

深入理解Java虚拟机---栈,堆,方法区
ava程序运行时,数据会分区存放,JavaStack(Java栈)、 heap(堆)、method(方法区)。
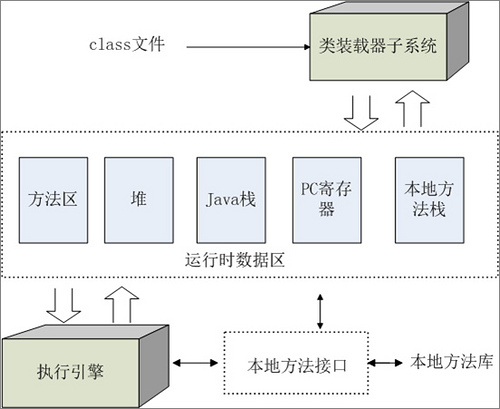
1、Java栈
Java栈的区域很小,只有1M,特点是存取速度很快,所以在stack中存放的都是快速执行的任务,基本数据类型的数据,和对象的引用(reference)。
驻留于常规RAM(随机访问存储器)区域。但可通过它的“栈指针”获取处理的直接支持。栈指针若向下移,会创建新的内存;若向上移,则会释放那些内存。这是一种特别快、特别有效的数据保存方式,仅次于寄存器。创建程序时,Java编译器必须准确地知道堆栈内保存的所有数据的“长度”以及“存在时间”。这是由于它必须生成相应的代码,以便向上和向下移动指针。这一限制无疑影响了程序的灵活性,所以尽管有些Java数据要保存在栈里——特别是对象句柄,但Java对象并不放到其中。
JVM只会直接对JavaStack(Java栈)执行两种操作:①以帧为单位的压栈或出栈;②通过-Xss来设置, 若不够会抛出StackOverflowError异常。
1.每个线程包含一个栈区,栈中只保存基本数据类型的数据和自定义对象的引用(不是对象),对象都存放在堆区中
2.每个栈中的数据(原始类型和对象引用)都是私有的,其他栈不能访问。
3.栈分为3个部分:基本数据类型的变量区、执行环境上下文、操作指令区(存放操作指令)。
栈是存放线程调用方法时存储局部变量表,操作,方法出口等与方法执行相关的信息,Java栈所占内存的大小由Xss来调节,方法调用层次太多会撑爆这个区域。
2、程序计数器(ProgramCounter)寄存器
PC寄存器( PC register ):每个线程启动的时候,都会创建一个PC(Program Counter,程序计数器)寄存器。PC寄存器里保存有当前正在执行的JVM指令的地址。 每一个线程都有它自己的PC寄存器,也是该线程启动时创建的。保存下一条将要执行的指令地址的寄存器是 :PC寄存器。PC寄存器的内容总是指向下一条将被执行指令的地址,这里的地址可以是一个本地指针,也可以是在方法区中相对应于该方法起始指令的偏移量。
3、本地方法栈
Nativemethodstack(本地方法栈):保存native方法进入区域的地址。
4、堆
类的对象放在heap(堆)中,所有的类对象都是通过new方法创建,创建后,在stack(栈)会创建类对象的引用(内存地址)。
一种常规用途的内存池(也在RAM(随机存取存储器 )区域),其中保存了Java对象。和栈不同:“内存堆”或“堆”最吸引人的地方在于编译器不必知道要从堆里分配多少存储空间,也不必知道存储的数据要在堆里停留多长的时间。因此,用堆保存数据时会得到更大的灵活性。要求创建一个对象时,只需用new命令编辑相应的代码即可。执行这些代码时,会在堆里自动进行数据的保存。当然,为达到这种灵活性,必然会付出一定的代价:在堆里分配存储空间时会花掉更长的时间。
JVM将所有对象的实例(即用new创建的对象)(对应于对象的引用(引用就是内存地址))的内存都分配在堆上,堆所占内存的大小由-Xmx指令和-Xms指令来调节,sample如下所示:
-
public class HeapOOM { -
static class OOMObject{} -
/** -
* @param args -
*/ -
public static void main(String[] args) { -
List list = new ArrayList();// List类和ArrayList类都是集合类, -
// 但是ArrayList可以理解为顺序表, -
// 属于线性表。 -
while (true) { -
