爬虫大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075
本次作业爬取的是关于豆瓣电影的分类、影片等情况
导入本次作业所需要在包
import logging import random import string import requests import time import pandas as pd from bs4 import BeautifulSoup from urllib import parse from setting import User_Agents
爬取在目标是把分类在电影一次性爬取然后进行分析
准备代码提取网页在属性:
detail['电影名'] = soup.find_all('span',property='v:itemreviewed')[0].text detail['影片详情链接'] = item detail['豆瓣评分'] = soup.select('.rating_num')[0].text detail['评价人数'] = soup.find_all('span',property='v:votes')[0].text detail['导演'] = soup.select('.attrs')[0].text detail['上映时间'] = soup.find_all('span',property='v:initialReleaseDate')[0].get('content') detail['五星比例'] = soup.select('.rating_per')[0].text detail['四星比例'] = soup.select('.rating_per')[1].text detail['三星比例'] = soup.select('.rating_per')[2].text detail['两星比例'] = soup.select('.rating_per')[3].text detail['一星比例'] = soup.select('.rating_per')[4].text
df.to_csv(r'D:\douban11.csv',encoding='utf-8-sig')
保存成csv文件
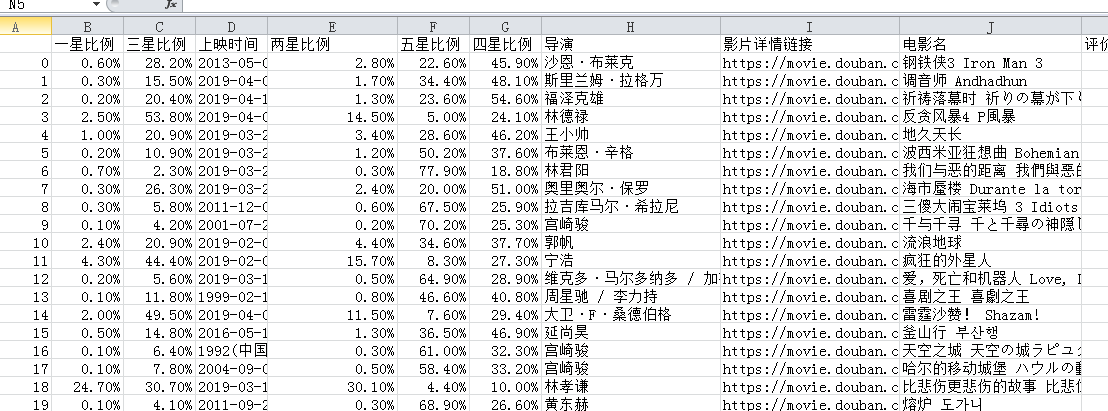
爬取结果:
分析结果:
对爬取在电影评分平均值进行统计,情况大概如下:
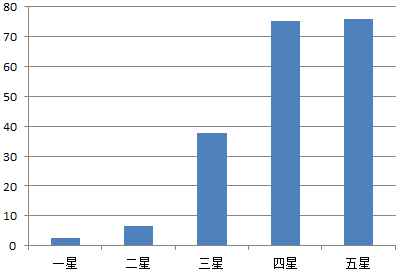
所有爬取在此类电影口碑还是很不错在,四五星比较居高的。

爬取在此类电影电影中,拍摄影片次数在导演,生成词云如下图。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号