机(Web浏览器)首先要通过网络与服务器建立连接,该连接是通过TCP来完成的,该协议与IP协议共同构建Internet,即著名的TCP/IP协议族,因此Internet又被称作是TCP/IP网络。HTTP是比TCP更高层次的应用层协议,根据规则,只有低层协议建立之后才能,才能进行更层协议的连接,因此,首先要建立TCP连接,一般TCP连接的端口号是80。这里是8080端口
4)客户机发送请求命令
建立连接后,客户机发送一个请求给服务器,请求方式的格式为:统一资源标识符(URL)、协议版本号,后边是MIME信息包括请求修饰符、客户机信息和可内容。
5)服务器响应
服务器接到请求后,给予相应的响应信息,其格式为一个状态行,包括信息的协议版本号、一个成功或错误的代码,后边是MIME信息包括服务器信息、实体信息和可能的内容。
实体消息是服务器向浏览器发送头信息后,它会发送一个空白行来表示头信息的发送到此为结束,接着,它就以Content-Type应答头信息所描述的格式发送用户所请求的实际数据
6)服务器关闭TCP连接
一般情况下,一旦Web服务器向浏览器发送了请求数据,它就要关闭TCP连接,然后如果浏览器或者服务器在其头信息加入了这行代码
Connection:keep-alive
TCP连接在发送后将仍然保持打开状态,于是,浏览器可以继续通过相同的连接发送请求。保持连接节省了为每个请求建立新连接所需的时间,还节约了网络带宽。
HTTPS
HTTPS(全称:Hypertext Transfer Protocol over Secure Socket Layer),是以安全为目标的HTTP通道,简单讲是HTTP的安全版。即HTTP下加入SSL层,HTTPS的安全基础是SSL。其所用的端口号是443。
SSL:安全套接层,是netscape公司设计的主要用于web的安全传输协议。这种协议在WEB上获得了广泛的应用。通过证书认证来确保客户端和网站服务器之间的通信数据是加密安全的。
有两种基本的加解密算法类型:
1)对称加密(symmetrcic encryption):密钥只有一个,加密解密为同一个密码,且加解密速度快,典型的对称加密算法有DES、AES,RC5,3DES等;
对称加密主要问题是共享秘钥,除你的计算机(客户端)知道另外一台计算机(服务器)的私钥秘钥,否则无法对通信流进行加密解密。解决这个问题的方案非对称秘钥。
2)非对称加密:使用两个秘钥:公共秘钥和私有秘钥。私有秘钥由一方密码保存(一般是服务器保存),另一方任何人都可以获得公共秘钥。
这种密钥成对出现(且根据公钥无法推知私钥,根据私钥也无法推知公钥),加密解密使用不同密钥(公钥加密需要私钥解密,私钥加密需要公钥解密),相对对称加密速度较慢,典型的非对称加密算法有RSA、DSA等。
https通信的优点:
- 客户端产生的密钥只有客户端和服务器端能得到;
- 加密的数据只有客户端和服务器端才能得到明文;
- 客户端到服务端的通信是安全的。
爬虫实例
-
IDEA为pycharm
-
python版本3.8
在Python3.x中,我们可以使用urlib这个组件抓取网页,urllib是一个URL处理包,这个包中集合了一些处理URL的模块,如下:
1.urllib.request模块是用来打开和读取URLs的;
2.urllib.error模块包含一些有urllib.request产生的错误,可以使用try进行捕捉处理;
3.urllib.parse模块包含了一些解析URLs的方法;
4.urllib.robotparser模块用来解析robots.txt文本文件.它提供了一个单独的RobotFileParser类,通过该类提供的can_fetch()方法测试爬虫是否可以下载一个页面
我们使用urllib.request.urlopen()这个接口函数就可以很轻松的打开一个网站,读取并打印信息。
urllib使用使用request.urlopen()打开和读取URLs信息,返回的对象response如同一个文本对象,
我们可以调用read(),进行读取。再通过print(),将读到的信息打印出来。
from urllib import request
if __name__=="__main__":
response=request.urlopen("http://fanyi.baidu.com")
html=response.read()
html=html.decode("utf-8")
print(html)

我们可以通过简单的decode()命令将网页的信息进行解码,并显示出来
from urllib import request
if __name__=="__main__":
response=request.urlopen("http://fanyi.baidu.com")
html=response.read()
html=html.decode("utf-8")#添加编码
print(html)
爬取的数据就很工整了

当然这个前提是我们已经知道了这个网页是使用utf-8编码的,怎么查看网页的编码方式呢?
需要人为操作,且非常简单的方法是使用使用浏览器审查元素,只需要找到head标签开始位置的chareset,就知道网页是采用何种编码的了。
可不可以自动获取编码呢,当然,爬虫就是模仿人的行为的
自动获取网页编码方式的方法
获取编码需要先安装包chardet
安装好后,我们就可以使用chardet.detect()方法,判断网页的编码方式了。
from urllib import request
import chardet
if __name__=="__main__":
response=request.urlopen("http://fanyi.baidu.com")
html=response.read()
charset=chardet.detect(html) #判断网页编码
print(charset)#输出判断数据
可以看到输出的是一个字典

因此可以将代码改为
from urllib import request
import chardet
if __name__=="__main__":
response=request.urlopen("http://fanyi.baidu.com")
html=response.read()
charset=chardet.detect(html)
html=html.decode(charset["encoding"])
print(html)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号