list.add(new OOMObject()); -
} -
} -
}
加上JVM参数-verbose:gc -Xms10M -Xmx10M -XX:+PrintGCDetails -XX:SurvivorRatio=8 -XX:+HeapDumpOnOutOfMemoryError,就能很快报出OOM异常(内存溢出异常):
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
并且能自动生成Dump。
5、方法区
method(方法区)又叫静态区,存放所有的①类(class),②静态变量(static变量),③静态方法,④常量和⑤成员方法。
1.又叫静态区,跟堆一样,被所有的线程共享。
2.方法区中存放的都是在整个程序中永远唯一的元素。这也是方法区被所有的线程共享的原因。
(顺便展开静态变量和常量的区别: 静态变量本质是变量,是整个类所有对象共享的一个变量,其值一旦改变对这个类的所有对象都有影响;常量一旦赋值后不能修改其引用,其中基本数据类型的常量不能修改其值。)
Java里面是没有静态变量这个概念的,不信你自己在某个成员方法里面定义一个static int i = 0;Java里只有静态成员变量。它属于类的属性。至于他放哪里?楼上说的是静态区。我不知道到底有没有这个翻译。但是深入JVM里是翻译为方法区的。虚拟机的体系结构:①Java栈,② 堆,③PC寄存器,④方法区,⑤本地方法栈,⑥运行常量池。而方法区保存的就是一个类的模板,堆是放类的实例(即对象)的。栈是一般来用来函数计算的。随便找本计算机底层的书都知道了。栈里的数据,函数执行完就不会存储了。这就是为什么局部变量每一次都是一样的。就算给他加一后,下次执行函数的时候还是原来的样子。
方法区的大小由-XX:PermSize和-XX:MaxPermSize来调节,类太多有可能撑爆永久代。静态变量或常量也有可能撑爆方法区。
6、运行常量池
这儿的“静态”是指“位于固定位置”。程序运行期间,静态存储的数据将随时等候调用。可用static关键字指出一个对象的特定元素是静态的。但Java对象本身永远都不会置入静态存储空间。
这个区域属于方法区。该区域存放类和接口的常量,除此之外,它还存放成员变量和成员方法的所有引用。当一个成员变量或者成员方法被引用的时候,JVM就通过运行常量池中的这些引用来查找成员变量和成员方法在内存中的的实际地址。
7、举例分析
例子如下:
为了更清楚地搞明白程序运行时,数据区里的情况,我们来准备2个小道具(2个非常简单的小程序)。
-
// AppMain.java
-
public class AppMain { //运行时,JVM把AppMain的信息都放入方法区
-
-
public static void main(String[] args) { //main成员方法本身放入方法区。
-
Sample test1 = new Sample( " 测试1 " ); //test1是引用,所以放到栈区里,Sample是自定义对象应该放到堆里面
-
Sample test2 = new Sample( " 测试2 " );
-
test1.printName();
-
test2.printName();
-
}
-
-
}
-
-
// Sample.java
-
public class Sample { //运行时,JVM把appmain的信息都放入方法区。
-
-
private name; //new Sample实例后,name引用放入栈区里,name对象放入堆里。
-
-
public Sample(String name) {
-
this .name = name;
-
}
-
-
public void printName() {// printName()成员方法本身放入方法区里。
-
System.out.println(name);
-
}
-
-
}
OK,让我们开始行动吧,出发指令就是:“java AppMain”,包包里带好我们的行动向导图。
系统收到了我们发出的指令,启动了一个Java虚拟机进程,这个进程首先从classpath中找到AppMain.class文件,读取这个文件中的二进制数据,然后把Appmain类的类信息存放到运行时数据区的方法区中。这一过程称为AppMain类的加载过程。
接着,JVM定位到方法区中AppMain类的Main()方法的字节码,开始执行它的指令。这个main()方法的第一条语句就是:
Sample test1 = new Sample("测试1");
语句很简单啦,就是让JVM创建一个Sample实例,并且呢,使引用变量test1引用这个实例。貌似小case一桩哦,就让我们来跟踪一下JVM,看看它究竟是怎么来执行这个任务的:
1、Java虚拟机一看,不就是建立一个Sample类的实例吗,简单,于是就直奔方法区(方法区存放已经加载的类的相关信息,如类、静态变量和常量)而去,先找到Sample类的类型信息再说。结果呢,嘿嘿,没找到@@,这会儿的方法区里还没有Sample类呢(即Sample类的类信息还没有进入方法区中)。可JVM也不是一根筋的笨蛋,于是,它发扬“自己动手,丰衣足食”的作风,立马加载了Sample类, 把Sample类的相关信息存放在了方法区中。
2、Sample类的相关信息加载完成后。Java虚拟机做的第一件事情就是在堆中为一个新的Sample类的实例分配内存,这个Sample类的实例持有着指向方法区的Sample类的类型信息的引用(Java中引用就是内存地址)。这里所说的引用,实际上指的是Sample类的类型信息在方法区中的内存地址,其实,就是有点类似于C语言里的指针啦~~,而这个地址呢,就存放了在Sample类的实例的数据区中。
3、在JVM中的一个进程中,每个线程都会拥有一个方法调用栈,用来跟踪线程运行中一系列的方法调用过程,栈中的每一个元素被称为栈帧,每当线程调用一个方法的时候就会向方法栈中压入一个新栈帧。这里的帧用来存储方法的参数、局部变量和运算过程中的临时数据。OK,原理讲完了,就让我们来继续我们的跟踪行动!位于“=”前的test1是一个在main()方法中定义的变量,可见,它是一个局部变量,因此,test1这个局部变量会被JVM添加到执行main()方法的主线程的Java方法调用栈中。而“=”将把这个test1变量指向堆区中的Sample实例,也就是说,test1这个局部变量持有指向Sample类的实例的引用(即内存地址)。
OK,到这里为止呢,JVM就完成了这个简单语句的执行任务。参考我们的行动向导图,我们终于初步摸清了JVM的一点点底细了,COOL!
接下来,JVM将继续执行后续指令,在堆区里继续创建另一个Sample类的实例,然后依次执行它们的printName()方法。当JVM执行test1.printName()方法时,JVM根据局部变量test1持有的引用,定位到堆中的Sample类的实例,再根据Sample类的实例持有的引用,定位到方法区中Sample类的类型信息(包括①类,②静态变量,③静态方法,④常量和⑤成员方法),从而获取printName()成员方法的字节码,接着执行printName()成员方法包含的指令
Java存储机制
一、java的六种存储地址及解释
1) 寄存器(register):这是最快的存储区,因为它位于不同于其他存储区的地方——处理器内部。但是寄存器的数量极其有限,所以寄存器由编译器根据需求进行分配。你不能直接控制,也不能在程序中感觉到寄存器存在的任何迹象。
2) 堆栈(stack):位于通用RAM中,但通过它的“堆栈指针”可以从处理器哪里获得支持。堆栈指针若向下移动,则分配新的内存;若向上移动,则释放那些内存。这是一种快速有效的分配存储方法,仅次于寄存器。创建程序时候,JAVA编译器必须知道存储在堆栈内所有数据的确切大小和生命周期,因为它必须生成相应的代码,以便上下移动堆栈指针。这一约束限制了程序的灵活性,所以虽然某些JAVA数据存储在堆栈中——特别是对象引用,但是JAVA对象不存储其中。
3)堆(heap):一种通用性的内存池(也存在于RAM中),用于存放所有的JAVA对象。堆不同于堆栈的好处是:编译器不需要知道要从堆里分配多少存储区域,也不必知道存储的数据在堆里存活多长时间。因此,在堆里分配存储有很大的灵活性。当你需要创建一个对象的时候,只需要new写一行简单的代码,当执行这行代码时,会自动在堆里进行存储分配。当然,为这种灵活性必须要付出相应的代码。用堆进行存储分配比用堆栈进行存储存储需要更多的时间。
4)静态存储(static storage):这里的“静态”是指“在固定的位置”。静态存储里存放程序运行时一直存在的数据。你可用关键字static来标识一个对象的特定元素是静态的,但JAVA对象本身从来不会存放在静态存储空间里。
5) 常量存储(constant storage):常量值通常直接存放在程序代码内部,这样做是安全的,因为它们永远不会被改变。有时,在嵌入式系统中,常量本身会和其他部分分割离开,所以在这种情况下,可以选择将其放在ROM中。
6) 非RAM存储:如果数据完全存活于程序之外,那么它可以不受程序的任何控制,在程序没有运行时也可以存在。
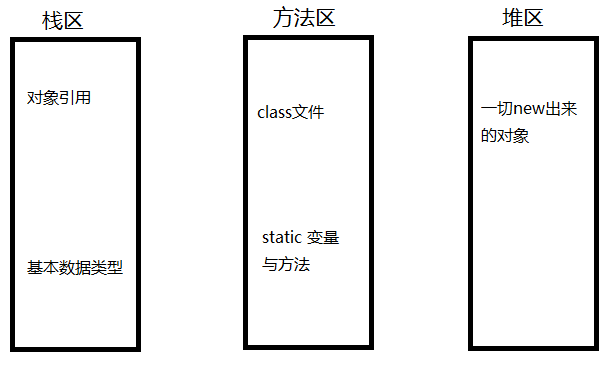
二、栈、堆、方法区存储的内容
堆区:
1.存储的全部是对象,每个对象都包含一个与之对应的class的信息。(class的目的是得到操作指令)
2.jvm只有一个堆区(heap)被所有线程共享,堆中不存放基本类型和对象引用,只存放对象本身 。
栈区:
1.每个线程包含一个栈区,栈中只保存基础数据类型的值和对象以及基础数据的引用
2.每个栈中的数据(基础数据类型和对象引用)都是私有的,其他栈不能访问。
3.栈分为3个部分:基本类型变量区、执行环境上下文、操作指令区(存放操作指令)。
方法区:
1.又叫静态区,跟堆一样,被所有的线程共享。方法区包含所有的class和static变量。
2.方法区中包含的都是在整个程序中永远唯一的元素,如class,static变量。
三、在Java语言里堆(heap)和栈(stack)里的区别
1. 栈(stack)与堆(heap)都是Java用来在Ram中存放数据的地方。与C++不同,Java自动管理栈和堆,程序员不能直接地设置栈或堆。
2. 栈的优势是,存取速度比堆要快,仅次于直接位于CPU中的寄存器。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。另外,栈数据可以共享,详见第3点。堆的优势是可以动态地分配内存大小,生存期也不必事先告诉编译器,Java的垃圾收集器会自动收走这些不再使用的数据。但缺点是,由于要在运行时动态分配内存,存取速度较慢。
3. Java中的数据类型有两种。
一种是基本类型(primitive types), 共有8种,即int, short, long, byte, float, double, boolean, char(注意,并没有string的基本类型)。这种类型的定义是通过诸如int a = 3; long b = 255L;的形式来定义的,称为自动变量。值得注意的是,自动变量存的是字面值,不是类的实例,即不是类的引用,这里并没有类的存在。如int a = 3; 这里的a是一个指向int类型的引用,指向3这个字面值。这些字面值的数据,由于大小可知,生存期可知(这些字面值固定定义在某个程序块里面,程序块退出后,字段值就消失了),出于追求速度的原因,就存在于栈中。
另外,栈有一个很重要的特殊性,就是存在栈中的数据可以共享。假设我们同时定义
int a = 3;
int b = 3;
编译器先处理int a = 3;首先它会在栈中创建一个变量为a的引用,然后查找有没有字面值为3的地址,没找到,就开辟一个存放3这个字面值的地址,然后将a指向3的地址。接着处理int b = 3;在创建完b的引用变量后,由于在栈中已经有3这个字面值,便将b直接指向3的地址。这样,就出现了a与b同时均指向3的情况。
特别注意的是,这种字面值的引用与类对象的引用不同。假定两个类对象的引用同时指向一个对象,如果一个对象引用变量修改了这个对象的内部状态,那么另一个对象引用变量也即刻反映出这个变化。相反,通过字面值的引用来修改其值,不会导致另一个指向此字面值的引用的值也跟着改变的情况。如上例,我们定义完a与 b的值后,再令a=4;那么,b不会等于4,还是等于3。在编译器内部,遇到a=4;时,它就会重新搜索栈中是否有4的字面值,如果没有,重新开辟地址存放4的值;如果已经有了,则直接将a指向这个地址。因此a值的改变不会影响到b的值。
另一种是包装类数据,如Integer, String, Double等将相应的基本数据类型包装起来的类。这些类数据全部存在于堆中,Java用new()语句来显示地告诉编译器,在运行时才根据需要动态创建,因此比较灵活,但缺点是要占用更多的时间。
4.每个JVM的线程都有自己的私有的栈空间,随线程创建而创建,java的stack存放的是frames ,java的stack和c的不同,只是存放本地变量,返回值和调用方法,不允许直接push和pop frames ,因为frames 可能是有heap分配的,所以j为ava的stack分配的内存不需要是连续的。java的heap是所有线程共享的,堆存放所有 runtime data ,里面是所有的对象实例和数组,heap是JVM启动时创建。
5. String是一个特殊的包装类数据。即可以用String str = new String("abc");的形式来创建,也可以用String str = "abc";的形式来创建(作为对比,在JDK 5.0之前,你从未见过Integer i = 3;的表达式,因为类与字面值是不能通用的,除了String。而在JDK 5.0中,这种表达式是可以的!因为编译器在后台进行Integer i = new Integer(3)的转换)。前者是规范的类的创建过程,即在Java中,一切都是对象,而对象是类的实例,全部通过new()的形式来创建。Java 中的有些类,如DateFormat类,可以通过该类的getInstance()方法来返回一个新创建的类,似乎违反了此原则。其实不然。该类运用了单例模式来返回类的实例,只不过这个实例是在该类内部通过new()来创建的,而getInstance()向外部隐藏了此细节。那为什么在String str = "abc";中,并没有通过new()来创建实例,是不是违反了上述原则?其实没有。
四、 关于String str = "abc"的内部工作。Java内部将此语句转化为以下几个步骤:
(1)先定义一个名为str的对String类的对象引用变量:String str;
(2)在栈中查找有没有存放值为"abc"的地址,如果没有,则开辟一个存放字面值为"abc"的地址,接着创建一个新的String类的对象o,并将o 的字符串值指向这个地址,而且在栈中这个地址旁边记下这个引用的对象o。如果已经有了值为"abc"的地址,则查找对象o,并返回o的地址。
(3)将str指向对象o的地址。
值得注意的是,一般String类中字符串值都是直接存值的。但像String str = "abc";这种场合下,其字符串值却是保存了一个指向存在栈中数据的引用!
为了更好地说明这个问题,我们可以通过以下的几个代码进行验证。
String str1 = "abc";
String str2 = "abc";
System.out.println(str1==str2); //true
注意,我们这里并不用str1.equals(str2);的方式,因为这将比较两个字符串的值是否相等。==号,根据JDK的说明,只有在两个引用都指向了同一个对象时才返回真值。而我们在这里要看的是,str1与str2是否都指向了同一个对象。
结果说明,JVM创建了两个引用str1和str2,但只创建了一个对象,而且两个引用都指向了这个对象。
我们再来更进一步,将以上代码改成:
String str1 = "abc";
String str2 = "abc";
str1 = "bcd";
System.out.println(str1 + "," + str2); //bcd, abc
System.out.println(str1==str2); //false
这就是说,赋值的变化导致了类对象引用的变化,str1指向了另外一个新对象!而str2仍旧指向原来的对象。上例中,当我们将str1的值改为"bcd"时,JVM发现在栈中没有存放该值的地址,便开辟了这个地址,并创建了一个新的对象,其字符串的值指向这个地址。
事实上,String类被设计成为不可改变(immutable)的类。如果你要改变其值,可以,但JVM在运行时根据新值悄悄创建了一个新对象,然后将这个对象的地址返回给原来类的引用。这个创建过程虽说是完全自动进行的,但它毕竟占用了更多的时间。在对时间要求比较敏感的环境中,会带有一定的不良影响。
再修改原来代码:
String str1 = "abc";
String str2 = "abc";
str1 = "bcd";
String str3 = str1;
System.out.println(str3); //bcd
String str4 = "bcd";
System.out.println(str1 == str4); //true
str3 这个对象的引用直接指向str1所指向的对象(注意,str3并没有创建新对象)。当str1改完其值后,再创建一个String的引用str4,并指向因str1修改值而创建的新的对象。可以发现,这回str4也没有创建新的对象,从而再次实现栈中数据的共享。
我们再接着看以下的代码。
String str1 = new String("abc");
String str2 = "abc";
System.out.println(str1==str2); //false
创建了两个引用。创建了两个对象。两个引用分别指向不同的两个对象。
String str1 = "abc";
String str2 = new String("abc");
System.out.println(str1==str2); //false
创建了两个引用。创建了两个对象。两个引用分别指向不同的两个对象。
以上两段代码说明,只要是用new()来新建对象的,都会在堆中创建,而且其字符串是单独存值的,即使与栈中的数据相同,也不会与栈中的数据共享。
(4) 数据类型包装类的值不可修改。不仅仅是String类的值不可修改,所有的数据类型包装类都不能更改其内部的值。
(5)结论与建议:
1)我们在使用诸如String str = "abc";的格式定义类时,总是想当然地认为,我们创建了String类的对象str。担心陷阱!对象可能并没有被创建!唯一可以肯定的是,指向 String类的引用被创建了。至于这个引用到底是否指向了一个新的对象,必须根据上下文来考虑,除非你通过new()方法来显要地创建一个新的对象。因此,更为准确的说法是,我们创建了一个指向String类的对象的引用变量str,这个对象引用变量指向了某个值为"abc"的String类。清醒地认识到这一点对排除程序中难以发现的bug是很有帮助的。
2)使用String str = "abc";的方式,可以在一定程度上提高程序的运行速度,因为JVM会自动根据栈中数据的实际情况来决定是否有必要创建新对象。而对于String str = new String("abc");的代码,则一概在堆中创建新对象,而不管其字符串值是否相等,是否有必要创建新对象,从而加重了程序的负担。这个思想应该是享元模式的思想,但JDK的内部在这里实现是否应用了这个模式,不得而知。
3)当比较包装类里面的数值是否相等时,用equals()方法;当测试两个包装类的引用是否指向同一个对象时,用==。
4)由于String类的immutable性质,当String变量需要经常变换其值时,应该考虑使用StringBuffer类,以提高程序效率。
如果java不能成功分配heap的空间,将抛出OutOfMemoryError

