Java实战(第2版)学习笔记
基本知识
函数式编程:Java 8 里将代码传递给方法的功能(同时也能够返回代码并将其包含在数据结构中)还让我们能够使用一整套新技巧,通常称为函数式编程。没有共享的可变数据,以及将方法和函数(即代码)传递给其他方法的能力,这两个要点是函数式编程范式的基石。
行为参数化:将方法(你的代码)作为参数传递给方法,或者说让方法接受多种行为(策略)作为参数,并在内部使用,来完成不同的行为。是处理频繁变更的需求的一种软件开发模式。在运行时传递方法(命名函数、Lambda、匿名函数)能将方法变成一等值。
流处理:Collection 主要是为了存储和访问数据,Stream 则主要用于描述对数据的计算。
接口默认方法:Java 8 引入了默认方法来支持接口的演进。
Optional 类:Java 8 提供了一个 Optional
Lambda 表达式:Lambda 表达式可以简洁地表示一个行为或者传递代码。Lambda 表达式可以看成匿名函数,和匿名类一样,它也能作为参数传递给一个方法。
Lambda 表达式有三个部分:
- 参数列表——这里它采用了 Comparator 中 compare 方法的参数,两个 Apple。
- 箭头——箭头->把参数列表与 Lambda 主体分隔开。
- Lambda 主体——比较两个 Apple 的重量。表达式就是 Lambda 的返回值。

Lambda 的基本语法:
-
表达式-风格
(parameters) -> expression -
块-风格
(parameters) -> { statements; }
在函数式接口上使用 Lambda 表达式。
函数式接口:函数式接口就是只定义一个抽象方法的接口。哪怕有很多默认方法,只要接口只定义了一个抽象方法,它就仍然是一个函数式接口。
函数式接口的抽象方法的签名(返回值)基本上就是 Lambda 表达式的签名。抽象方法叫做函数描述符。例如,Runnable 接口可以看作一个什么也不接受什么也不返回(void)的函数的签名,因为它只有一个叫作 run 的抽象方法
函数式接口带有@FunctionalInterface的标注,这个标注表示该接口会设计成一个函数式接口。
如果你用@FunctionalInterface定义了一个接口,而它不是函数式接口的话,编译器将返回一个提示原因的错误。
@FunctionalInterface不是必需的,但对于为此设计的接口而言,使用它是比较好的做法。
常见的函数式接口;Comparator、Runnable、Callable、Predicate、Consumer 和 Function
-
Comparator:接口有一个默认方法 reversed 可以使给定的比较器逆序。thenComparing 方法进一步比较。
-
Predicate:negate 方法来返回一个 Predicate 的非。and 和 or 方法是按照在表达式链中的位置,从左向右确定优先级的
-
Function:Function 接口配了 andThen 和 compose 两个默认方法,它们都会返回 Function 的一个实例
方法引用:使用::语法进行方法引用。方法引用主要有三类:
- 指向静态方法的方法引用(例如 Integer 的 parseInt 方法,写作 Integer::parseInt)
- 指向任意类型实例方法的方法引用(例如 String 的 length 方法,写作 String::length)
- 指向现存对象或表达式实例方法的方法引用(假设你有一个局部变量 expensive Transaction 保存了 Transaction 类型的对象,它提供了实例方法 getValue,那你就可以这么写 expensive-Transaction::getValue)
