记录一次修复知网学位论文目录下载油猴脚本的过程
最近使用油猴脚本下载知网学位论文时发现脚本不能正常的下载目录了,因此手动修复一下这个脚本。
通过查看脚本源码和网上搜索发现,脚本使用了jQuery以及油猴的部分接口(比如:GM_xmlhttpRequest,GM_setClipboard等)
在分析源码和查阅脚本的说明后,发现脚本是通过获取知网【分章下载】的网页源码得到每个目录信息的,借助 console.log() 打印GM_xmlhttpRequest请求url发现,知网对分章下载的页面地址进行了更改,脚本原来的请求格式是:
https://chn.oversea.cnki.net/kcms/download.aspx?dbcode=CMFD&dbname=CMFD202102&filename=论文ID.nh
现在改版后的请求格式为:
https://chn.oversea.cnki.net/kcms/detail/downdetail.aspx?dbcode=CMFD&dbname=CMFD202102&filename=论文ID.nh
如果使用原来的请求格式会被知网拒绝放访问,提示错误
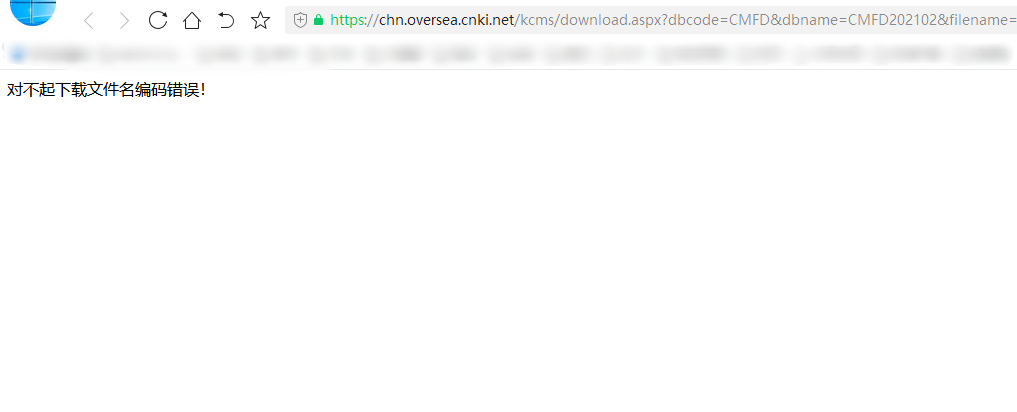
于是第一步是修改目录请求url的生成语句,将第81行的语句修改成为
content_url = 'https://chn.oversea.cnki.net/kcms/detail/downdetail.aspx' + content_url.match(/\?.*/)[0];
即可,下图为修改前后对比。
修改前:
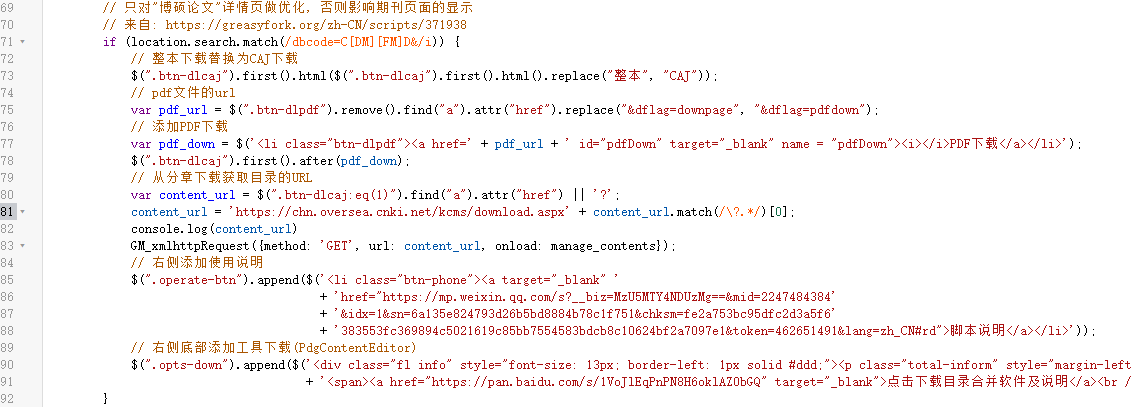
修改后:

完成目录页面请求链接修复后,我发现目录下载功能仍然能正常使用,通过查看源码中目录文字生成程序段发现,脚本使用了jQuery完成网页信息的解析。显然,目前页面获取后仍然没能解析出目录信息的原因大概率是知网对页面结构进行了改版,原先的解析方法无法完成新版网页的内容解析,因此,我通过查阅W3school jQuery 选择器的相关介绍,重新修改了目录内容的解析程序,关键参考程序段如下:
function manage_contents(xhr) {
// 这段程序主要修改了下面2行
var cnt_list = $('ul.list-main', xhr.responseText)[0]; // 目录列表
cnt_list = $('li', cnt_list);
var contents = get_content(cnt_list); // 目录内容
// 添加目录复制
$('.btn-dlpdf').first().after($('<li class="btn-dlpdf"><a href="javascript:void(0);">目录复制</a></li>').click(function() {
GM_setClipboard(contents); // 运用油猴脚本自带的复制函数
window.alert('目录已复制到剪贴板');
}));
// 添加目录下载
$('.btn-dlpdf').first().after($('<li class="btn-dlcaj"><a>目录下载</a></li>').click(function() {
var data = new Blob([contents],{type:"text/plain; charset=UTF-8"});
$(this).find('a').attr("download", '目录_' + $('.wx-tit h1:first-child()').text().trim() + '.txt');
$(this).find('a').attr("href", window.URL.createObjectURL(data));
window.URL.revokeObjectURL(data);
window.alert("目录索引已保存, 请使用PdgCntEditor软件将目录整合到PDF中");
}));
}
另一个修改的地方如下:
function get_content(cnt_list){
var contents = "";
for (var i = 0; i < cnt_list.length; i++) {
var cnt_level = cnt_list[i].getAttribute("class").split("-")[1];
var cnt_levelText="";
for (var j = 0; j< cnt_level; j++){
cnt_levelText = cnt_levelText+"\t";
}
var cnt_item = cnt_list[i].childNodes[1].childNodes[1];
cnt_item = cnt_levelText + cnt_item.innerText;
var cnt_page = cnt_list[i].childNodes[1].childNodes[2].textContent.trim().split("-")[0]; // 知网的目录给的是个范围, 正常只需要前半部分
contents = contents + cnt_item + "\t" + cnt_page + "\r\n";
