
对result文件进行数据清洗以及进行可视化
项目源码地址:https://github.com/gayu121/result(项目里操作的数据都是清洗过后的数据)
测试要求:
1、 数据清洗:按照进行数据清洗,并将清洗后的数据导入hive数据库中。
两阶段数据清洗:
(1)第一阶段:把需要的信息从原始日志中提取出来
(2)第二阶段:根据提取出来的信息做精细化操作
(3)hive数据库表结构:
create table data( ip string, time string , day string, traffic bigint,
type string, id string )
2、数据处理:
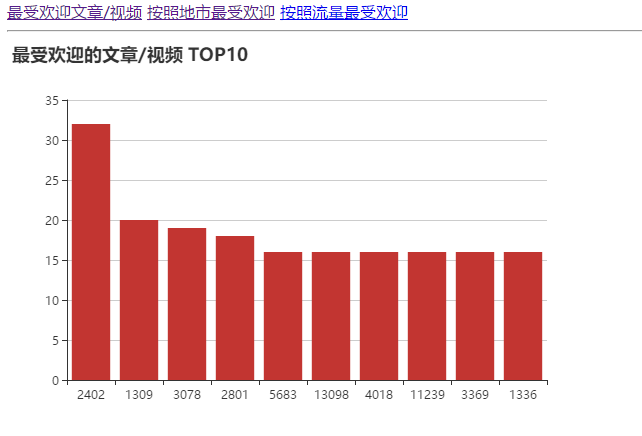
·统计最受欢迎的视频/文章的Top10访问次数 (video/article)
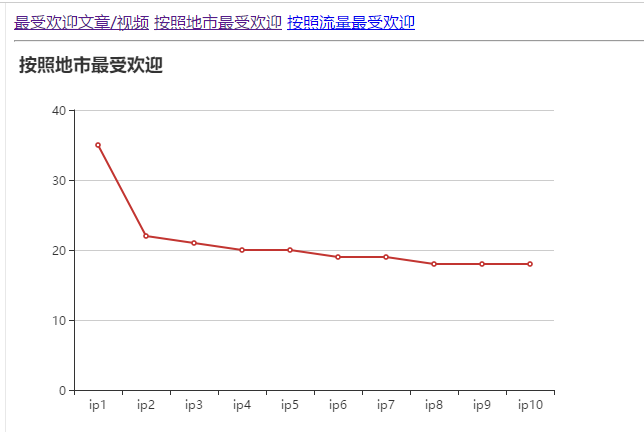
·按照地市统计最受欢迎的Top10课程 (ip)
·按照流量统计最受欢迎的Top10课程 (traffic)
3、数据可视化:将统计结果倒入MySql数据库中,通过图形化展示的方式展现出来。
由于所给的文件是一个TXT文档,数据项之间用逗号隔开,格式如图:
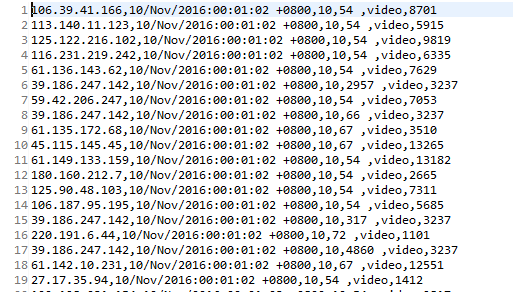
所以需要对数据首先进行清洗,变为用Tab建作为分隔的数据项,在此我弄了很久找不到合适的方法,在同学的指点下使用排序的算法,以id为数据项进行了排序,将数据清洗为要求格式,第二阶段的细化过程也就同理了,在这里附上细化使用的代码
package test3; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class Order2 { public static class Map extends Mapper<Object , Text , IntWritable,Text >{ private static Text goods=new Text(); private static IntWritable num=new IntWritable(); public void map(Object key,Text value,Context context) throws IOException, InterruptedException{ String line=value.toString(); String arr[]=line.split("[\t/:]" ); //主要就是根据这几个特殊字符进行分割,然后按照下面的格式输出到指定文件 num.set(Integer.parseInt(arr[0])); goods.set(arr[1] + "\t" + arr[4] +"-11-10" +" " + arr[5] +":" + arr[6]+":" +arr[7] +"\t"+ arr[8] + "\t" + arr[9] + "\t"+arr[10] ); context.write(num,goods); } } public static class Reduce extends Reducer< IntWritable, Text, IntWritable, Text>{ private static IntWritable result= new IntWritable(); public void reduce(IntWritable key,Iterable<Text> values,Context context) throws IOException, InterruptedException{ for(Text val:values){ context.write(key,val); } } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{ Configuration conf=new Configuration(); Job job =new Job(conf,"OneSort"); job.setJarByClass(Order.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setOutputKeyClass(IntWritable.class); job.setOutputValueClass(Text.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); Path in=new Path("hdfs://192.168.43.102:9000/test/res1/part-r-00000"); Path out=new Path("hdfs://192.168.43.102:9000/test/res2"); FileInputFormat.addInputPath(job,in); FileOutputFormat.setOutputPath(job,out); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
然后第二问就是利用一个MapReduce的统计的方法,针对不同的条件进行计数,然后利用排序算法进行排序,这一块儿的代码在项目里都有,感性趣的话可以到github里下载。
然后在可视化是遇到了一些问题,就是对于那个城市的IP(估计是由于字符太长,无法在echarts中显示)可以打印输出就是不能生成表格,所以那些数据项我就用IP1.....代替了。还有一个问题就是在根据字符串循环时老是说我数组越界,然后我就自己写了一个循环,只有10个数据元,就解决了。
以下是可视化的截图(我用了echarts中的三种显示形式):
柱状图:
折线图:
饼状图:


