

个人项目
个人项目
| 这个作业属于哪个课程 | 计科22级12班 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 完成个人项目,实现论文查重的功能,了解软件开发流程 |
github:https://github.com/MIR-mIsTEo/3122004822-01
一、完成PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 10 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 15 |
| Development | 开发 | 500 | 420 |
| · Analysis | · 需求分析 (包括学习新技术) | 400 | 300 |
| · Design Spec | · 生成设计文档 | 30 | 45 |
| · Design Review | · 设计复审 | 40 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 15 | 15 |
| · Design | · 具体设计 | 25 | 20 |
| · Coding | · 具体编码 | 120 | 150 |
| · Code Review | · 代码复审 | 50 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 50 |
| Reporting | 报告 | 30 | 30 |
| · Test Repor | · 测试报告 | 20 | 20 |
| · Size Measurement | · 计算工作量 | 20 | 20 |
| Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 40 | 40 |
| · 合计 | 1350 | 1195 |
二、项目结构与设计
其中,测试文件放在resources资源文件夹中
该项目由多个部分组成:
main函数:程序主入口,通过args从命令行获取原文,相似文章以及答案所写路径
tokenize函数:进行中文分词
jaccardSimilarity函数:利用jaccard算法计算两篇文章的相似度
tokenizeFile函数:用于读取文件中的文字
checkPlagiarism函数:比较两篇文章,设置阈值,并将结果输出到文件中
writeResultsToFile函数:输出结果到文件中的函数
项目结构
src
├── main
│ └── java
│ │ └── Main // 主函数
│ └── resources // 测试输入输出文件
│ │ └── answers
│ │ └── orig.txt
│ │ └── ...
├── test
代码实现
import com.hankcs.hanlp.HanLP;
import com.hankcs.hanlp.seg.common.Term;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
public class PlagiarismChecker {
// 中文分词
private Set<String> tokenize(String text) {
List<Term> terms = HanLP.segment(text);
Set<String> words = new HashSet<>();
for (Term term : terms) {
words.add(term.word); // 提取Term中的word字段
}
return words; // 返回唯一的单词集合
}
// 计算Jaccard相似度
private double jaccardSimilarity(Set<String> set1, Set<String> set2) {
Set<String> intersection = new HashSet<>(set1);
intersection.retainAll(set2);
Set<String> union = new HashSet<>(set1);
union.addAll(set2);
return (double) intersection.size() / union.size();
}
// 从文件中读取分词结果
private Set<String> tokenizeFile(String filePath) {
Set<String> tokens = new HashSet<>();
try (BufferedReader br = new BufferedReader(new FileReader(filePath))) {
String line;
while ((line = br.readLine()) != null) {
tokens.addAll(tokenize(line)); // 对每一行进行分词
}
} catch (IOException e) {
System.err.println("读取文件时发生错误: " + e.getMessage());
}
return tokens;
}
public void checkPlagiarism(String originalText, String plagiarizedText, String outputFilePath) {
Set<String> tokens1 = tokenize(originalText);
Set<String> tokens2 = tokenize(plagiarizedText);
double similarity = jaccardSimilarity(tokens1, tokens2);
double percentage = similarity * 100;
