


垂直搜索引擎完整实现
本篇博客是在上一篇《Lucene搜索引擎+HDFS+MR完成垂直搜索》的基础上,在数据收集之后的JSP/Servlet方面,换为SpringMVC框架来实现。
借助SpringMVC技术完成数据库、HDFS、页面的交互,以达到实现垂直搜索引擎。
本篇博客的思想:一是深入数据收集、分析、关键词搜索呈现的流程实现;
一是借此实践学习SpringMVC框架的技术。
首先简单阐述实现垂直搜索引擎的流程:1‘网络爬虫的数据存取到HDFS和数据库中;
2’MR对数据进行分析规约;
3‘SpringMVC实现关键词搜索并呈现到网页(此处为本篇重点阐述)
----->
目录:
1、SpringMVC阐述
2、创建web项目(添加Spring框架支持)
3、配置applicationContext.xml★★
4、配置web.xml文件★★
5、添加log4j.properties文件至src根目录
6、实现DAO操作类
7、修改页面源码
8、编写控制器来自动接收参数,以及进行数据操作★★
9、过滤器解决乱码问题
10、结果显示
11、总结
------>
1、 SpringMVC阐述
SpringMVC是Spring的一个子框架,主要是用来处理MVC设计模式中的View和Control。
MVC:
Model:模型层,也就是数据库操作层。DAO部分代码
View:展示层,也就是页面显示部分。Servlet部分
Controller:控制层,也就是业务逻辑层。JSP部分
使用SpringMVC以后,这三部分代码都会有改变,由Spring来进行调整。
企业用的最多的是SpringMVC + MyBatis。
这里我们就只使用SpringMVC + JDBC来完成。
Spring 在这三层可以有不同的作用:
Model层中Spring可以帮助进行数据源连接池的配置,还可以简化JDBC的操作代码,同时还能帮助完成自动的打开和关闭数据库连接。
View层中,Spring可以帮助我们简化表单提交的参数代码,也可以自动接收Control中返回的数据信息。
Control层中,Spring可以帮助我们自动接收页面提交的参数。
Spring的核心在于配置文件,所有的类的信息基本都要加入到配置文件中或使用Annotation来进行标注。
2、创建web项目(添加Spring框架支持)
 【项目整体呈现】
【项目整体呈现】
创建一个新的web项目,导入上一篇项目所需的jar包,以及拷贝vo类(DAO接口类)和utils类(关键词查询类)所在的包。
先为项目加入Spring的框架支持。
在项目上点右键,选择MyEclipse,然后找到install Spring … 的选项。
按照固定的步骤加入支持,最后一步时,一定要注意选择好需要的支持库,这里必须用到的是Persistence和Web
3、配置applicationContext.xml
这个文件Spring的配置文件,主要是将各种POJO,JAVA,action配置到XML转交给beanfactory管理,降低耦合度。
主要的配置组件:
<bean id="射影class的名字" class="写的JAVA类"/>
然后就是这些<bean>之间的依赖关系,比如:
<bean id="mySerive" class="org.haha.MyServiceImpl"/>
<bean id="loginAction" class="org.haha.LoginAction" scope="prototype">
<!--依赖注入业务逻辑组件-->
<property name="ms" ref="myService" />
</bean>
以上代码的意思会在loginAction的代码里引用MyServiceImpl类,但是只需要用ms代替就可以
例如:
public String execute() throws Exception{
ms.sayhello();
}
正常情况应该 new MyServiceImpl,但是通过XML配置之后就直接用以上代码就可以实现
new 的效果。
以下是该项目的配置文件呈现:
1 <?xml version="1.0" encoding="UTF-8"?> 2 <beans 3 xmlns="http://www.springframework.org/schema/beans" 4 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 5 xmlns:p="http://www.springframework.org/schema/p" 6 7 xmlns:context="http://www.springframework.org/schema/context" 8 xmlns:mvc="http://www.springframework.org/schema/mvc" 9 10 xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.1.xsd 11 http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.1.xsd 12 http://www.springframework.org/schema/mvc http://www.springframework.org/schema/mvc/spring-mvc-3.1.xsd"> 13 14 <!-- 加入SpringMVC的库支持 --> 15 <mvc:annotation-driven></mvc:annotation-driven> 16 <!-- 加入Context支持 --> 17 <context:annotation-config></context:annotation-config> 18 <!-- 配置使用Annotation的包范围 --> 19 <context:component-scan base-package="org.liky.sina.dao.impl,org.liky.sina.action"></context:component-scan> 20 21 <!