}
return contents;
}
以上程序段修改的地方较多,所以放出原程序段在下方,方便对比。
原程序段:
function get_content(cnt_list){
var contents = "";
for (var i = 0; i < cnt_list.length - 1; i++) { // 长度减一, 因为最后一个是text
var cnt_item = cnt_list[i].childNodes[1].childNodes[1];
cnt_item = cnt_item.innerHTML;
var cnt_page = cnt_list[i].childNodes[3].childNodes[0].textContent.trim().split("-")[0]; // 知网的目录给的是个范围, 正常只需要前半部分
contents = contents + cnt_item.trim().replace(/ /g, " ").replace(/ {4}/g, "\t") + "\t" + cnt_page + "\r\n";
}
return contents;
}
这2段程序的修改主要涉及到了jQuery选择器的使用,其格式为 $(选择条件,选择对象) ,需要注意的是在缺少选择对象的输入时,jQuery选择器默认操作对象为当前页面的HTML。
目录具体内容解析时,使用到的js方法是 innerText 和 getAttribute ,innerText用于获取标签内文字,其与innerHTML的区别在于,innerText仅返回标签内的文本,innerHTML返回的则是整个html标签,形式为‘<...>文本</...>’。
getAttribute用于获取标签特定属性的内容,比如可以使用getAtrribute("class")获取标签的class属性。
另外一点需要注意的是,原版程序中使用了“trim()”方法去除目录多余的空格和制表符,如果保留会导致pdf目录信息在新的解析方法中无法分级,所以将这个方法从程序中删除。
完成的修复后的脚本源码如下:
// ==UserScript==
// @id CNKI_PDF_Supernova
// @name 知网PDF下载助手(修复版)
// @version 3.4.5
// @author Supernova
// @description 直接以PDF格式从知网下载期刊论文和博硕士论文; 下载博士论文目录; 批量下载文献
// @include http*://*.cnki.net/*
// @include http*://*.cnki.net.*/*
// @include */DefaultResult/Index*
// @include */defaultresult/index*
// @include */KNS8/AdvSearch*
// @include */detail.aspx*
// @include */CatalogViewPage.aspx*
// @include */Article/*
// @include */kns/brief/*
// @include */kns55/brief/*
// @include */grid2008/brief/*
// @include */detail/detail.aspx*
// @exclude http://image.cnki.net/*
// @run-at document-idle
// @icon https://cnki.net/favicon.ico
// @grant unsafeWindow
// @grant GM_setClipboard
// @grant GM_xmlhttpRequest
// @grant GM_openInTab
// @license MIT
// @namespace https://github.com/supernovaZhangJiaXing/Tampermonkey/
// ==/UserScript==
'use strict';
var $ = unsafeWindow.jQuery;
$(document).ready(function() {
var myurl = window.location.href;
var isDetailPage = myurl.indexOf("detail.aspx") != -1 ? true: false; // 点进文献后的详情页
var isContentPage = myurl.indexOf("kdoc/download.aspx?") != -1 ? true : false; // 分章下载
if (isDetailPage === false) {
// 对应普通检索和高级检索
if (window.location.href.indexOf("kns8") != -1 || window.location.href.indexOf("KNS8") != -1){
$(document).ajaxSuccess(function(event, xhr, settings) {
if (settings.url.indexOf('/Brief/GetGridTableHtml') + 1) {
var down_btns = $('.downloadlink');
for (var i = 0; i < down_btns.length; i++) {
down_btns.eq(i).after(down_btns.eq(i).clone().attr('href', toPDF).css('background-color', '#C7FFC7').mouseover(function(e){
this.title="PDF下载";
})).css('background-color', '#C7FFFF').mouseover(function(e){
this.title="CAJ下载";
});
}
// 在后面新增一个批量下载按钮, 功能为下载pdf格式论文
$('.bulkdownload.export').eq(0).after($('.bulkdownload.export').eq(0).clone().html($('.bulkdownload.export').eq(0).html().replace('下载', 'PDF'))
.removeClass('bulkdownload').click(function () { // 点击下载按钮后的行为
// 获取到勾选的文献, 下载其pdf版
var down_btns = $('.downloadlink');
for (var i = 0; i < $('input.cbItem').length; i++) {
if ($('input.cbItem').eq(i).attr('checked') == 'checked') { // 只针对勾选中的i
window.setTimeout(GM_openInTab(down_btns.eq(2 * i + 1).attr('href')), 1000);
}
}
$.filenameClear();
}).css('background-color', '#C7FFC7')).css('background-color', '#C7FFFF').html($('.bulkdownload.export').eq(0).html().replace('下载', 'CAJ'))
}
$('th').eq(8).css('width', '12%');
});
}
}
else {
// 只对"博硕论文"详情页做优化, 否则影响期刊页面的显示
// 来自: https://greasyfork.org/zh-CN/scripts/371938
if (location.search.match(/dbcode=C[DM][FM]D&/i)) {
// 整本下载替换为CAJ下载
$(".btn-dlcaj").first().html($(".btn-dlcaj").first().html().replace("整本", "CAJ"));
// pdf文件的url
var pdf_url = $(".btn-dlpdf").remove().find("a").attr("href").replace("&dflag=downpage", "&dflag=pdfdown");
// 添加PDF下载
var pdf_down = $('<li class="btn-dlpdf"><a href=' + pdf_url + ' id="pdfDown" target="_blank" name = "pdfDown"><i></i>PDF下载</a></li>');
$(".btn-dlcaj").first().after(pdf_down);
// 从分章下载获取目录的URL
var content_url = $(".btn-dlcaj:eq(1)").find("a").attr("href") || '?';
//alert(content_url);
content_url = 'https://chn.oversea.cnki.net/kcms/detail/downdetail.aspx' + content_url.match(/\?.*/)[0];
//alert(content_url);
GM_xmlhttpRequest({method: 'GET', url: content_url, onload: manage_contents});
// 右侧添加使用说明
$(".operate-btn").append($('<li class="btn-phone"><a target="_blank" '
+ 'href="https://mp.weixin.qq.com/s?__biz=MzU5MTY4NDUzMg==&mid=2247484384'
+ '&idx=1&sn=6a135e824793d26b5bd8884b78c1f751&chksm=fe2a753bc95dfc2d3a5f6'
+ '383553fc369894c5021619c85bb7554583bdcb8c10624bf2a7097e1&token=462651491&lang=zh_CN#rd">脚本说明</a></li>'));
// 右侧底部添加工具下载(PdgContentEditor)
$(".opts-down").append($('<div class="fl info" style="font-size: 13px; border-left: 1px solid #ddd;"><p class="total-inform" style="margin-left: 3px">'
+ '<span><a href="https://pan.baidu.com/s/1VoJlEqPnPN8H6oklAZ0bGQ" target="_blank">点击下载目录合并软件及说明</a><br />提取码: y77f</span>'))
}
}
});
// 来自: https://greasyfork.org/zh-CN/scripts/371938
function toPDF() {
return $(this).data('PDF', this.href.replace(/&dflag=\w*|$/, '&dflag=pdfdown')).data("PDF");
}
function get_content(cnt_list){
var contents = "";
for (var i = 0; i < cnt_list.length; i++) { // 长度减一, 因为最后一个是text
//alert(cnt_list[i].innerHTML);
//console.log(cnt_list[i]);
var cnt_level = cnt_list[i].getAttribute("class").split("-")[1];
//console.log(cnt_level);
var cnt_levelText="";
for (var j = 0; j< cnt_level; j++){
cnt_levelText = cnt_levelText+"\t";
}
//console.log(cnt_levelText);
//break;
var cnt_item = cnt_list[i].childNodes[1].childNodes[1];
//alert(cnt_item);
// console.log(cnt_item);
cnt_item = cnt_levelText + cnt_item.innerText;
//console.log(cnt_item);
var cnt_page = cnt_list[i].childNodes[1].childNodes[2].textContent.trim().split("-")[0]; // 知网的目录给的是个范围, 正常只需要前半部分
contents = contents + cnt_item + "\t" + cnt_page + "\r\n";
}
return contents;
}
// 来自: https://greasyfork.org/zh-CN/scripts/371938
function manage_contents(xhr) {
var cnt_list = $('ul.list-main', xhr.responseText)[0]; // 目录列表
//console.log(cnt_list.innerHTML);
cnt_list = $('li', cnt_list);
// console.log(cnt_list[0]);
//alert(cnt_list);
var contents = get_content(cnt_list); // 目录内容
// 添加目录复制
$('.btn-dlpdf').first().after($('<li class="btn-dlpdf"><a href="javascript:void(0);">目录复制</a></li>').click(function() {
GM_setClipboard(contents); // 运用油猴脚本自带的复制函数
window.alert('目录已复制到剪贴板');
}));
// 添加目录下载
$('.btn-dlpdf').first().after($('<li class="btn-dlcaj"><a>目录下载</a></li>').click(function() {
var data = new Blob([contents],{type:"text/plain; charset=UTF-8"});
$(this).find('a').attr("download", '目录_' + $('.wx-tit h1:first-child()').text().trim() + '.txt');
$(this).find('a').attr("href", window.URL.createObjectURL(data));
window.URL.revokeObjectURL(data);
window.alert("目录索引已保存, 请使用PdgCntEditor软件将目录整合到PDF中");
}));
}
原版的油猴脚本链接为:https://greasyfork.org/zh-CN/scripts/390733-知网pdf下载助手
本文来自博客园,作者:逸笔
转载请注明原文链接:https://www.cnblogs.com/1blog/p/15360043.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号