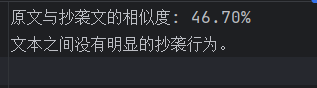
String result = String.format("原文与抄袭文的相似度: %.2f%%\n", percentage);
System.out.println(result);
if (similarity > 0.5) { // 设置阈值为50%
result += "警告:可能存在抄袭行为!\n";
} else {
result += "文本之间没有明显的抄袭行为。\n";
}
writeResultsToFile(outputFilePath, result);
}
// 将结果写入文件
private void writeResultsToFile(String filePath, String results) {
try (BufferedWriter writer = new BufferedWriter(new FileWriter(filePath))) {
writer.write(results);
System.out.println("结果已写入 " + filePath);
} catch (IOException e) {
System.err.println("写入文件时发生错误: " + e.getMessage());
}
}
public static void main(String[] args) {
if (args.length < 3) {
System.out.println("请提供原文路径、抄袭文路径和输出文件路径: ");
return;
}
String originalFilePath = args[0];
String plagiarizedFilePath = args[1];
String outputFilePath = args[2];
// 读取原文和抄袭文
StringBuilder originalText = new StringBuilder();
StringBuilder plagiarizedText = new StringBuilder();
try {
// 读取原文
BufferedReader originalReader = new BufferedReader(new FileReader(originalFilePath));
String line;
while ((line = originalReader.readLine()) != null) {
originalText.append(line).append("\n");
}
originalReader.close();
// 读取抄袭文
BufferedReader plagiarizedReader = new BufferedReader(new FileReader(plagiarizedFilePath));
while ((line = plagiarizedReader.readLine()) != null) {
plagiarizedText.append(line).append("\n");
}
plagiarizedReader.close();
} catch (IOException e) {
System.err.println("读取文件时发生错误: " + e.getMessage());
return;
}
PlagiarismChecker checker = new PlagiarismChecker();
checker.checkPlagiarism(originalText.toString(), plagiarizedText.toString(), outputFilePath);
}
结果:
三、性能分析
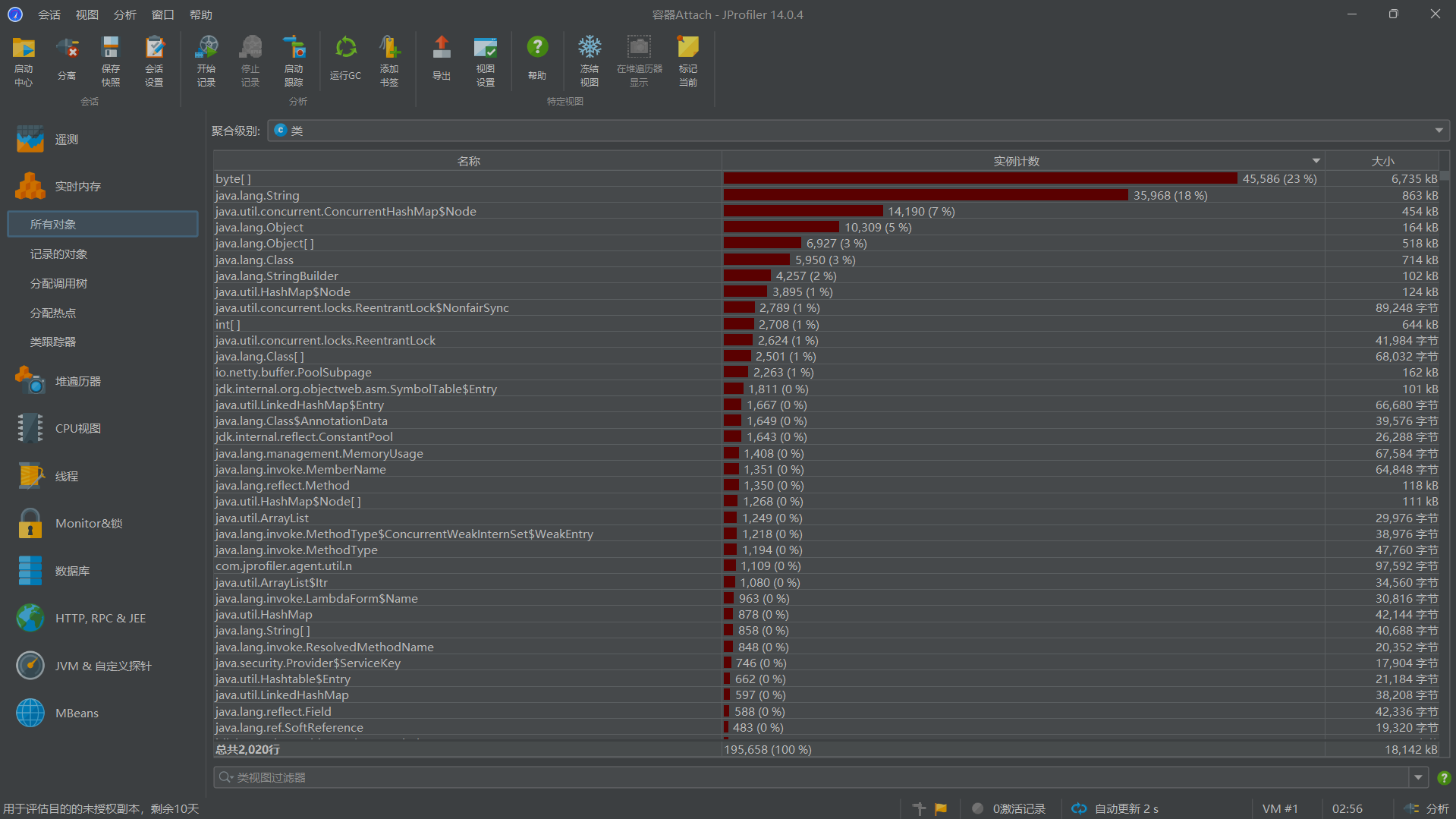

从数据来看,内存占用较大的函数为:
private Set
List
Set
for (Term term : terms) {
words.add(term.word); // 提取Term中的word字段
}
return words; // 返回唯一的单词集合
}
这说明在读取数据的方法需要有所改进:
1.更换其他中文分词器,提高读取效率
2.使用高级的输入流提高读取数据的效率
四、异常处理
对读取文件时读到空文件进行异常处理
try (BufferedReader br = new BufferedReader(new FileReader(filePath))) {
String line;
while ((line = br.readLine()) != null) {
tokens.addAll(tokenize(line)); // 对每一行进行分词
}
} catch (IOException e) {
System.err.println("读取文件时发生错误: " + e.getMessage());
}
输入文件数不等于三的处理
if (args.length < 3) {
System.out.println("请提供原文路径、抄袭文路径和输出文件路径: ");
return;
}
对写入文件时发生错误的异常处理
private void writeResultsToFile(String filePath, String results) {
try (BufferedWriter writer = new BufferedWriter(new FileWriter(filePath))) {
writer.write(results);
System.out.println("结果已写入 " + filePath);
} catch (IOException e) {
System.err.println("写入文件时发生错误: " + e.getMessage());
}
}

