
大数据【四】MapReduce(单词计数;二次排序;计数器;join;分布式缓存)
前言:
根据前面的几篇博客学习,现在可以进行MapReduce学习了。本篇博客首先阐述了MapReduce的概念及使用原理,其次直接从五个实验中实践学习(单词计数,二次排序,计数器,join,分布式缓存)。
一 概述
定义
MapReduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)。这样做的好处是可以在任务被分解后,可以通过大量机器进行并行计算,减少整个操作的时间。
适用范围:数据量大,但是数据种类小可以放入内存。
基本原理及要点:将数据交给不同的机器去处理,数据划分,结果归约。
理解MapReduce和Yarn:在新版Hadoop中,Yarn作为一个资源管理调度框架,是Hadoop下MapReduce程序运行的生存环境。其实MapRuduce除了可以运行Yarn框架下,也可以运行在诸如Mesos,Corona之类的调度框架上,使用不同的调度框架,需要针对Hadoop做不同的适配。(了解YARN见上一篇博客>> http://www.cnblogs.com/1996swg/p/7286490.html )
MapReduce编程
编写在Hadoop中依赖Yarn框架执行的MapReduce程序,并不需要自己开发MRAppMaster和YARNRunner,因为Hadoop已经默认提供通用的YARNRunner和MRAppMaster程序, 大部分情况下只需要编写相应的Map处理和Reduce处理过程的业务程序即可。
编写一个MapReduce程序并不复杂,关键点在于掌握分布式的编程思想和方法,主要将计算过程分为以下五个步骤:
(1)迭代。遍历输入数据,并将之解析成key/value对。
(2)将输入key/value对映射(map)成另外一些key/value对。
(3)依据key对中间数据进行分组(grouping)。
(4)以组为单位对数据进行归约(reduce)。
(5)迭代。将最终产生的key/value对保存到输出文件中。
Java API解析
(1)InputFormat:用于描述输入数据的格式,常用的为TextInputFormat提供如下两个功能:
数据切分: 按照某个策略将输入数据切分成若干个split,以便确定Map Task个数以及对应的split。
为Mapper提供数据:给定某个split,能将其解析成一个个key/value对。
(2)OutputFormat:用于描述输出数据的格式,它能够将用户提供的key/value对写入特定格式的文件中。
(3)Mapper/Reducer: Mapper/Reducer中封装了应用程序的数据处理逻辑。
(4)Writable:Hadoop自定义的序列化接口。实现该类的接口可以用作MapReduce过程中的value数据使用。
(5)WritableComparable:在Writable基础上继承了Comparable接口,实现该类的接口可以用作MapReduce过程中的key数据使用。(因为key包含了比较排序的操作)。
二 单词计数实验
!单词计数文件word
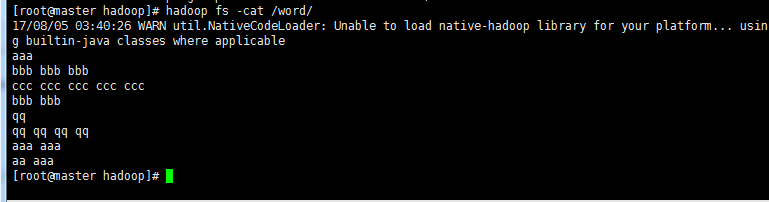
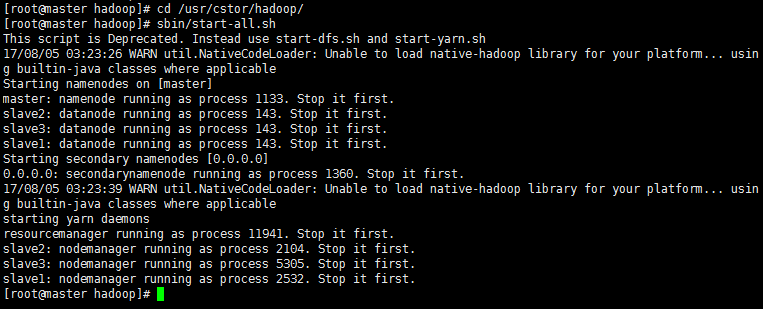
1‘ 启动Hadoop 执行命令启动(前面博客)部署好的Hadoop系统。
命令:
cd /usr/cstor/hadoop/
sbin/start-all.sh
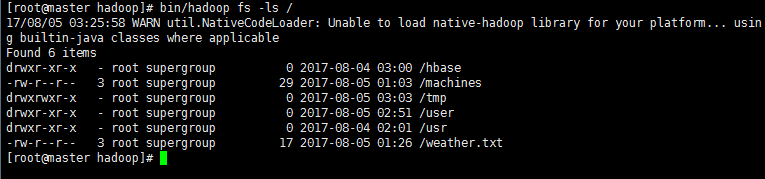
2’ 验证HDFS上没有wordcount的文件夹 此时HDFS上应该是没有wordcount文件夹。
cd /usr/cstor/hadoop/
bin/hadoop fs -ls / #查看HDFS上根目录文件 /
3‘ 上传数据文件到HDFS
cd /usr/cstor/hadoop/
bin/hadoop fs -put /root/data/5/word /

4’ 编写MapReduce程序
在eclipse新建mapreduce项目(方法见博客>> http://www.cnblogs.com/1996swg/p/7286136.html ),新建class类WordCount
主要编写Map和Reduce类,其中Map过程需要继承org.apache.hadoop.mapreduce包中Mapper类,并重写其map方法;Reduce过程需要继承org.apache.hadoop.mapreduce包中Reduce类,并重写其reduce方法。
1 import org.apache.hadoop.conf.Configuration; 2 import org.apache.hadoop.fs.Path; 3 import org.apache.hadoop.io.IntWritable; 4 import org.apache.hadoop.io.Text; 5 import org.apache.hadoop.mapreduce.Job; 6 import org.apache.hadoop.mapreduce.Mapper; 7 import org.apache.hadoop.mapreduce.Reducer; 8 import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; 9 import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; 10 import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner; 11 12 import java.io.IOException; 13 import java.util.StringTokenizer; 14 15 16 public class WordCount { 17 public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { 18 private final static IntWritable one = new IntWritable(1); 19 private Text word = new Text(); 20 //map方法,划分一行文本,读一个单词写出一个<单词,1> 21 public void map(Object key, Text value, Context context)throws IOException, InterruptedException { 22 StringTokenizer itr = new StringTokenizer(value.toString()); 23 while (itr.hasMoreTokens()) { 24 word.set(itr.nextToken()); 25 context.write(word, one);//写出<单词,1> 26 }}} 27 //定义reduce类,对相同的单词,把它们<K,VList>中的VList值全部相加 28 public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { 29 private IntWritable result = new IntWritable(); 30 public void reduce(Text key, Iterable<IntWritable> values,Context context) 31 throws IOException, InterruptedException { 32 int sum = 0; 33 for (IntWritable val : values) { 34 sum += val.get();//相当于<Hello,1><Hello,1>,将两个1相加 35 } 36 result.set(sum); 37 context.write(key, result);//写出这个单词,和这个单词出现次数<单词,单词出现次数> 38 }} 39 public static void main(String[] args) throws Exception {//主方法,函数入口 40 Configuration conf = new Configuration(); //实例化配置文件类 41 Job job = new Job(conf, "WordCount"); //实例化Job类 42 job.setInputFormatClass(TextInputFormat.class); //指定使用默认输入格式类 43 TextInputFormat.setInputPaths(job, args[0]); //设置待处理文件的位置 44 job.setJarByClass(WordCount.class); //设置主类名 45 job.setMapperClass(TokenizerMapper.class); //指定使用上述自定义Map类 46 job.setCombinerClass(IntSumReducer.class); //指定开启Combiner函数 47 job.setMapOutputKeyClass(Text.class); //指定Map类输出的<K,V>,K类型 48 job.setMapOutputValueClass(IntWritable.class); //指定Map类输出的<K,V>,V类型 49 job.setPartitionerClass(HashPartitioner.class); //指定使用默认的HashPartitioner类 50 job.setReducerClass(IntSumReducer.class); //指定使用上述自定义Reduce类 51 job.setNumReduceTasks(Integer.parseInt(args[2])); //指定Reduce个数 52 job.setOutputKeyClass(Text.class); //指定Reduce类输出的<K,V>,K类型 53 job.setOutputValueClass(Text.class); //指定Reduce类输出的<K,V>,V类型 54 job.setOutputFormatClass(TextOutputFormat.class); //指定使用默认输出格式类 55 TextOutputFormat.setOutputPath(job, new Path(args[1])); //设置输出结果文件位置 56 System.exit(job.waitForCompletion(true) ? 0 : 1); //提交任务并监控任务状态 57 } 58 }
5' 打包成jar文件上传
假定打包后的文件名为hdpAction.jar,主类WordCount位于包njupt下,则可使用如下命令向YARN集群提交本应用。
./yarn jar hdpAction.jar mapreduce1.WordCount /word /wordcount 1
其中“yarn”为命令,“jar”为命令参数,后面紧跟打包后的代码地址,“mapreduce1”为包名,“WordCount”为主类名,“/word”为输入文件在HDFS中的位置,/wordcount为输出文件在HDFS中的位置。
注意:如果打包时明确了主类,那么在输入命令时,就无需输入mapreduce1.WordCount来确定主类!

结果显示:
1 17/08/05 03:37:05 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 2 17/08/05 03:37:06 INFO client.RMProxy: Connecting to ResourceManager at master/10.1.21.27:8032 3 17/08/05 03:37:06 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 4 17/08/05 03:37:07 INFO input.FileInputFormat: Total input paths to process : 1 5 17/08/05 03:37:07 INFO mapreduce.JobSubmitter: number of splits:1 6 17/08/05 03:37:07 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1501872322130_0004 7 17/08/05 03:37:07 INFO impl.YarnClientImpl: Submitted application application_1501872322130_0004 8 17/08/05 03:37:07 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1501872322130_0004/ 9 17/08/05 03:37:07 INFO mapreduce.Job: Running job: job_1501872322130_0004 10 17/08/05 03:37:12 INFO mapreduce.Job: Job job_1501872322130_0004 running in uber mode : false 11 17/08/05 03:37:12 INFO mapreduce.Job: map 0% reduce 0% 12 17/08/05 03:37:16 INFO mapreduce.Job: map 100% reduce 0% 13 17/08/05 03:37:22 INFO mapreduce.Job: map 100% reduce 100% 14 17/08/05 03:37:22 INFO mapreduce.Job: Job job_1501872322130_0004 completed successfully 15 17/08/05 03:37:22 INFO mapreduce.Job: Counters: 49 16 File System Counters 17 FILE: Number of bytes read=54 18 FILE: Number of bytes written=232239 19 FILE: Number of read operations=0 20 FILE: Number of large read operations=0 21 FILE: Number of write operations=0 22 HDFS: Number of bytes read=166 23 HDFS: Number of bytes written=28 24 HDFS: Number of read operations=6 25 HDFS: Number of large read operations=0 26 HDFS: Number of write operations=2 27 Job Counters 28 Launched map tasks=1 29 Launched reduce tasks=1 30 Data-local map tasks=1 31 Total time spent by all maps in occupied slots (ms)=2275 32 Total time spent by all reduces in occupied slots (ms)=2598 33 Total time spent by all map tasks (ms)=2275 34 Total time spent by all reduce tasks (ms)=2598 35 Total vcore-seconds taken by all map tasks=2275 36 Total vcore-seconds taken by all reduce tasks=2598 37 Total megabyte-seconds taken by all map tasks=2329600 38 Total megabyte-seconds taken by all reduce tasks=2660352 39 Map-Reduce Framework 40 Map input records=8 41 Map output records=20 42 Map output bytes=154 43 Map output materialized bytes=54 44 Input split bytes=88 45 Combine input records=20 46 Combine output records=5 47 Reduce input groups=5 48 Reduce shuffle bytes=54 49 Reduce input records=5 50 Reduce output records=5 51 Spilled Records=10 52 Shuffled Maps =1 53 Failed Shuffles=0 54 Merged Map outputs=1 55 GC time elapsed (ms)=47 56 CPU time spent (ms)=1260 57 Physical memory (bytes) snapshot=421257216 58 Virtual memory (bytes) snapshot=1647611904 59 Total committed heap usage (bytes)=402653184 60 Shuffle Errors 61 BAD_ID=0 62 CONNECTION=0 63 IO_ERROR=0 64 WRONG_LENGTH=0 65 WRONG_MAP=0 66 WRONG_REDUCE=0 67 File Input Format Counters 68 Bytes Read=78 69 File Output Format Counters 70 Bytes Written=28
>生成结果文件wordcount目录下的part-r-00000,用hadoop命令查看生成文件
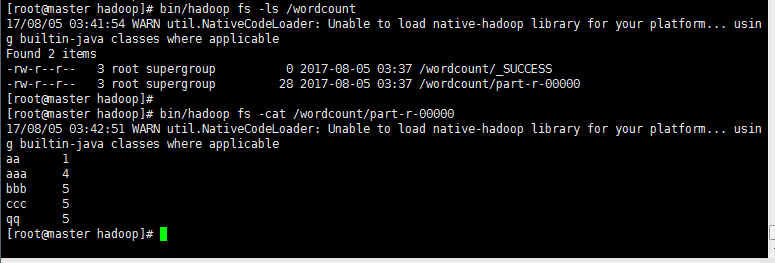
三 二次排序
MR默认会对键进行排序,然而有的时候我们也有对值进行排序的需求。满足这种需求一是可以在reduce阶段排序收集过来的values,但是,如果有数量巨大的values可能就会导致内存溢出等问题,这就是二次排序应用的场景——将对值的排序也安排到MR计算过程之中,而不是单独来做。
二次排序就是首先按照第一字段排序,然后再对第一字段相同的行按照第二字段排序,注意不能破坏第一次排序的结果。
!需排序文件secsortdata.txt
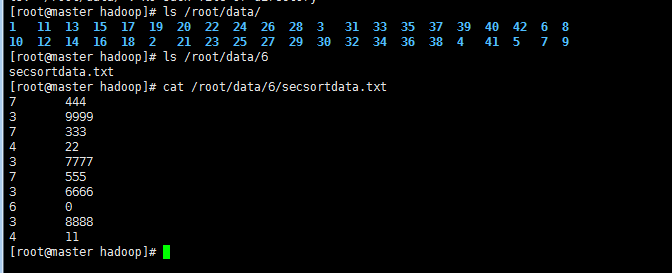
1' 编写程序IntPair 类和主类 SecondarySort类
同第一个实验在eclipse编程的创建方法!
程序主要难点在于排序和聚合。
对于排序我们需要定义一个IntPair类用于数据的存储,并在IntPair类内部自定义Comparator类以实现第一字段和第二字段的比较。
对于聚合我们需要定义一个FirstPartitioner类,在FirstPartitioner类内部指定聚合规则为第一字段。
此外,我们还需要开启MapReduce框架自定义Partitioner 功能和GroupingComparator功能。
Inpair.java
1 package mr; 2 3 import java.io.DataInput; 4 import java.io.DataOutput; 5 import java.io.IOException; 6 7 import org.apache.hadoop.io.IntWritable; 8 import org.apache.hadoop.io.WritableComparable; 9 10 public class IntPair implements WritableComparable<IntPair> { 11 private IntWritable first; 12 private IntWritable second; 13 public void set(IntWritable first, IntWritable second) { 14 this.first = first; 15 this.second = second; 16 } 17 //注意:需要添加无参的构造方法,否则反射时会报错。 18 public IntPair() { 19 set(new IntWritable(), new IntWritable()); 20 } 21 public IntPair(int first, int second) { 22 set(new IntWritable(first), new IntWritable(second)); 23 } 24 public IntPair(IntWritable first, IntWritable second) { 25 set(first, second); 26 } 27 public IntWritable getFirst() { 28 return first; 29 } 30 public void setFirst(IntWritable first) { 31 this.first = first; 32 } 33 public IntWritable getSecond() { 34 return second; 35 } 36 public void setSecond(IntWritable second) { 37 this.second = second; 38 } 39 public void write(DataOutput out) throws IOException { 40 first.write(out); 41 second.write(out); 42 } 43 public void readFields(DataInput in) throws IOException { 44 first.readFields(in); 45 second.readFields(in); 46 } 47 public int hashCode() { 48 return first.hashCode() * 163 + second.hashCode(); 49 } 50 public boolean equals(Object o) { 51 if (o instanceof IntPair) { 52 IntPair tp = (IntPair) o; 53 return first.equals(tp.first) && second.equals(tp.second); 54 } 55 return false; 56 } 57 public String toString() { 58 return first + "\t" + second; 59 } 60 public int compareTo(IntPair tp) { 61 int cmp = first.compareTo(tp.first); 62 if (cmp != 0) { 63 return cmp; 64 } 65 return second.compareTo(tp.second); 66 } 67 }
secsortdata.java
1 package mr; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.conf.Configuration; 6 import org.apache.hadoop.fs.Path; 7 import org.apache.hadoop.io.LongWritable; 8 import org.apache.hadoop.io.NullWritable; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.io.WritableComparable; 11 import org.apache.hadoop.io.WritableComparator; 12 import org.apache.hadoop.mapreduce.Job; 13 import org.apache.hadoop.mapreduce.Mapper; 14 import org.apache.hadoop.mapreduce.Partitioner; 15 import org.apache.hadoop.mapreduce.Reducer; 16 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 17 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 18 19 public class SecondarySort { 20 static class TheMapper extends Mapper<LongWritable, Text, IntPair, NullWritable> { 21 @Override 22 protected void map(LongWritable key, Text value, Context context) 23 throws IOException, InterruptedException { 24 String[] fields = value.toString().split("\t"); 25 int field1 = Integer.parseInt(fields[0]); 26 int field2 = Integer.parseInt(fields[1]); 27 context.write(new IntPair(field1,field2), NullWritable.get()); 28 } 29 } 30 static class TheReducer extends Reducer<IntPair, NullWritable,IntPair, NullWritable> { 31 //private static final Text SEPARATOR = new Text("------------------------------------------------"); 32 @Override 33 protected void reduce(IntPair key, Iterable<NullWritable> values, Context context) 34 throws IOException, InterruptedException { 35 context.write(key, NullWritable.get()); 36 } 37 } 38 public static class FirstPartitioner extends Partitioner<IntPair, NullWritable> { 39 public int getPartition(IntPair key, NullWritable value, 40 int numPartitions) { 41 return Math.abs(key.getFirst().get()) % numPartitions; 42 } 43 } 44 //如果不添加这个类,默认第一列和第二列都是升序排序的。 45 //这个类的作用是使第一列升序排序,第二列降序排序 46 public static class KeyComparator extends WritableComparator { 47 //无参构造器必须加上,否则报错。 48 protected KeyComparator() { 49 super(IntPair.class, true); 50 } 51 public int compare(WritableComparable a, WritableComparable b) { 52 IntPair ip1 = (IntPair) a; 53 IntPair ip2 = (IntPair) b; 54 //第一列按升序排序 55 int cmp = ip1.getFirst().compareTo(ip2.getFirst()); 56 if (cmp != 0) { 57 return cmp; 58 } 59 //在第一列相等的情况下,第二列按倒序排序 60 return -ip1.getSecond().compareTo(ip2.getSecond()); 61 } 62 } 63 //入口程序 64 public static void main(String[] args) throws Exception { 65 Configuration conf = new Configuration(); 66 Job job = Job.getInstance(conf); 67 job.setJarByClass(SecondarySort.class); 68 //设置Mapper的相关属性 69 job.setMapperClass(TheMapper.class); 70 //当Mapper中的输出的key和value的类型和Reduce输出 71 //的key和value的类型相同时,以下两句可以省略。 72 //job.setMapOutputKeyClass(IntPair.class); 73 //job.setMapOutputValueClass(NullWritable.class); 74 FileInputFormat.setInputPaths(job, new Path(args[0])); 75 //设置分区的相关属性 76 job.setPartitionerClass(FirstPartitioner.class); 77 //在map中对key进行排序 78 job.setSortComparatorClass(KeyComparator.class); 79 //job.setGroupingComparatorClass(GroupComparator.class); 80 //设置Reducer的相关属性 81 job.setReducerClass(TheReducer.class); 82 job.setOutputKeyClass(IntPair.class); 83 job.setOutputValueClass(NullWritable.class); 84 FileOutputFormat.setOutputPath(job, new Path(args[1])); 85 //设置Reducer数量 86 int reduceNum = 1; 87 if(args.length >= 3 && args[2] != null){ 88 reduceNum = Integer.parseInt(args[2]); 89 } 90 job.setNumReduceTasks(reduceNum); 91 job.waitForCompletion(true); 92 } 93 }
2’ 打包提交
使用Eclipse开发工具将该代码打包,选择主类为mr.Secondary。如果没有指定主类,那么在执行时就要指定须执行的类。假定打包后的文件名为Secondary.jar,主类SecondarySort位于包mr下,则可使用如下命令向Hadoop集群提交本应用。
bin/hadoop jar hdpAction6.jar mr.Secondary /user/mapreduce/secsort/in/secsortdata.txt /user/mapreduce/secsort/out 1
其中“hadoop”为命令,“jar”为命令参数,后面紧跟打的包,/user/mapreduce/secsort/in/secsortdata.txt”为输入文件在HDFS中的位置,如果HDFS中没有这个文件,则自己自行上传。“/user/mapreduce/secsort/out/”为输出文件在HDFS中的位置,“1”为Reduce个数。
如果打包时已经设定了主类,此时命令中无需再次输入定义主类!
(上传secsortdata.txt到HDFS 命令: ” hadoop fs -put 目标文件包括路径 hdfs路径 “)
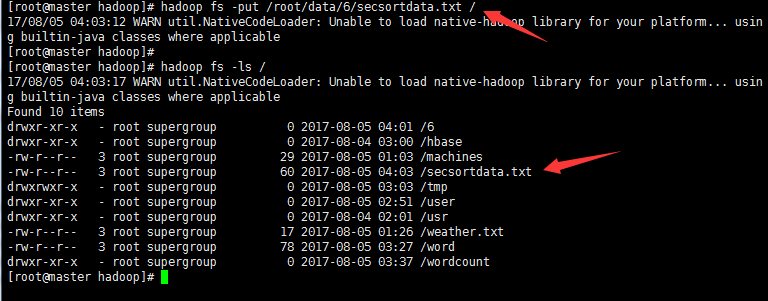
显示结果:
1 [root@master hadoop]# bin/hadoop jar SecondarySort.jar /secsortdata.txt /user/mapreduce/secsort/out 1 2 Not a valid JAR: /usr/cstor/hadoop/SecondarySort.jar 3 [root@master hadoop]# bin/hadoop jar hdpAction6.jar /secsortdata.txt /user/mapreduce/secsort/out 1 4 17/08/05 04:05:48 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 5 17/08/05 04:05:49 INFO client.RMProxy: Connecting to ResourceManager at master/10.1.21.27:8032 6 17/08/05 04:05:49 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 7 17/08/05 04:05:50 INFO input.FileInputFormat: Total input paths to process : 1 8 17/08/05 04:05:50 INFO mapreduce.JobSubmitter: number of splits:1 9 17/08/05 04:05:50 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1501872322130_0007 10 17/08/05 04:05:50 INFO impl.YarnClientImpl: Submitted application application_1501872322130_0007 11 17/08/05 04:05:50 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1501872322130_0007/ 12 17/08/05 04:05:50 INFO mapreduce.Job: Running job: job_1501872322130_0007 13 17/08/05 04:05:56 INFO mapreduce.Job: Job job_1501872322130_0007 running in uber mode : false 14 17/08/05 04:05:56 INFO mapreduce.Job: map 0% reduce 0% 15 17/08/05 04:06:00 INFO mapreduce.Job: map 100% reduce 0% 16 17/08/05 04:06:05 INFO mapreduce.Job: map 100% reduce 100% 17 17/08/05 04:06:06 INFO mapreduce.Job: Job job_1501872322130_0007 completed successfully 18 17/08/05 04:06:07 INFO mapreduce.Job: Counters: 49 19 File System Counters 20 FILE: Number of bytes read=106 21 FILE: Number of bytes written=230897 22 FILE: Number of read operations=0 23 FILE: Number of large read operations=0 24 FILE: Number of write operations=0 25 HDFS: Number of bytes read=159 26 HDFS: Number of bytes written=60 27 HDFS: Number of read operations=6 28 HDFS: Number of large read operations=0 29 HDFS: Number of write operations=2 30 Job Counters 31 Launched map tasks=1 32 Launched reduce tasks=1 33 Data-local map tasks=1 34 Total time spent by all maps in occupied slots (ms)=2534 35 Total time spent by all reduces in occupied slots (ms)=2799 36 Total time spent by all map tasks (ms)=2534 37 Total time spent by all reduce tasks (ms)=2799 38 Total vcore-seconds taken by all map tasks=2534 39 Total vcore-seconds taken by all reduce tasks=2799 40 Total megabyte-seconds taken by all map tasks=2594816 41 Total megabyte-seconds taken by all reduce tasks=2866176 42 Map-Reduce Framework 43 Map input records=10 44 Map output records=10 45 Map output bytes=80 46 Map output materialized bytes=106 47 Input split bytes=99 48 Combine input records=0 49 Combine output records=0 50 Reduce input groups=10 51 Reduce shuffle bytes=106 52 Reduce input records=10 53 Reduce output records=10 54 Spilled Records=20 55 Shuffled Maps =1 56 Failed Shuffles=0 57 Merged Map outputs=1 58 GC time elapsed (ms)=55 59 CPU time spent (ms)=1490 60 Physical memory (bytes) snapshot=419209216 61 Virtual memory (bytes) snapshot=1642618880 62 Total committed heap usage (bytes)=402653184 63 Shuffle Errors 64 BAD_ID=0 65 CONNECTION=0 66 IO_ERROR=0 67 WRONG_LENGTH=0 68 WRONG_MAP=0 69 WRONG_REDUCE=0 70 File Input Format Counters 71 Bytes Read=60 72 File Output Format Counters 73 Bytes Written=60
生成文件显示二次排序结果:
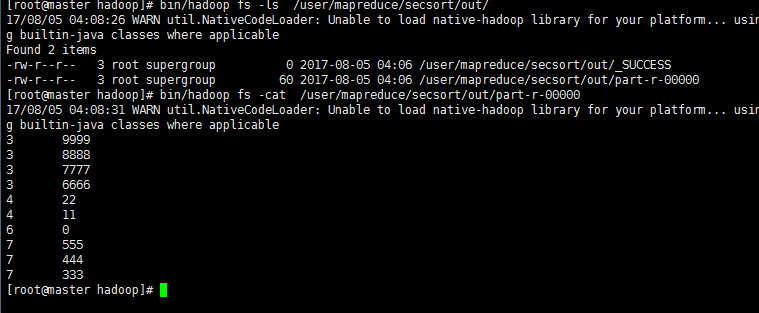
四 计数器
1‘ MapReduce计数器是什么?
计数器是用来记录job的执行进度和状态的。它的作用可以理解为日志。我们可以在程序的某个位置插入计数器,记录数据或者进度的变化情况。
MapReduce计数器能做什么?
MapReduce 计数器(Counter)为我们提供一个窗口,用于观察 MapReduce Job 运行期的各种细节数据。对MapReduce性能调优很有帮助,MapReduce性能优化的评估大部分都是基于这些 Counter 的数值表现出来的。
在许多情况下,一个用户需要了解待分析的数据,尽管这并非所要执行的分析任务 的核心内容。以统计数据集中无效记录数目的任务为例,如果发现无效记录的比例 相当高,那么就需要认真思考为何存在如此多无效记录。是所采用的检测程序存在 缺陷,还是数据集质量确实很低,包含大量无效记录?如果确定是数据集的质量问 题,则可能需要扩大数据集的规模,以增大有效记录的比例,从而进行有意义的分析。
计数器是一种收集作业统计信息的有效手段,用于质量控制或应用级统计。计数器 还可辅助诊断系统故障。如果需要将日志信息传输到map或reduce任务,更好的 方法通常是尝试传输计数器值以监测某一特定事件是否发生。对于大型分布式作业 而言,使用计数器更为方便。首先,获取计数器值比输出日志更方便,其次,根据 计数器值统计特定事件的发生次数要比分析一堆日志文件容易得多。
内置计数器
MapReduce 自带了许多默认Counter,现在我们来分析这些默认 Counter 的含义,方便大家观察 Job 结果,如输入的字节数、输出的字节数、Map端输入/输出的字节数和条数、Reduce端的输入/输出的字节数和条数等。下面我们只需了解这些内置计数器,知道计数器组名称(groupName)和计数器名称(counterName),以后使用计数器会查找groupName和counterName即可。
自定义计数器
MapReduce允许用户编写程序来定义计数器,计数器的值可在mapper或reducer 中增加。多个计数器由一个Java枚举(enum)类型来定义,以便对计数器分组。一个作业可以定义的枚举类型数量不限,各个枚举类型所包含的字段数量也不限。枚 举类型的名称即为组的名称,枚举类型的字段就是计数器名称。计数器是全局的。换言之,MapReduce框架将跨所有map和reduce聚集这些计数器,并在作业结束 时产生一个最终结果。
2’ >编辑计数文件counters.txt
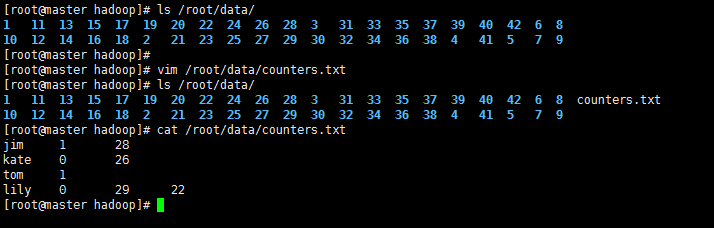
>上传该文件到HDFS
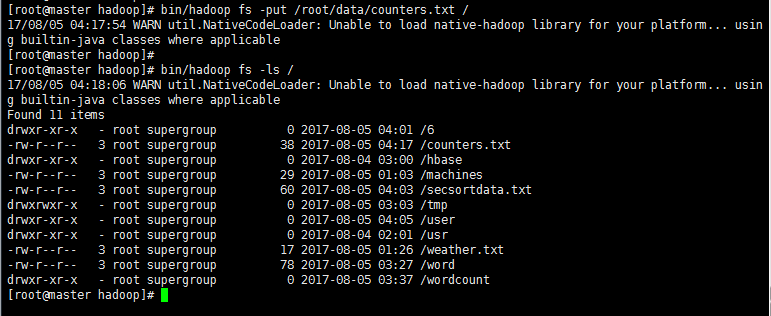
3' 编写程序Counters.java
1 package mr ; 2 import java.io.IOException; 3 import org.apache.hadoop.conf.Configuration; 4 import org.apache.hadoop.fs.Path; 5 import org.apache.hadoop.io.LongWritable; 6 import org.apache.hadoop.io.Text; 7 import org.apache.hadoop.mapreduce.Counter; 8 import org.apache.hadoop.mapreduce.Job; 9 import org.apache.hadoop.mapreduce.Mapper; 10 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 11 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 12 import org.apache.hadoop.util.GenericOptionsParser; 13 14 public class Counters { 15 public static class MyCounterMap extends Mapper<LongWritable, Text, Text, Text> { 16 public static Counter ct = null; 17 protected void map(LongWritable key, Text value, 18 org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, Text>.Context context) 19 throws java.io.IOException, InterruptedException { 20 String arr_value[] = value.toString().split("\t"); 21 if (arr_value.length > 3) { 22 ct = context.getCounter("ErrorCounter", "toolong"); // ErrorCounter为组名,toolong为组员名 23 ct.increment(1); // 计数器加一 24 } else if (arr_value.length < 3) { 25 ct = context.getCounter("ErrorCounter", "tooshort"); 26 ct.increment(1); 27 } 28 } 29 } 30 public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException { 31 Configuration conf = new Configuration(); 32 String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); 33 if (otherArgs.length != 2) { 34 System.err.println("Usage: Counters <in> <out>"); 35 System.exit(2); 36 } 37 Job job = new Job(conf, "Counter"); 38 job.setJarByClass(Counters.class); 39 40 job.setMapperClass(MyCounterMap.class); 41 42 FileInputFormat.addInputPath(job, new Path(otherArgs[0])); 43 FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); 44 System.exit(job.waitForCompletion(true) ? 0 : 1); 45 } 46 }
4' 打包并提交
使用Eclipse开发工具将该代码打包,选择主类为mr.Counters。假定打包后的文件名为hdpAction7.jar,主类Counters位于包mr下,则可使用如下命令向Hadoop集群提交本应用。
bin/hadoop jar hdpAction7.jar mr.Counters /counters.txt /usr/counters/out
其中“hadoop”为命令,“jar”为命令参数,后面紧跟打包。 “/usr/counts/in/counts.txt”为输入文件在HDFS中的位置(如果没有,自行上传),“/usr/counts/out”为输出文件在HDFS中的位置。
显示结果:
1 [root@master hadoop]# bin/hadoop jar hdpAction7.jar /counters.txt /usr/counters/out 2 17/08/05 04:22:58 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 3 17/08/05 04:22:59 INFO client.RMProxy: Connecting to ResourceManager at master/10.1.21.27:8032 4 17/08/05 04:23:00 INFO input.FileInputFormat: Total input paths to process : 1 5 17/08/05 04:23:00 INFO mapreduce.JobSubmitter: number of splits:1 6 17/08/05 04:23:00 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1501872322130_0008 7 17/08/05 04:23:00 INFO impl.YarnClientImpl: Submitted application application_1501872322130_0008 8 17/08/05 04:23:00 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1501872322130_0008/ 9 17/08/05 04:23:00 INFO mapreduce.Job: Running job: job_1501872322130_0008 10 17/08/05 04:23:05 INFO mapreduce.Job: Job job_1501872322130_0008 running in uber mode : false 11 17/08/05 04:23:05 INFO mapreduce.Job: map 0% reduce 0% 12 17/08/05 04:23:10 INFO mapreduce.Job: map 100% reduce 0% 13 17/08/05 04:23:15 INFO mapreduce.Job: map 100% reduce 100% 14 17/08/05 04:23:16 INFO mapreduce.Job: Job job_1501872322130_0008 completed successfully 15 17/08/05 04:23:16 INFO mapreduce.Job: Counters: 51 16 File System Counters 17 FILE: Number of bytes read=6 18 FILE: Number of bytes written=229309 19 FILE: Number of read operations=0 20 FILE: Number of large read operations=0 21 FILE: Number of write operations=0 22 HDFS: Number of bytes read=134 23 HDFS: Number of bytes written=0 24 HDFS: Number of read operations=6 25 HDFS: Number of large read operations=0 26 HDFS: Number of write operations=2 27 Job Counters 28 Launched map tasks=1 29 Launched reduce tasks=1 30 Data-local map tasks=1 31 Total time spent by all maps in occupied slots (ms)=2400 32 Total time spent by all reduces in occupied slots (ms)=2472 33 Total time spent by all map tasks (ms)=2400 34 Total time spent by all reduce tasks (ms)=2472 35 Total vcore-seconds taken by all map tasks=2400 36 Total vcore-seconds taken by all reduce tasks=2472 37 Total megabyte-seconds taken by all map tasks=2457600 38 Total megabyte-seconds taken by all reduce tasks=2531328 39 Map-Reduce Framework 40 Map input records=4 41 Map output records=0 42 Map output bytes=0 43 Map output materialized bytes=6 44 Input split bytes=96 45 Combine input records=0 46 Combine output records=0 47 Reduce input groups=0 48 Reduce shuffle bytes=6 49 Reduce input records=0 50 Reduce output records=0 51 Spilled Records=0 52 Shuffled Maps =1 53 Failed Shuffles=0 54 Merged Map outputs=1 55 GC time elapsed (ms)=143 56 CPU time spent (ms)=1680 57 Physical memory (bytes) snapshot=413036544 58 Virtual memory (bytes) snapshot=1630470144 59 Total committed heap usage (bytes)=402653184 60 ErrorCounter 61 toolong=1 62 tooshort=1 63 Shuffle Errors 64 BAD_ID=0 65 CONNECTION=0 66 IO_ERROR=0 67 WRONG_LENGTH=0 68 WRONG_MAP=0 69 WRONG_REDUCE=0 70 File Input Format Counters 71 Bytes Read=38 72 File Output Format Counters 73 Bytes Written=0 74 [root@master hadoop]#
五 join操作
1' 概述
对于RDBMS中的Join操作大伙一定非常熟悉,写SQL的时候要十分注意细节,稍有差池就会耗时巨久造成很大的性能瓶颈,而在Hadoop中使用MapReduce框架进行Join的操作时同样耗时,但是由于Hadoop的分布式设计理念的特殊性,因此对于这种Join操作同样也具备了一定的特殊性。
原理
使用MapReduce实现Join操作有多种实现方式:
>在Reduce端连接为最为常见的模式:
Map端的主要工作:为来自不同表(文件)的key/value对打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。
Reduce端的主要工作:在Reduce端以连接字段作为key的分组已经完成,我们只需要在每一个分组当中将那些来源于不同文件的记录(在map阶段已经打标志)分开,最后进行笛卡尔只就OK了。
>在Map端进行连接
使用场景:一张表十分小、一张表很大。
用法:在提交作业的时候先将小表文件放到该作业的DistributedCache中,然后从DistributeCache中取出该小表进行Join key / value解释分割放到内存中(可以放大Hash Map等等容器中)。然后扫描大表,看大表中的每条记录的Join key /value值是否能够在内存中找到相同Join key的记录,如果有则直接输出结果。
>SemiJoin
SemiJoin就是所谓的半连接,其实仔细一看就是Reduce Join的一个变种,就是在map端过滤掉一些数据,在网络中只传输参与连接的数据不参与连接的数据不必在网络中进行传输,从而减少了shuffle的网络传输量,使整体效率得到提高,其他思想和Reduce Join是一模一样的。说得更加接地气一点就是将小表中参与Join的key单独抽出来通过DistributedCach分发到相关节点,然后将其取出放到内存中(可以放到HashSet中),在map阶段扫描连接表,将Join key不在内存HashSet中的记录过滤掉,让那些参与Join的记录通过shuffle传输到Reduce端进行Join操作,其他的和Reduce Join都是一样的
2' >创建两个表文件data.txt 和 info.txt

>上传到HDFS
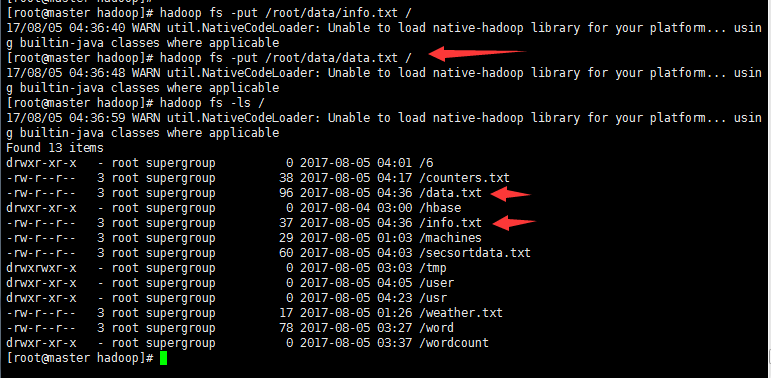
3‘ 编写程序MRJoin.java
程序分析执行过程如下:
在map阶段,把所有记录标记成<key, value>的形式,其中key是1003/1004/1005/1006的字段值,value则根据来源不同取不同的形式:来源于表A的记录,value的值为“201001 abc”等值;来源于表B的记录,value的值为”kaka“之类的值。
在Reduce阶段,先把每个key下的value列表拆分为分别来自表A和表B的两部分,分别放入两个向量中。然后遍历两个向量做笛卡尔积,形成一条条最终结果。
代码如下:
1 package mr; 2 3 import java.io.DataInput; 4 import java.io.DataOutput; 5 import java.io.IOException; 6 7 import org.apache.hadoop.conf.Configuration; 8 import org.apache.hadoop.fs.Path; 9 import org.apache.hadoop.io.LongWritable; 10 import org.apache.hadoop.io.Text; 11 import org.apache.hadoop.io.WritableComparable; 12 import org.apache.hadoop.io.WritableComparator; 13 import org.apache.hadoop.mapreduce.Job; 14 import org.apache.hadoop.mapreduce.Mapper; 15 import org.apache.hadoop.mapreduce.Partitioner; 16 import org.apache.hadoop.mapreduce.Reducer; 17 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 18 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 19 import org.apache.hadoop.mapreduce.lib.input.FileSplit; 20 import org.apache.hadoop.util.GenericOptionsParser; 21 22 public class MRJoin { 23 public static class MR_Join_Mapper extends Mapper<LongWritable, Text, TextPair, Text> { 24 @Override 25 protected void map(LongWritable key, Text value, Context context) 26 throws IOException, InterruptedException { 27 // 获取输入文件的全路径和名称 28 String pathName = ((FileSplit) context.getInputSplit()).getPath().toString(); 29 if (pathName.contains("data.txt")) { 30 String values[] = value.toString().split("\t"); 31 if (values.length < 3) { 32 // data数据格式不规范,字段小于3,抛弃数据 33 return; 34 } else { 35 // 数据格式规范,区分标识为1 36 TextPair tp = new TextPair(new Text(values[1]), new Text("1")); 37 context.write(tp, new Text(values[0] + "\t" + values[2])); 38 } 39 } 40 if (pathName.contains("info.txt")) { 41 String values[] = value.toString().split("\t"); 42 if (values.length < 2) { 43 // data数据格式不规范,字段小于2,抛弃数据 44 return; 45 } else { 46 // 数据格式规范,区分标识为0 47 TextPair tp = new TextPair(new Text(values[0]), new Text("0")); 48 context.write(tp, new Text(values[1])); 49 } 50 } 51 } 52 } 53 54 public static class MR_Join_Partitioner extends Partitioner<TextPair, Text> { 55 @Override 56 public int getPartition(TextPair key, Text value, int numParititon) { 57 return Math.abs(key.getFirst().hashCode() * 127) % numParititon; 58 } 59 } 60 61 public static class MR_Join_Comparator extends WritableComparator { 62 public MR_Join_Comparator() { 63 super(TextPair.class, true); 64 } 65 66 public int compare(WritableComparable a, WritableComparable b) { 67 TextPair t1 = (TextPair) a; 68 TextPair t2 = (TextPair) b; 69 return t1.getFirst().compareTo(t2.getFirst()); 70 } 71 } 72 73 public static class MR_Join_Reduce extends Reducer<TextPair, Text, Text, Text> { 74 protected void Reduce(TextPair key, Iterable<Text> values, Context context) 75 throws IOException, InterruptedException { 76 Text pid = key.getFirst(); 77 String desc = values.iterator().next().toString(); 78 while (values.iterator().hasNext()) { 79 context.write(pid, new Text(values.iterator().next().toString() + "\t" + desc)); 80 } 81 } 82 } 83 84 85 public static void main(String agrs[]) 86 throws IOException, InterruptedException, ClassNotFoundException { 87 Configuration conf = new Configuration(); 88 GenericOptionsParser parser = new GenericOptionsParser(conf, agrs); 89 String[] otherArgs = parser.getRemainingArgs(); 90 if (agrs.length < 3) { 91 System.err.println("Usage: MRJoin <in_path_one> <in_path_two> <output>"); 92 System.exit(2); 93 } 94 95 Job job = new Job(conf, "MRJoin"); 96 // 设置运行的job 97 job.setJarByClass(MRJoin.class); 98 // 设置Map相关内容 99 job.setMapperClass(MR_Join_Mapper.class); 100 // 设置Map的输出 101 job.setMapOutputKeyClass(TextPair.class); 102 job.setMapOutputValueClass(Text.class); 103 // 设置partition 104 job.setPartitionerClass(MR_Join_Partitioner.class); 105 // 在分区之后按照指定的条件分组 106 job.setGroupingComparatorClass(MR_Join_Comparator.class); 107 // 设置Reduce 108 job.setReducerClass(MR_Join_Reduce.class); 109 // 设置Reduce的输出 110 job.setOutputKeyClass(Text.class); 111 job.setOutputValueClass(Text.class); 112 // 设置输入和输出的目录 113 FileInputFormat.addInputPath(job, new Path(otherArgs[0])); 114 FileInputFormat.addInputPath(job, new Path(otherArgs[1])); 115 FileOutputFormat.setOutputPath(job, new Path(otherArgs[2])); 116 // 执行,直到结束就退出 117 System.exit(job.waitForCompletion(true) ? 0 : 1); 118 } 119 } 120 121 class TextPair implements WritableComparable<TextPair> { 122 private Text first; 123 private Text second; 124 125 public TextPair() { 126 set(new Text(), new Text()); 127 } 128 129 public TextPair(String first, String second) { 130 set(new Text(first), new Text(second)); 131 } 132 133 public TextPair(Text first, Text second) { 134 set(first, second); 135 } 136 137 public void set(Text first, Text second) { 138 this.first = first; 139 this.second = second; 140 } 141 142 public Text getFirst() { 143 return first; 144 } 145 146 public Text getSecond() { 147 return second; 148 } 149 150 public void write(DataOutput out) throws IOException { 151 first.write(out); 152 second.write(out); 153 } 154 155 public void readFields(DataInput in) throws IOException { 156 first.readFields(in); 157 second.readFields(in); 158 } 159 160 public int compareTo(TextPair tp) { 161 int cmp = first.compareTo(tp.first); 162 if (cmp != 0) { 163 return cmp; 164 } 165 return second.compareTo(tp.second); 166 } 167 }
4’ 打包并提交
使用Eclipse开发工具将该代码打包,假定打包后的文件名为hdpAction8.jar,主类MRJoin位于包mr下,则可使用如下命令向Hadoop集群提交本应用。
bin/hadoop jar hdpAction8.jar mr.MRJoin /data.txt /info.txt /usr/MRJoin/out
其中“hadoop”为命令,“jar”为命令参数,后面紧跟打包。 “/data.txt”和 “/info.txt”为输入文件在HDFS中的位置,“/usr/MRJoin/out”为输出文件在HDFS中的位置。
执行结果如下:
1 [root@master hadoop]# bin/hadoop jar hdpAction8.jar /data.txt /info.txt /usr/MRJoin/out 2 17/08/05 04:38:11 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 3 17/08/05 04:38:12 INFO client.RMProxy: Connecting to ResourceManager at master/10.1.21.27:8032 4 17/08/05 04:38:13 INFO input.FileInputFormat: Total input paths to process : 2 5 17/08/05 04:38:13 INFO mapreduce.JobSubmitter: number of splits:2 6 17/08/05 04:38:13 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1501872322130_0009 7 17/08/05 04:38:13 INFO impl.YarnClientImpl: Submitted application application_1501872322130_0009 8 17/08/05 04:38:13 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1501872322130_0009/ 9 17/08/05 04:38:13 INFO mapreduce.Job: Running job: job_1501872322130_0009 10 17/08/05 04:38:18 INFO mapreduce.Job: Job job_1501872322130_0009 running in uber mode : false 11 17/08/05 04:38:18 INFO mapreduce.Job: map 0% reduce 0% 12 17/08/05 04:38:23 INFO mapreduce.Job: map 100% reduce 0% 13 17/08/05 04:38:28 INFO mapreduce.Job: map 100% reduce 100% 14 17/08/05 04:38:28 INFO mapreduce.Job: Job job_1501872322130_0009 completed successfully 15 17/08/05 04:38:29 INFO mapreduce.Job: Counters: 49 16 File System Counters 17 FILE: Number of bytes read=179 18 FILE: Number of bytes written=347823 19 FILE: Number of read operations=0 20 FILE: Number of large read operations=0 21 FILE: Number of write operations=0 22 HDFS: Number of bytes read=317 23 HDFS: Number of bytes written=283 24 HDFS: Number of read operations=9 25 HDFS: Number of large read operations=0 26 HDFS: Number of write operations=2 27 Job Counters 28 Launched map tasks=2 29 Launched reduce tasks=1 30 Data-local map tasks=2 31 Total time spent by all maps in occupied slots (ms)=5122 32 Total time spent by all reduces in occupied slots (ms)=2685 33 Total time spent by all map tasks (ms)=5122 34 Total time spent by all reduce tasks (ms)=2685 35 Total vcore-seconds taken by all map tasks=5122 36 Total vcore-seconds taken by all reduce tasks=2685 37 Total megabyte-seconds taken by all map tasks=5244928 38 Total megabyte-seconds taken by all reduce tasks=2749440 39 Map-Reduce Framework 40 Map input records=10 41 Map output records=10 42 Map output bytes=153 43 Map output materialized bytes=185 44 Input split bytes=184 45 Combine input records=0 46 Combine output records=0 47 Reduce input groups=4 48 Reduce shuffle bytes=185 49 Reduce input records=10 50 Reduce output records=10 51 Spilled Records=20 52 Shuffled Maps =2 53 Failed Shuffles=0 54 Merged Map outputs=2 55 GC time elapsed (ms)=122 56 CPU time spent (ms)=2790 57 Physical memory (bytes) snapshot=680472576 58 Virtual memory (bytes) snapshot=2443010048 59 Total committed heap usage (bytes)=603979776 60 Shuffle Errors 61 BAD_ID=0 62 CONNECTION=0 63 IO_ERROR=0 64 WRONG_LENGTH=0 65 WRONG_MAP=0 66 WRONG_REDUCE=0 67 File Input Format Counters 68 Bytes Read=133 69 File Output Format Counters 70 Bytes Written=283 71 [root@master hadoop]#
> 生成join后的文件在/usr/MRJoin/out目录下:
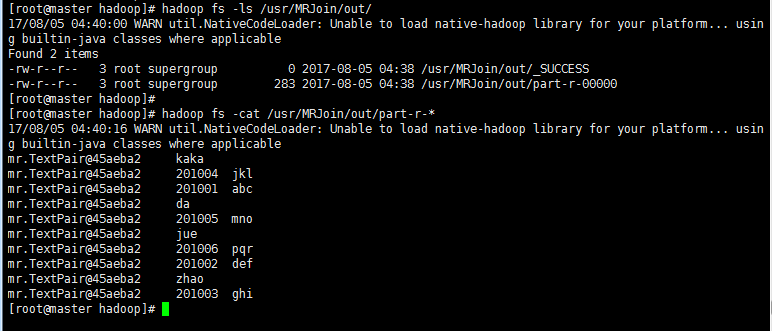
六 分布式缓存
1‘ 假定现有一个大为100G的大表big.txt和一个大小为1M的小表small.txt,请基于MapReduce思想编程实现判断小表中单词在大表中出现次数。也即所谓的“扫描大表、加载小表”。
为解决上述问题,可开启10个Map。这样,每个Map只需处理总量的1/10,将大大加快处理。而在单独Map内,直接用HashSet加载“1M小表”,对于存在硬盘(Map处理时会将HDFS文件拷贝至本地)的10G大文件,则逐条扫描,这就是所谓的“扫描大表、加载小表”,也即分布式缓存。
2’ >新建两个txt文件
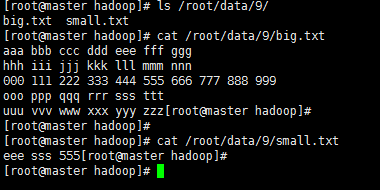
>上传到HDFS
首先登录client机,查看HDFS里是否已存在目录“/user/root/mr/in”,若不存在,使用下述命令新建该目录。
/usr/cstor/hadoop/bin/hdfs dfs -mkdir -p /user/root/mr/in

接着,使用下述命令将client机本地文件“/root/data/9/big.txt”和“/root/data/9/ small.txt”上传至HDFS的“/user/root/mr/in”目录:
/usr/cstor/hadoop/bin/hdfs dfs -put /root/data/9/big.txt /user/root/mr/in
/usr/cstor/hadoop/bin/hdfs dfs -put /root/data/9/small.txt /user/root/mr/in
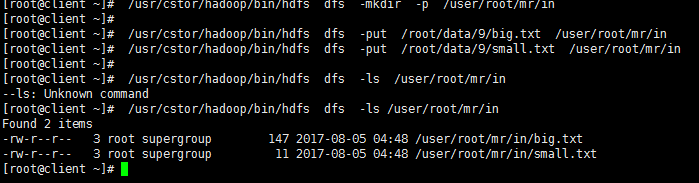
3‘ 编写代码,新建BigAndSmallTable类并指定包名(代码中为cn.cstor.mr),在BigAndSmallTable.java文件中
依次写入如下代码:
1 package cn.cstor.mr; 2 3 import java.io.IOException; 4 import java.util.HashSet; 5 6 import org.apache.hadoop.conf.Configuration; 7 import org.apache.hadoop.fs.FSDataInputStream; 8 import org.apache.hadoop.fs.FileSystem; 9 import org.apache.hadoop.fs.Path; 10 import org.apache.hadoop.io.IntWritable; 11 import org.apache.hadoop.io.Text; 12 import org.apache.hadoop.mapreduce.Job; 13 import org.apache.hadoop.mapreduce.Mapper; 14 import org.apache.hadoop.mapreduce.Reducer; 15 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 16 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 17 import org.apache.hadoop.util.LineReader; 18 19 public class BigAndSmallTable { 20 public static class TokenizerMapper extends 21 Mapper<Object, Text, Text, IntWritable> { 22 private final static IntWritable one = new IntWritable(1); 23 private static HashSet<String> smallTable = null; 24 25 protected void setup(Context context) throws IOException, 26 InterruptedException { 27 smallTable = new HashSet<String>(); 28 Path smallTablePath = new Path(context.getConfiguration().get( 29 "smallTableLocation")); 30 FileSystem hdfs = smallTablePath.getFileSystem(context 31 .getConfiguration()); 32 FSDataInputStream hdfsReader = hdfs.open(smallTablePath); 33 Text line = new Text(); 34 LineReader lineReader = new LineReader(hdfsReader); 35 while (lineReader.readLine(line) > 0) { 36 // you can do something here 37 String[] values = line.toString().split(" "); 38 for (int i = 0; i < values.length; i++) { 39 