大数据【一】集群配置及ssh免密认证
八月迷情,这个月会对大数据进行一个快速的了解学习。
一、所需工具简介
首先我是在大数据实验一体机上进行集群管理学习,管理五台实验机,分别为master,slave1,slave2,slave3,client。
此外,学习还涉及到以下工具的使用:
先来介绍下每个工具的作用之处:
1‘ google浏览器,JDK,eclipse,IDEA就不说明了(你们懂得);
2’ OPENVPN用来从操作的本机连接到服务器(下载注意操作系统的匹配),安装完成后,将下载的客户端配置压缩包解压,将其中的client.ovpn放于OpenVPN安装目录的config文件夹下。
以管理员身份运行OpenVPN GUI,任务栏将出现OpenVPN GUI图标,右键单击任务栏内OpenVPN GUI图标,点击「Connect」;
3‘ eclipse的插件是搭配后面的大数据组件(黄色小象)使用的,首先插件是放在eclipse的plugins文件夹内;其次大数据组件是下载解压后,使用其中的一个hadoop-2.7.1并解压到指定路径;
再然后,eclipse创建项目选择file>new>other>![]() ,然后
,然后 此处添加刚刚hadoop-2.7.1的解压路径,点击finish完成创建;
此处添加刚刚hadoop-2.7.1的解压路径,点击finish完成创建;
4’ XSHELL工具作用是输入ip连接到虚拟集群,并使用shell命令进行管理(前提完成2的连接);
5‘ WINSCP是可以在本机与集群管理的实验机上进行传输、管理文件、数据;

二、大数据的实验平台
大数据实验一体机(一个学习平台):
大数据实验一体机基本操作主要包括账号管理、集群管理、集群登录和辅助功能四大部分,其中账号管理完成新建和销毁用户账号,集群管理完成新建和销毁集群,集群登录指的是通过SSH登录到集群各机器,辅助功能模板提供了部分软件下载等实用小功能。
界面管理
输入本校大数据实验一体机网址后,请输入相应账号与密码,点击登录即可。如图1-1所示:
账号管理
系统管理员和教师角色登录后,可以看到用户账户管理界面。
其中:
系统管理员用户可以在该界面中查看或修改所有的教师和学生用户信息,并可以注册或销毁教师或学生用户账户;
教师用户可以在该界面中查看或修改自己建立的所有学生用户信息,并可以注册或销毁自己的学生用户账户。
集群管理
此处的集群管理包含“创建集群”和“销毁集群”,由于云创大数据实验一体机采用“Docker”技术,因此能够在几乎不占用系统资源情况下,实现大量机器快速创建与销毁,不必担心资源消耗高、启动销毁慢、管理维护难等问题。
(1)创建集群
当需要新建集群时,直接点击集群管理界面的创建集群即可,后台会快速为用户新建五台预安装CentOS 7操作系统的机器,并配置好各自的主机名和IP地址等。

(2)销毁集群
若实验过程中,由于命令敲错等各种原因导致集群无法使用,可在我的主页中随时销毁失效的集群,之后再重新建立新的集群
相关下载
大数据实验一体机的相关下载界面提供了实验所需的软件及插件的下载,为避免软件版本不同导致实验环境配置错误,请尽量下载和使用此处指定的软件版本与插件
三、预备知识
在进行大数据学习前,我还需要对linux有简单的操作能力,一些基本命令,以及编辑器vi或者vim的使用:
Linux基本命令
云创大数据实验平台搭建的集群服务器均为预装Linux操作系统的服务器。
Linux是一套免费使用和自由传播的类Unix操作系统,是一个基于POSIX和UNIX的多用户、多任务、支持多线程和多CPU的操作系统。它能运行主要的UNIX工具软件、应用程序和网络协议。它支持32位和64位硬件。Linux继承了Unix以网络为核心的设计思想,是一个性能稳定的多用户网络操作系统。
Linux操作系统诞生于1991年10月5日。Linux存在着许多不同的Linux版本,但它们都使用了Linux内核。Linux可安装在各种计算机硬件设备中,比如手机、平板电脑、路由器、视频游戏控制台、台式计算机、大型机和超级计算机。
严格来讲,Linux这个词本身只表示Linux内核,但实际上人们已经习惯了用Linux来形容整个基于Linux内核,并且使用GNU工程各种工具和数据库的操作系统。
本小节将介绍Linux操作系统命令:
(1)查看当前目录
pwd命令用于显示当前目录:
[root@master ~]# pwd
/root
(2)目录切换
cd命令用来切换目录:
[root@master ~]# cd /usr/cstor
[root@master cstor]# pwd
/usr/cstor
[root@master cstor]#
(3)文件罗列
ls命令用于查看文件与目录:
[root@master cstor]# ls
(4)文件或目录拷贝
cp命令用于拷贝文件,若拷贝的对象为目录,则需要使用-r参数:
[root@master cstor]# cp -r hadoop /root/hadoop
(5)文件或目录移动或重命名
mv命令用于移动文件,在实际使用中,也常用于重命名文件或目录:
[root@master ~]# mv hadoop hadoop2 #当前位于/root,不是/usr/cstor
(6)文件或目录删除
rm命令用于删除文件,若删除的对象为目录,则需要使用-r参数:
[root@master ~]# rm -rf hadoop2 #当前位于/root,不是/usr/cstor
(7)进程查看
ps命令用于查看系统的所有进程:
[root@master ~]# ps # 查看当前进程
(8)文件压缩与解压
tar命令用于文件压缩与解压,参数中的c表示压缩,x表示解压缩:
[root@master ~]# tar -zcvf /root/hadoop.tar.gz /usr/cstor/hadoop
[root@master ~]# tar -zxvf /root/hadoop.tar.gz
(9)查看文件内容
cat命令用于查看文件内容:
[root@master ~]# cat /usr/cstor/hadoop/etc/hadoop/core-site.xml
(10)查看服务器IP配置
ip addr命令用于查看服务器IP配置:
[root@master ~]# ip addr
Vi编辑器(当然,我习惯用vim)
vi编辑器通常被简称为vi,而vi又是visual editor的简称。它在Linux上的地位就像Edit程序在DOS上一样。它可以执行输出、删除、查找、替换、块操作等众多文本操作,而且用户可以根据自己的需要对其进行定制,这是其他编辑程序所没有的。
vi 编辑器并不是一个排版程序,它不像Word或WPS那样可以对字体、格式、段落等其他属性进行编排,它只是一个文本编辑程序。没有菜单,只有命令,且命令繁多。vi有3种基本工作模式:命令行模式、文本输入模式和末行模式。
Vim是vi的加强版,比vi更容易使用。vi的命令几乎全部都可以在vim上使用。
vi编辑器是Linux和Unix上最基本的文本编辑器,工作在字符模式下。由于不需要图形界面,vi是效率很高的文本编辑器。尽管在Linux上也有很多图形界面的编辑器可用,但vi在系统和服务器管理中的功能是那些图形编辑器所无法比拟的。
Vi或vim是实验中用到最多的文件编辑命令,命令行嵌入“vi/vim 文件名”后,默认进入“命令模式”,不可编辑文档,需键盘点击“i”键,方可编辑文档,编辑结束后,需按“ESC”键,先退回命令模式,再按“:”进入末行模式,接着嵌入“wq”方可保存退出。
Java基本命令
在安装Java环境后,可以使用Java命令来编译、运行或者打包Java程序。
(1)查看Java版本
[root@client ~]# java -version
(2)编译Java程序
[root@client ~]# javac Helloworld.java
(3)运行Java程序
[root@client ~]# java Helloworld
(4)打包Java程序
[root@client ~]# jar -cvf Helloworld.jar Helloworld.class
由于打包时并没有指定manifest文件,因此该jar包无法直接运行:
[root@client ~]# java -jar Helloworld.jar
(5)打包携带manifest文件的Java程序
manifest文件用于描述整个Java项目,最常用的功能是指定项目的入口类:
[root@client ~]# cat manifest.mf
打包时,加入-m参数,并指定manifest文件名:
[root@client ~]# jar -cvfm Helloworld.jar manifest.mf Helloworld.class
之后,即可使用java命令直接运行该jar包:
[root@client ~]# java -jar Helloworld.jar
四、SSH免密认证
在对集群进行管理时,最初需要对整个集群的所有子集进行免密认证,便于相互之间可以用 “ ssh master(子集名) ”进行相互免密切换。
Hadoop(简称HDFS,下一篇博客介绍)的基础是分布式文件系统HDFS,HDFS集群有两类节点以管理者-工作者的模式运行,即一个namenode(管理者)和多个datanode(工作者)。在Hadoop启动以后,namenode通过SSH来启动和停止各个节点上的各种守护进程,这就需要在这些节点之间执行指令时采用无需输入密码的认证方式,因此,我们需要将SSH配置成使用无需输入root密码的密钥文件认证方式。
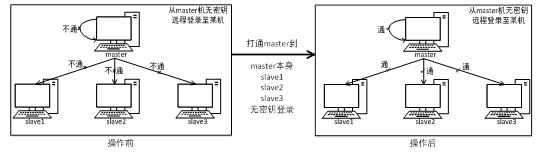
1’ 添加域名映射
系统搭建好的集群服务器已经完成修改主机名、关闭防火墙、安装JDK、同步时钟四步操作,为了可以安装大数据组件,还需为所有机器添加域名映射
使用ssh工具登录到master服务器,使用vi命令编辑/etc/hosts文件:
[root@master ~]# vi /etc/hosts #root权限,编辑master的域名映射文件
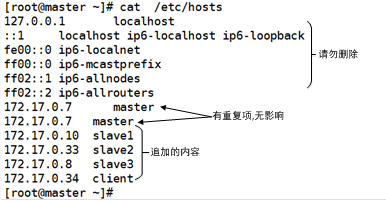
在文件的末尾追加写入如下五行(具体的IP地址请替换为实际集群服务器内部ip):
172.17.0.7 master
172.17.0.10 slave1
172.17.0.33 slave2
172.17.0.8 slave3
172.17.0.34 client
保存退出后,master服务器的域名映射即添加完成,使用cat命令查看/etc/hosts文件。
重复此操作在其他实验机上进行。
2‘ 生成master服务器密钥
执行命令ssh-keygen,生成master服务器密钥。
[root@master ~]# ssh-keygen #root用户,master机,生成公私钥
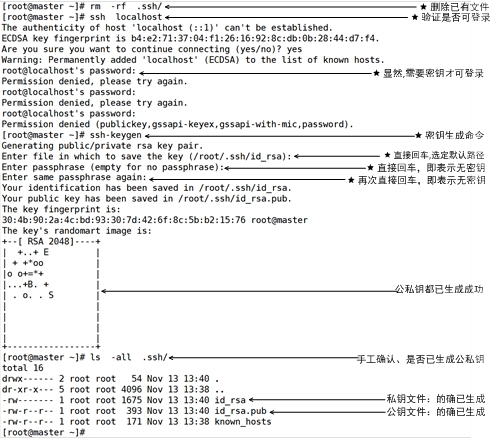
在master上执行“ssh-keygen”命令生成公私钥。第一个提示是询问将公私钥文件存放在哪,直接回车,选择默认位置。
第二个提示是请求用户输入密钥,既然操作的目的就是实现SSH无密钥登录,故此处必须使用空密钥,所谓的空密钥指的是直接回车,不是空格,更不是其他字符。此处请读者务必直接回车,使用空密钥。 第三个提示是要求用户确认刚才输入的密钥,既然刚才是空密钥(直接回车即空),那现在也应为空,直接回车即可。
最后,可通过命令“ls -all /root/.ssh”查看到,SSH密钥文件夹.ssh目录下的确生成了两个文件id_rsa和id_rsa_pub,这两个文件都有用,其中公钥用于加密,私钥用于解密。中间的rsa表示算法为RSA算法。
3' 拷贝master服务器公钥至本机
方法1:
执行命令ssh-copy-id master,将master服务器公钥拷贝至master服务器本身。
第一次连接master时,需要输入yes来确认建立授权的主机名访问,并需要输入root用户密码来完成公钥文件传输。
方法2:
对于linux和ssh文件熟悉的,我们一种修改文件方法。
当你秘钥生成后,可以在 cd ~/.ssh/ 目录下用命令查看 cat authorized_keys,显示内容应为所有集群子集的秘钥(字符串显示)。
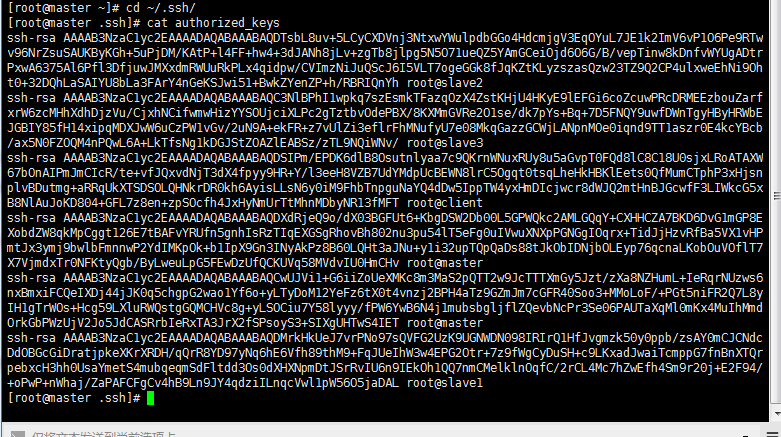
如果缺少其中的几个子集,切换时会提示输入密码,而不能完全的进行免密登陆其他子集。
当我用第一种方法对所有的子集ssh免密生成后就出现了这种情况,查看这个文件后就发现并没有写入。
所以我的方法就是先对master(抑或其他子集)ssh免密生成一次,查看文件然后拷贝文件,复制到其他子集上。
复制该文件的命令为 cp authorized_keys ~/.ssh/(目标目录)
注意点是所有的子集之间应该相互联系!
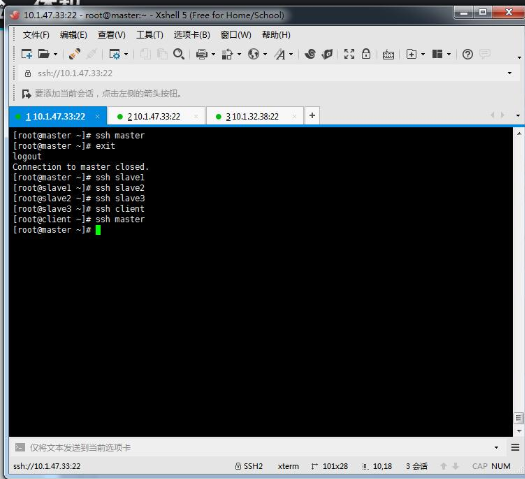
4' 验证master服务器ssh免密登录master本身
公钥拷贝完成后,可以在master服务器上直接执行命令ssh master,查看是否可以免密登录master服务器:
[root@master ~]# ssh master #root用户,登录本机网络地址
[root@master ~]# exit #退出本次登录
logout
Connection to master closed.
[root@master ~]#
5' 拷贝master服务器公钥至其余服务器
执行命令ssh-copy-id slave1(以及其他的所有)
第一次连接slave1时,需要输入yes来确认建立授权的主机名访问,并需要输入root用户密码来完成公钥文件传输。
依照同样的方式将公钥拷贝至slave2、slave3和client服务器。
6’ 验证master服务器ssh免密登录其余服务器
公钥拷贝完成后,可以在master服务器上直接执行命令ssh master,查看是否可以免密登录slave1~3和client服务器:
[root@master ~]# ssh localhost #root用户,登录本机环回地址
[root@master ~]# ssh master #root用户,登录本机网络地址
[root@master ~]# ssh slave1 #root用户,从master远程登录slave1
[root@master ~]# ssh slave2 #root用户,从master远程登录slave2
[root@master ~]# ssh slave3 #root用户,从master远程登录slave3
7‘ 到此,其余服务器按照同样的方式配置ssh免密登录,完成后验证是否可以互相之间实现SSH免密登录。