-- 配置数据库连接池 --> 22 <bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource"> 23 <property name="driverClassName" value="org.gjt.mm.mysql.Driver"></property> 24 <property name="url" value="jdbc:mysql://localhost:3306/sina_news"></property> 25 <property name="username" value="root"></property> 26 <property name="password" value="admin"></property> 27 </bean> 28 29 <!-- 配置一个模板类 --> 30 <bean id="jdbcTemplate" class="org.springframework.jdbc.core.JdbcTemplate"> 31 <property name="dataSource"> 32 <ref bean="dataSource"/> 33 </property> 34 </bean> 35 36 <!-- 配置自动管理连接的一个事务操作支持 --> 37 <bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"> 38 <property name="dataSource"> 39 <ref bean="dataSource"/> 40 </property> 41 </bean> 42 43 44 <bean id="transactionInterceptor" class="org.springframework.transaction.interceptor.TransactionInterceptor"> 45 <property name="transactionManager"> 46 <ref bean="transactionManager"/> 47 </property> 48 49 <!-- 配置事务处理方式 *表示service中的所有方法都要进行事务处理。PROPAGATION_REQUIRED表示事务处理方式,有以下三种选择: 50 PROPAGATION_REQUIRED:正常事务处理 51 PROPAGATION_REQUIRED_NEWS:每个操作单独进行一个事务处理 52 PROPAGATION_REQUIRED_NEVER:不使用事务,出错后后面的不进行添加 53 --> 54 55 <property name="transactionAttributes"> 56 <props> 57 <prop key="*">PROPAGATION_REQUIRED</prop> 58 </props> 59 </property> 60 61 </bean> 62 63 <!-- 配置事务管理器的作用范围 --> 64 <bean class="org.springframework.aop.framework.autoproxy.BeanNameAutoProxyCreator"> 65 <property name="interceptorNames"> 66 <list> 67 <value>transactionInterceptor</value> 68 </list> 69 </property> 70 <property name="beanNames"> 71 <list> 72 <value>*DAOImpl</value> 73 </list> 74 </property> 75 </bean> 76 77 78 79 </beans>
4、配置web.xml文件
这个文件是需要在里面让服务器启动时,可以自动加载spring的配置文件。
代码呈现:
1 <?xml version="1.0" encoding="UTF-8"?> 2 <web-app xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 3 xmlns="http://java.sun.com/xml/ns/javaee" xmlns:web="http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd" 4 xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd" 5 id="WebApp_ID" version="3.0"> 6 <display-name>SinaNewsSpringMVC</display-name> 7 <welcome-file-list> 8 <welcome-file>index.html</welcome-file> 9 </welcome-file-list> 10 <listener> 11 <listener-class>org.springframework.web.context.ContextLoaderListener</listener-class> 12 </listener> 13 <context-param> 14 <param-name>contextConfigLocation</param-name> 15 <param-value>classpath:applicationContext.xml</param-value> 16 </context-param> 17 18 <!-- 手工配置加载SpringMVC的支持库和跳转路径 --> 19 <servlet> 20 <servlet-name>springmvc</servlet-name> 21 <servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class> 22 23 <init-param> 24 <param-name>contextConfigLocation</param-name> 25 <param-value>/WEB-INF/classes/applicationContext.xml</param-value> 26 </init-param> 27 <load-on-startup>1</load-on-startup> 28 </servlet> 29 <servlet-mapping> 30 <servlet-name>springmvc</servlet-name> 31 <url-pattern>*.do</url-pattern> 32 </servlet-mapping> 33 34 <!-- 添加过滤器 --> 35 <filter> 36 <filter-name>encoding</filter-name> 37 <filter-class>org.liky.sina.filter.EncodingFilter</filter-class> 38 </filter> 39 <filter-mapping> 40 <filter-name>encoding</filter-name> 41 <url-pattern>/*</url-pattern> 42 </filter-mapping> 43 </web-app>
5、添加log4j.properties文件至src根目录
Log4j,Apache的一个开源项目,作用:
可以控制日志信息输送的目的地是控制台、文件、GUI组件、甚至是套接口服务器、NT的事件记录器、UNIXSyslog守护进程等;
可以控制每一条日志的输出格式;
通过定义每一条日志信息的级别,我们能够更加细致地控制日志的生成过程。
此外,这些可以通过一个配置文件来灵活地进行配置,而不需要修改应用的代码。
1 ### direct log messages to stdout ### 2 log4j.appender.stdout=org.apache.log4j.ConsoleAppender 3 log4j.appender.stdout.Target=System.out 4 log4j.appender.stdout.layout=org.apache.log4j.PatternLayout 5 log4j.appender.stdout.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n 6 7 ### direct messages to file hibernate.log ### 8 #log4j.appender.file=org.apache.log4j.FileAppender 9 #log4j.appender.file.File=hibernate.log 10 #log4j.appender.file.layout=org.apache.log4j.PatternLayout 11 #log4j.appender.file.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n 12 13 ### set log levels - for more verbose logging change 'info' to 'debug' ### 14 15 log4j.rootLogger=warn, stdout 16 17 log4j.logger.org.hibernate=info 18 #log4j.logger.org.hibernate=debug 19 20 ### log HQL query parser activity 21 #log4j.logger.org.hibernate.hql.ast.AST=debug 22 23 ### log just the SQL 24 #log4j.logger.org.hibernate.SQL=debug 25 26 ### log JDBC bind parameters ### 27 log4j.logger.org.hibernate.type=info 28 #log4j.logger.org.hibernate.type=debug 29 30 ### log schema export/update ### 31 log4j.logger.org.hibernate.tool.hbm2ddl=debug 32 33 ### log HQL parse trees 34 #log4j.logger.org.hibernate.hql=debug 35 36 ### log cache activity ### 37 #log4j.logger.org.hibernate.cache=debug 38 39 ### log transaction activity 40 #log4j.logger.org.hibernate.transaction=debug 41 42 ### log JDBC resource acquisition 43 #log4j.logger.org.hibernate.jdbc=debug 44 45 ### enable the following line if you want to track down connection ### 46 ### leakages when using DriverManagerConnectionProvider ### 47 #log4j.logger.org.hibernate.connection.DriverManagerConnectionProvider=trace
6、实现DAO操作类
之后启动服务器进行测试,如果启动后没有报错,那就表示环境配置成功,可以正常使用。
下面就开始编写DAO操作。
对于DAO接口是没有变化的,所以可以直接拷贝过来。
这里不需要再编写工厂类,因为Spring可以自动帮助创建对象。
实现类需要交给Spring来进行管理和控制,并且简化jdbc代码操作
代码如下:
1 package org.liky.sina.dao.impl; 2 3 import java.sql.ResultSet; 4 import java.sql.SQLException; 5 import java.util.List; 6 7 import org.liky.sina.dao.INewsDAO; 8 import org.liky.sina.vo.News; 9 import org.springframework.beans.factory.annotation.Autowired; 10 import org.springframework.jdbc.core.JdbcTemplate; 11 import org.springframework.jdbc.core.RowMapper; 12 import org.springframework.jdbc.core.support.JdbcDaoSupport; 13 import org.springframework.stereotype.Component; 14 15 @Component 16 public class NewsDAOImpl extends JdbcDaoSupport implements INewsDAO,RowMapper<News> { 17 18 @Autowired 19 public NewsDAOImpl(JdbcTemplate jdbcTemplate) { 20 super.setJdbcTemplate(jdbcTemplate); 21 } 22 23 24 public void doCreate(News news) throws Exception { 25 String sql="insert into news (id,title,description,url) values (?,?,?,?)"; 26 27 super.getJdbcTemplate().update(sql, news.getId(),news.getTitle(),news.getDescription(),news.getUrl()); 28 } 29 30 public News findById(int id) throws Exception { 31 String sql="select id,title,description,url from news where id=?"; 32 News news=super.getJdbcTemplate().queryForObject(sql,new Object[]{id},this); 33 34 return news; 35 } 36 37 public List<News> findByIds(Integer[] ids, int start, int pageSize) 38 throws Exception { 39 StringBuilder sql = new StringBuilder( 40 "SELECT id,title,description,url FROM new_news WHERE id IN ("); 41 if (ids != null && ids.length > 0) { 42 for (int id : ids) { 43 sql.append(id); 44 sql.append(","); 45 } 46 // 第一个 ? 表示开始的记录数,第二个 ? 表示每页显示的记录数。 47 String resultSQL = sql.substring(0, sql.length() - 1) 48 + ") LIMIT ?,?"; 49 List<News> allNews = super.getJdbcTemplate().query(resultSQL, 50 new Object[] { start, pageSize }, this); 51 return allNews; 52 } 53 return null; 54 } 55 56 57 public int getAllCount(Integer[] ids)throws Exception{ 58 StringBuilder sql=new StringBuilder("select count(id) from new_news where id in ("); 59 60 if(ids!=null&&ids.length>0){ 61 for(int id:ids){ 62 sql.append(id); 63 sql.append(","); 64 } 65 // 第一个 ? 表示开始的记录数,第二个 ? 表示每页显示的记录数。 66 String resultSQL = sql.substring(0, sql.length() - 1) + ")"; 67 int count = super.getJdbcTemplate().queryForInt(resultSQL); 68 return count; 69 } 70 return 0; 71 } 72 73 public News mapRow(ResultSet rs, int arg1) throws SQLException { 74 News news=new News(); 75 news.setId(rs.getInt(1)); 76 news.setTitle(rs.getString(2)); 77 news.setDescription(rs.getString(3)); 78 news.setUrl(rs.getString(4)); 79 return news; 80 81 } 82 83 }
7、修改页面源码
表单部分进行一些简单的调整,加入了form标签相关的配置。主要在action的值改为了search.do
【1】index.jsp修改
1 <%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%> 2 <% 3 String path = request.getContextPath(); 4 String basePath = request.getScheme()+"://"+request.getServerName()+":"+request.getServerPort()+path+"/"; 5 %> 6 7 <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> 8 <html> 9 <head> 10 <base href="<%=basePath%>"> 11 <title>新浪新闻热词搜索</title> 12 </head> 13 14 <body> 15 <center> 16 <form action="search.do" method="post"> 17 请输入查询关键字: 18 <input type="text" name="keyword"> 19 <input type="submit" value="查询"> 20 </form> 21 </center> 22 </body> 23 </html>
【2】result.jsp修改
1 <%@page import="org.liky.sina.vo.News"%> 2 <%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%> 3 <% 4 String path = request.getContextPath(); 5 String basePath = request.getScheme() + "://" 6 + request.getServerName() + ":" + request.getServerPort() 7 + path + "/"; 8 %> 9 10 <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> 11 <html> 12 <head> 13 <base href="<%=basePath%>"> 14 15 <title>新浪新闻搜索</title> 16 </head> 17 18 <body> 19 <center> 20 <% 21 List<News> allNews = (List<News>)request.getAttribute("allNews"); 22 %> 23 <table width="80%"> 24 <% 25 for (News n : allNews) { 26 27 %> 28 <tr> 29 <td> 30 <a href="<%=n.getUrl() %>" target="_blank"><%=n.getTitle() %></a> <br> 31 <%=n.getDescription() %> 32 <hr/> 33 </td> 34 </tr> 35 <% 36 } 37 38 %> 39 </table> 40 41 <% 42 int cp = (Integer)request.getAttribute("currentPage"); 43 int allPages = (Integer)request.getAttribute("allPages"); 44 %> 45 <form id="split_page_form" action="search.do" method="post"> 46 <input type="hidden" name="currentPage" id="cp" value="<%=cp %>" /> 47 <input type="button" <%=cp == 1?"disabled":"" %> value="首页" onclick="changeCp(1);"> 48 <input type="button" <%=cp == 1?"disabled":"" %> value="上一页" onclick="changeCp(<%=cp - 1 %>);"> 49 <input type="button" <%=cp == allPages?"disabled":"" %> value="下一页" onclick="changeCp(<%=cp + 1 %>);"> 50 <input type="button" <%=cp == allPages?"disabled":"" %> value="尾页" onclick="changeCp(<%=allPages %>);"> 51 第 <%=cp %> 页 / 共 <%=allPages %> 页 52 <br> 53 请输入查询关键字:<input type="text" name="keyword" value="<%=request.getParameter("keyword")%>"> 54 <input type="submit" value="查询"> 55 </form> 56 <script type="text/javascript"> 57 function changeCp(newcp) { 58 // 改变当前页数 59 document.getElementById("cp").value = newcp; 60 // 提交表单 61 document.getElementById("split_page_form").submit(); 62 } 63 </script> 64 65 </center> 66 </body> 67 </html>
8、编写控制器来自动接收参数,以及进行数据操作
之后需要编写SpringMVC的控制器来自动接收参数,并进行数据操作。
代码呈现:
1 package org.liky.sina.action; 2 3 import java.util.List; 4 5 import javax.annotation.Resource; 6 7 import org.liky.sina.dao.INewsDAO; 8 import org.liky.sina.utils.HDFSUtils; 9 import org.liky.sina.vo.News; 10 import org.springframework.stereotype.Controller; 11 import org.springframework.web.bind.annotation.RequestMapping; 12 import org.springframework.web.bind.annotation.RequestParam; 13 import