smallTable.add(values[i]); 40 System.out.println(values[i]); 41 } 42 } 43 lineReader.close(); 44 hdfsReader.close(); 45 System.out.println("setup ok *^_^* "); 46 } 47 48 public void map(Object key, Text value, Context context) 49 throws IOException, InterruptedException { 50 String[] values = value.toString().split(" "); 51 for (int i = 0; i < values.length; i++) { 52 if (smallTable.contains(values[i])) { 53 context.write(new Text(values[i]), one); 54 } 55 } 56 } 57 } 58 59 public static class IntSumReducer extends 60 Reducer<Text, IntWritable, Text, IntWritable> { 61 private IntWritable result = new IntWritable(); 62 63 public void reduce(Text key, Iterable<IntWritable> values, 64 Context context) throws IOException, InterruptedException { 65 int sum = 0; 66 for (IntWritable val : values) { 67 sum += val.get(); 68 } 69 result.set(sum); 70 context.write(key, result); 71 } 72 } 73 74 public static void main(String[] args) throws Exception { 75 Configuration conf = new Configuration(); 76 conf.set("smallTableLocation", args[1]); 77 Job job = Job.getInstance(conf, "BigAndSmallTable"); 78 job.setJarByClass(BigAndSmallTable.class); 79 job.setMapperClass(TokenizerMapper.class); 80 job.setReducerClass(IntSumReducer.class); 81 job.setMapOutputKeyClass(Text.class); 82 job.setMapOutputValueClass(IntWritable.class); 83 job.setOutputKeyClass(Text.class); 84 job.setOutputValueClass(IntWritable.class); 85 FileInputFormat.addInputPath(job, new Path(args[0])); 86 FileOutputFormat.setOutputPath(job, new Path(args[2])); 87 System.exit(job.waitForCompletion(true) ? 0 : 1); 88 } 89 }
4’ 打包上传并执行
首先,使用“Xmanager Enterprise 5”将“C:\Users\allen\ Desktop\BigSmallTable.jar”上传至client机。此处上传至“/root/BigSmallTable.jar”
接着,登录client机上,使用下述命令提交BigSmallTable.jar任务。
/usr/cstor/hadoop/bin/hadoop jar /root/BigSmallTable.jar cn.cstor.mr.BigAndSmallTable /user/root/mr/in/big.txt /user/root/mr/in/small.txt /user/root/mr/bigAndSmallResult


1 [root@client ~]# /usr/cstor/hadoop/bin/hadoop jar /root/BigSmallTable.jar /user/root/mr/in/big.txt /user/root/mr/in/small.txt /user/root/mr/bigAndSmallResult 2 17/08/05 04:55:51 INFO client.RMProxy: Connecting to ResourceManager at master/10.1.21.27:8032 3 17/08/05 04:55:52 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 4 17/08/05 04:55:52 INFO input.FileInputFormat: Total input paths to process : 1 5 17/08/05 04:55:52 INFO mapreduce.JobSubmitter: number of splits:1 6 17/08/05 04:55:52 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1501872322130_0010 7 17/08/05 04:55:53 INFO impl.YarnClientImpl: Submitted application application_1501872322130_0010 8 17/08/05 04:55:53 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1501872322130_0010/ 9 17/08/05 04:55:53 INFO mapreduce.Job: Running job: job_1501872322130_0010 10 17/08/05 04:55:58 INFO mapreduce.Job: Job job_1501872322130_0010 running in uber mode : false 11 17/08/05 04:55:58 INFO mapreduce.Job: map 0% reduce 0% 12 17/08/05 04:56:03 INFO mapreduce.Job: map 100% reduce 0% 13 17/08/05 04:56:08 INFO mapreduce.Job: map 100% reduce 100% 14 17/08/05 04:56:09 INFO mapreduce.Job: Job job_1501872322130_0010 completed successfully 15 17/08/05 04:56:09 INFO mapreduce.Job: Counters: 49 16 File System Counters 17 FILE: Number of bytes read=36 18 FILE: Number of bytes written=231153 19 FILE: Number of read operations=0 20 FILE: Number of large read operations=0 21 FILE: Number of write operations=0 22 HDFS: Number of bytes read=265 23 HDFS: Number of bytes written=18 24 HDFS: Number of read operations=7 25 HDFS: Number of large read operations=0 26 HDFS: Number of write operations=2 27 Job Counters 28 Launched map tasks=1 29 Launched reduce tasks=1 30 Data-local map tasks=1 31 Total time spent by all maps in occupied slots (ms)=2597 32 Total time spent by all reduces in occupied slots (ms)=2755 33 Total time spent by all map tasks (ms)=2597 34 Total time spent by all reduce tasks (ms)=2755 35 Total vcore-seconds taken by all map tasks=2597 36 Total vcore-seconds taken by all reduce tasks=2755 37 Total megabyte-seconds taken by all map tasks=2659328 38 Total megabyte-seconds taken by all reduce tasks=2821120 39 Map-Reduce Framework 40 Map input records=5 41 Map output records=3 42 Map output bytes=24 43 Map output materialized bytes=36 44 Input split bytes=107 45 Combine input records=0 46 Combine output records=0 47 Reduce input groups=3 48 Reduce shuffle bytes=36 49 Reduce input records=3 50 Reduce output records=3 51 Spilled Records=6 52 Shuffled Maps =1 53 Failed Shuffles=0 54 Merged Map outputs=1 55 GC time elapsed (ms)=57 56 CPU time spent (ms)=1480 57 Physical memory (bytes) snapshot=425840640 58 Virtual memory (bytes) snapshot=1651806208 59 Total committed heap usage (bytes)=402653184 60 Shuffle Errors 61 BAD_ID=0 62 CONNECTION=0 63 IO_ERROR=0 64 WRONG_LENGTH=0 65 WRONG_MAP=0 66 WRONG_REDUCE=0 67 File Input Format Counters 68 Bytes Read=147 69 File Output Format Counters 70 Bytes Written=18 71 [root@client ~]#
>查看结果
程序执行后,可使用下述命令查看执行结果,注意若再次执行,请更改结果目录:
/usr/cstor/hadoop/bin/hdfs dfs -cat /user/root/mr/bigAndSmallResult/part-r-00000

总结:
从五个实验做出来之后,我们可以系统化的了解mapreduce的运行流程:
首先目标文件上传到HDFS;
其次编写目标程序代码;
然后将其打包上传到集群服务器上;
再然后执行该jar包;
生成part-r-00000结果文件。
关于hadoop的命令使用也更加熟练,对于一些文件上传、查看、编辑的处理也可以掌握于心了。学习到这里,对于大数据也算可以入门了,对于大数据也有了一定的了解与基本操作。
路漫漫其修远兮,吾将上下而求索。日积月累,坚持不懈是学习成果的前提。量变造成质变,望看到此处的朋友们共同努力,互相交流学习,我们都是爱学习的人!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号