实验6:Mapreduce实例——WordCount
- 启动hadoop。
Start-dfs.sh
- 创建在系统中创建一个的TXT文件,并将上面的数据包复制到文件中
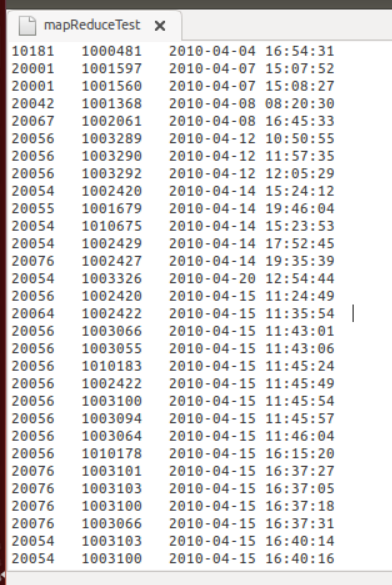
- 将写好的文件从本地上传到hadoop上
(1)进入hadoop目录

(2)上传文件

- 在eclipse中创建MapReduce程序命名为count,然后导入相关的jar包

然后还需要导入三个配置文件:其中log4j.properties是一个日志文件,如果没有这个文件程序就不会正常运行
代码:WordCount java
package test6;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance();
job.setJobName("WordCount");
job.setJarByClass(WordCount.class);
job.setMapperClass(doMapper.class);
job.setReducerClass(doReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
Path in = new Path("hdfs://192.168.43.102:9000/user/hadoop/input/mapReduceTest2.txt");
Path out = new Path("hdfs://192.168.43.102:9000/user/hadoop/output5");
FileInputFormat.addInputPath(job, in);
FileOutputFormat.setOutputPath(job, out);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
public static class doMapper extends Mapper<Object, Text, Text, IntWritable>{
public static final IntWritable one = new IntWritable(1);
public static Text word = new Text();
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer tokenizer = new StringTokenizer(value.toString(), " ");
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
public static class doReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
result.set(sum);
context.write(key, result);
}
}
}
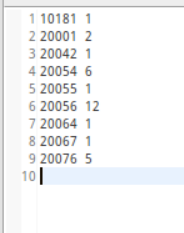
实验结果: