
Python爬虫出错
出错内容1:
Traceback (most recent call last): File "E:\python_workplace\Python实验\实验四\test4_2\豆瓣评分.py", line 104, in <module> main(bookId, 60, 3, 'hot') File "E:\python_workplace\Python实验\实验四\test4_2\豆瓣评分.py", line 64, in main soup = BeautifulSoup(html, 'html.parser') File "E:\python_workplace\venv\lib\site-packages\bs4\__init__.py", line 275, in __init__ elif len(markup) <= 256 and ( TypeError: object of type 'NoneType' has no len()
出错原因:由于爬取的是豆瓣的网站,豆瓣具有反爬取机制,所以这需要伪装成浏览器
修改方式:
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"} html = requests.get(url=url,headers=headers) soup = BeautifulSoup(html, 'lxml')
接下来之前的错误消失,出现下面的错误
出错内容2:
Traceback (most recent call last): File "E:\python_workplace\Python实验\实验四\test4_2\豆瓣评分.py", line 102, in <module> main(bookId, 60, 3, 'hot') File "E:\python_workplace\Python实验\实验四\test4_2\豆瓣评分.py", line 62, in main soup = BeautifulSoup(html, 'lxml') File "E:\python_workplace\venv\lib\site-packages\bs4\__init__.py", line 275, in __init__ elif len(markup) <= 256 and ( TypeError: object of type 'Response' has no len()
出错位置:
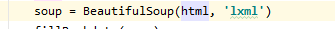
修改为:
soup = BeautifulSoup(html, 'lxml')
修改后结果:



