

大数据【五】Hive(部署;表操作;分区)
一 概述
就像我们所了解的sql一样,Hive也是一种数据仓库,不同的是hive是在hadoop大数据生态圈中所用。这篇博客我主要介绍Hive的简单表运用。
Hive是Hadoop 大数据生态圈中的数据仓库,其提供以表格的方式来组织与管理HDFS上的数据、以类SQL的方式来操作表格里的数据。
Hive的设计目的是能够以类SQL的方式查询存放在HDFS上的大规模数据集,不必开发专门的MapReduce应用。
Hive本质上相当于一个MapReduce和HDFS的翻译终端,用户提交Hive脚本后,Hive运行时环境会将这些脚本翻译成MapReduce和HDFS操作并向集群提交这些操作。
当用户向Hive提交其编写的HiveQL后,首先,Hive运行时环境会将这些脚本翻译成MapReduce和HDFS操作,紧接着,Hive运行时环境使用Hadoop命令行接口向Hadoop集群提交这些MapReduce和HDFS操作,最后,Hadoop集群逐步执行这些MapReduce和HDFS操作,整个过程可概括如下:
(1)用户编写HiveQL并向Hive运行时环境提交该HiveQL。
(2)Hive运行时环境将该HiveQL翻译成MapReduce和HDFS操作。
(3)Hive运行时环境调用Hadoop命令行接口或程序接口,向Hadoop集群提交翻译后的HiveQL。
(4)Hadoop集群执行HiveQL翻译后的MapReduce-APP或HDFS-APP。
由上述执行过程可知,Hive的核心是其运行时环境,该环境能够将类SQL语句编译成MapReduce。
Hive构建在基于静态批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive 并不能够在大规模数据集上实现低延迟快速的查询。例如,Hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。
因此,Hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的HiveQL语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
二 Hive部署
按metastore存储位置的不同,其部署模式分为内嵌模式、本地模式和完全远程模式三种。当使用完全模式时,可以提供很多用户同时访问并操作Hive,并且此模式还提供各类接口(BeeLine,CLI,甚至是Pig),这里我们以内嵌模式为例。
由于使用内嵌模式时,其Hive会使用内置的Derby数据库来存储数据库,此时无须考虑数据库部署连接问题。
1‘ 安装部署
在client机上操作:首先确定存在Hive(如果不存在,同前述博客的mapreduce一样的导入方法)
ls /usr/cstor/

2’ 配置HDFS
先为Hive配置Hadoop安装路径。
待解压完成后,进入Hive的配置文件夹conf目录下,接着将Hive的环境变量模板文件复制成环境变量文件。
cd /usr/cstor/hive/conf
cp hive-env.sh.template hive-env.sh
vim hive-env.sh
在配置文件中加入以下语句:
HADOOP_HOME=/usr/cstor/hadoop
然后在HDFS里新建Hive的存储目录。
在HDFS中新建/tmp 和 /usr/hive/warehouse 两个文件目录,并对同组用户增加写权限。
bin/hadoop fs -mkdir /tmp
bin/hadoop fs -mkdir -p /usr/hive/warehouse
bin/hadoop fs -chmod g+w /tmp
bin/hadoop fs -chmod g+w /usr/hive/warehouse
3‘ 启动Hive
在内嵌模式下,启动Hive指的是启动Hive运行时环境,用户可使用下述命令进入Hive运行时环境。
启动Hive命令行:
cd /usr/cstor/hive/
bin/hive
或者进入 /usr/cstor/hive/bin/ 然后用命令 ./hive 启动Hive
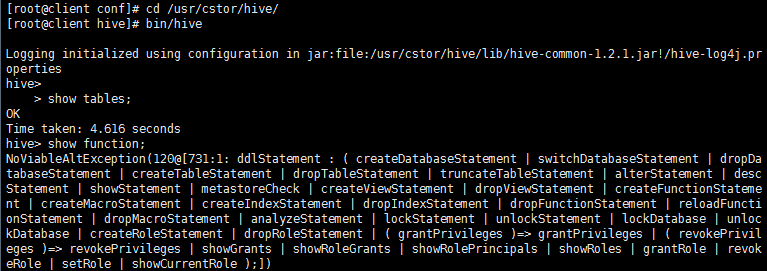
结果显示会进入hive环境,然后使用 “show tables”, “show function”后验证配置成功。
三 Hive表处理
Hive没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由的组织 Hive中的表,只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符,Hive就可以解析数据。
Hive中所有的数据都存储在HDFS中,Hive中包含以下数据模型:表(Table),外部表(External Table),分区(Partition),桶(Bucket)。
Hive中Table和数据库中 Table在概念上是类似的,每一个Table在Hive中都有一个相应的目录存储数据。例如,一个表 pvs,它在 HDFS 中的路径为:/wh/pvs,其中,wh是在hive-site.xml中由${hive.metastore.warehouse.dir}指定的数据仓库的目录,所有的 Table 数据(不包括 External Table)都保存在这个目录中。
1’ 启动Hive(上一步)
2‘ 创建表
默认情况下,新建表的存储格式均为Text类型,字段间默认分隔符为键盘上的Tab键。
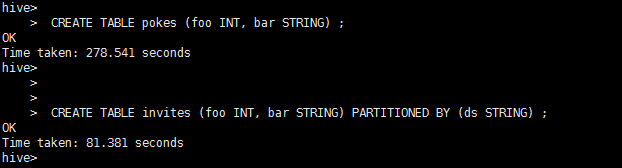
创建一个有两个字段的pokes表,其中第一列名为foo,数据类型为INT,第二列名为bar,类型为STRING。
hive> CREATE TABLE pokes (foo INT, bar STRING) ;
创建一个有两个实体列和一个(虚拟)分区字段的invites表。
hive> CREATE TABLE invites (foo INT, bar STRING) PARTITIONED BY (ds STRING) ;
注意:分区字段并不属于invites,当向invites导入数据时,ds字段会用来过滤导入的数据。
3’ 显示表
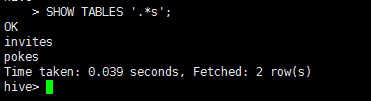
show tables;
或者正则查询 show tables '.*s';
>显示表列
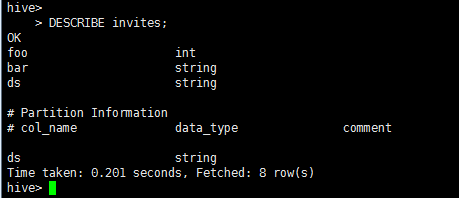
DESCRIBE invites;
4‘ 更改表
修改表events名为3koobecaf (自行创建任意类型events表):
ALTER TABLE events RENAME TO 3koobecaf;
将pokes表新增一列(列名为new_col,类型为INT):
ALTER TABLE pokes ADD COLUMNS (new_col INT);
将invites表新增一列(列名为new_col2,类型为INT),同时增加注释“a comment”:
ALTER TABLE invites ADD COLUMNS (new_col2 INT COMMENT 'a comment');
替换invites表所有列名(数据不动):
ALTER TABLE invites REPLACE COLUMNS (foo INT, bar STRING, baz INT COMMENT 'baz replaces new_col2');
5’ 删除表
删除invites表bar 和 baz 两列:
ALTER TABLE invites REPLACE COLUMNS (foo INT COMMENT 'only keep the first column');
删除pokes表:
DROP TABLE pokes;
四 Hive分区
分区(Partition) 对应于数据库中的 分区(Partition) 列的密集索引,但是 Hive 中 分区(Partition) 的组织方式和数据库中的很不相同。在 Hive 中,表中的一个分区(Partition)对应于表下的一个目录,所有的分区(Partition) 的数据都存储在对应的目录中。 例如:pvs 表中包含 ds 和 ctry 两个分区(Partition),则对应于 ds = 20090801, ctry = US 的HDFS 子目录为:/wh/pvs/ds=20090801/ctry=US;对应于 ds = 20090801, ctry = CA 的 HDFS 子目录为;/wh/pvs/ds=20090801/ctry=CA。
外部表(External Table) 指向已经在 HDFS 中存在的数据,可以创建分区(Partition)。它和 Table 在元数据的组织上是相同的,而实际数据的存储则有较大的差异。
Table 的创建过程和数据加载过程(这两个过程可以在同一个语句中完成),在加载数据的过程中,实际数据会被移动到数据仓库目录中;之后对数据的访问将会直接在数据仓库目录中完成。删除表时,表中的数据和元数据将会被同时删除。
1‘ 启动Hadoop集群(因为Hive依赖于MapReduce)
在主节点进入Hadoop安装目录,启动Hadoop集群。
# cd /usr/cstor/hadoop/sbin
[root@master sbin]# ./start-all.sh
2’ 用命令进入Hive客户端(启动Hive)
进入Hive安装目录,用命令进入Hive客户端。
cd /usr/cstor/hive
bin/hive
3‘ 通过HQL语句进行实验
>进入客户端后,查看Hive数据库,并选择default数据库:
hive> show databases;
>在命令端创建Hive分区表:
hive> create table parthive (createdate string, value string) partitioned by (year string) row format delimited fields terminated by '\t';
>查看新建的表:
hive> show tables;
>给parthive表创建两个分区:
hive> alter table parthive add partition(year='2017');
>查看parthive的表结构:
hive> describe parthive;
>向year=2017分区导入本地数据:
hive> load data local inpath '/root/data/12/parthive.txt' into table parthive partition(year='2017');
根据条件查询year=2017的数据:
hive> select * from parthive t where t.year='2017';
根据条件统计year=2017的数据:
hive> select count(*) from parthive where year='2017';