org.springframework.web.servlet.ModelAndView; 14 15 16 @Controller 17 public class NewsAction { 18 private INewsDAO newsdao; 19 20 @RequestMapping(value="/search.do") 21 public ModelAndView search(@RequestParam String keyword,@RequestParam(defaultValue="1") int currentPage){ 22 ModelAndView mv= new ModelAndView(); 23 //一页显示10条数据 24 int pageSize=10; 25 26 try{ 27 Integer[] ids=HDFSUtils.getIdsByKeyword(keyword); 28 //根据这些id查询相应的结果 29 List<News> allNews=newsdao.findByIds(ids, (currentPage-1), pageSize); 30 31 int count=newsdao.getAllCount(ids); 32 //计算一个关键词读取的数据显示总页数 33 int allPages=count/pageSize; 34 if(count%pageSize!=0){ 35 allPages++; 36 } 37 38 //结果传递回页面显示 39 mv.addObject("allNews",allNews); 40 mv.addObject("allPages", allPages); 41 mv.addObject("currentPage", currentPage); 42 43 //切换到页面上 44 mv.setViewName("/result.jsp"); 45 }catch(Exception e){ 46 e.printStackTrace(); 47 } 48 49 return mv; 50 } 51 52 @Resource(name="newsDAOImpl") 53 public void setNewsdao(INewsDAO newsdao){ 54 this.newsdao=newsdao; 55 56 } 57 }
9、过滤器解决乱码问题
测试时会有乱码出现,因此还要编写一个过滤器来处理乱码。
如果是MyEclipse的乱码问题,只需修改:
【1】过滤器代码呈现:
1 package org.liky.sina.filter; 2 /** 3 * 过滤器,解决网页乱码的问题 4 */ 5 import java.io.IOException; 6 7 import javax.servlet.Filter; 8 import javax.servlet.FilterChain; 9 import javax.servlet.FilterConfig; 10 import javax.servlet.ServletException; 11 import javax.servlet.ServletRequest; 12 import javax.servlet.ServletResponse; 13 14 public class EncodingFilter implements Filter { 15 16 @Override 17 public void destroy() { 18 } 19 20 @Override 21 public void doFilter(ServletRequest arg0, ServletResponse arg1, 22 FilterChain arg2) throws IOException, ServletException { 23 //修改编码格式为UTF-8 24 arg0.setCharacterEncoding("UTF-8"); 25 arg2.doFilter(arg0, arg1); 26 } 27 28 @Override 29 public void init(FilterConfig arg0) throws ServletException { 30 // TODO Auto-generated method stub 31 32 } 33 34 }
【2】在web.xml中配置这个过滤器:
1 <filter> 2 <filter-name>encoding</filter-name> 3 <filter-class>org.liky.sina.filter.EncodingFilter</filter-class> 4 </filter> 5 <filter-mapping> 6 <filter-name>encoding</filter-name> 7 <url-pattern>/*</url-pattern> 8 </filter-mapping>
10、结果显示
关于其他的代码在参考《Lucene搜索引擎+HDFS+MR完成垂直搜索》。
运行结果如下:
控制台显示:
浏览器index.jsp显示:

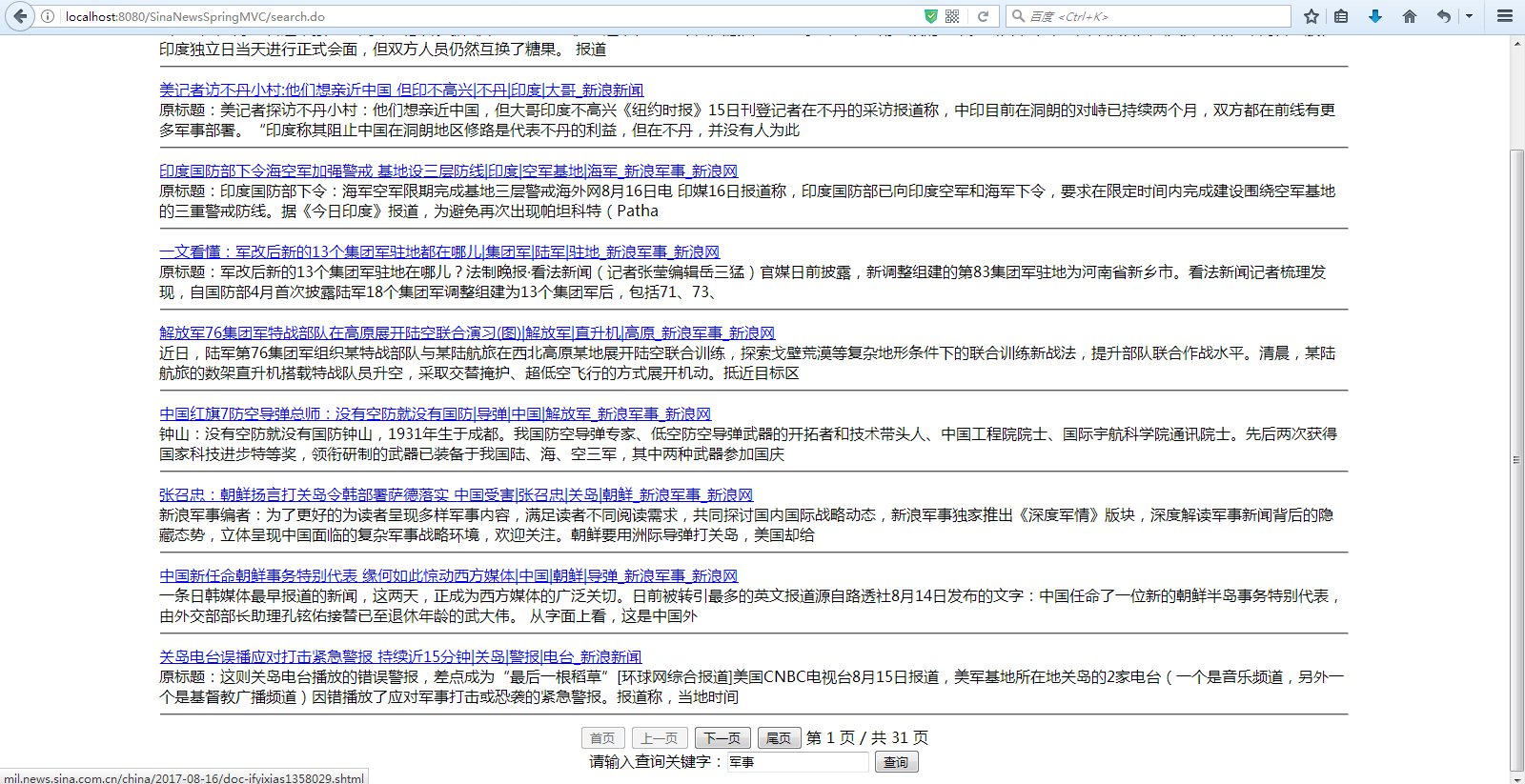
搜索结果 result.jsp 显示,尾部实现了分页功能,并且还可以进行搜索:
11、总结
首先上一篇结尾存在的乱码问题在此处第九部分,给出了过滤器的方法,将编码格式改为UTF-8,已经解决了。
关于垂直搜索引擎,是针对某一个行业的专业搜索引擎(本次项目是对新浪新闻的数据收集,爬取深度为5),是搜索引擎的细分和延伸,是对网页库中的某类专门的信息进行一次整合,定向分字段抽取出需要的数据进行处理后再以某种形式返回给用户。
本篇用SpringMVC框架的技术完成数据的垂直搜索,相比来说,结构更加清晰,难点在于两个配置文件的修改,以及在代码中使用配置文件。
思路流程:
1、 DAO操作类根据首页搜索框关键词的输入,获取HDFS的id,以便从数据库提取一组信息;
2、 配置文件实现了数据库的连接,并简化了DAO的流程实现;
3、 SpringMVC的控制器自动接收参数,并进行数据操作;
4、 JSP文件接收控制器传递的数据,呈现在结果页面。