构造函数引用:现有构造函数,你可以利用它的名称和关键字 new 来创建它的一个引用:ClassName::new。
使用流进行函数式数据处理
流:从支持数据处理操作的源生成的元素序列。
- 元素序列:就像集合一样,流也提供了一个接口,可以访问特定元素类型的一组有序值。因为集合是数据结构,所以它的主要目的是以特定的时间/空间复杂度存储和访问元素(如
ArrayList与LinkedList)。但流的目的在于表达计算 - 源:流会使用一个提供数据的源,比如集合、数组或I/O资源。请注意,从有序集合生成流时会保留原有的顺序。由列表生成的流,其元素顺序与列表一致。
- 数据处理操作:数据处理操作——流的数据处理功能支持类似于数据库的操作,以及函数式编程语言中的常用操作,比如filter、map、reduce、find、match、sort等。流操作可以顺序执行,也可以并行执行。
流的特点:
- 流水线:很多流操作本身会返回一个流,这样多个操作就可以链接起来,构成一个更大的流水线。
- 内部迭代:与集合使用迭代器进行显式迭代不同,流的迭代操作是在后台进行的。
和迭代器类似,流只能遍历一次。
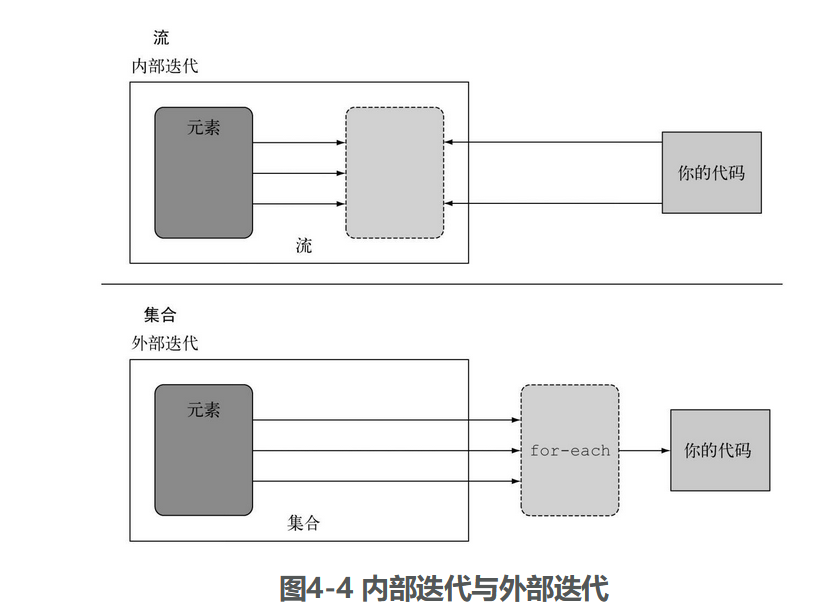
外部迭代和内部迭代:使用 Collection 接口需要用户去做迭代(比如用 for-each),这称为外部迭代。相反,Stream 库使用内部迭代,Streams 库的内部迭代可以自动选择一种适合你硬件的数据表示和并行实现。
外部迭代和内部迭代差异:
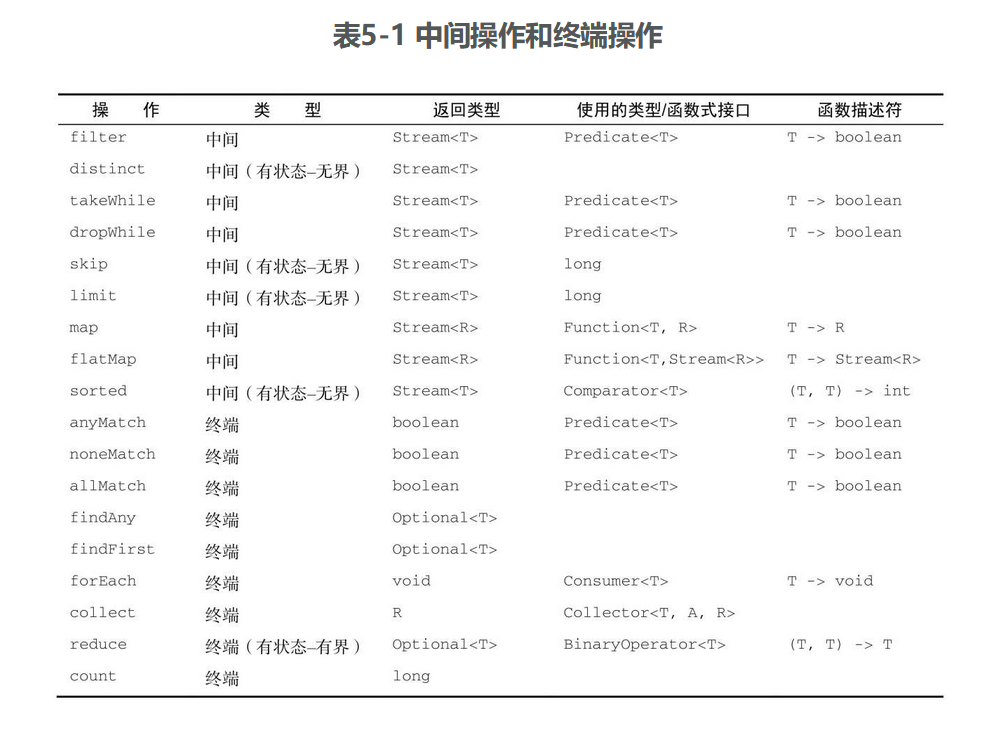
中间操作和终端操作
java.util.stream.Stream中的Stream接口定义了许多操作。它们可以分为两大类:中间操作和终端操作。
可以连接起来的流操作称为中间操作,关闭流的操作称为终端操作。
诸如filter或sorted等中间操作会返回另一个流。这让多个操作可以连接起来形成一个查询。重要的是,除非流水线上触发一个终端操作,否则中间操作不会执行任何处理。
终端操作会从流的流水线生成结果,其结果是任何不是流的值,比如List、Integer,甚至void。
这些操作能帮助你实现复杂的数据查询,如筛选、切片、映射、查找、匹配和归约。
特殊的流:数值流、由多个来源(譬如文件和数组)构成的流,以及无限流
筛选
谓词筛选:Stream接口支持filter方法。该操作会接受一个谓词(一个返回boolean的函数)作为参数,并返回一个包括所有符合谓词的元素的流。
List<Dish> vegetarianMenu = menu.stream()
.filter(Dish::isVegetarian)
.collect(toList());
筛选各异的元素:流还支持一个叫作distinct的方法,它会返回一个元素各异(根据流所生成元素的hashCode和equals方法实现)的流。
List<Integer> numbers = Arrays.asList(1, 2, 1, 3, 3, 2, 4);
numbers.stream()
.filter(i -> i % 2 == 0)
.distinct()
.forEach(System.out::println);
切片
使用谓词进行切片
Java 9引入takeWhile和dropWhile可以高效的选择流中的元素。
List<Dish> filteredMenu = specialMenu.stream()
.filter(dish -> dish.getCalories() < 320)
.collect(toList());
如果初始列表中的元素已经按照热量进行了排序操作,那么本该在发现第一个热量大于(或者等于)320卡里路的菜肴就停止处理。采用filter的话,你需要遍历整个流中的数据,对其中的每一个元素执行谓词操作。takeWhile可以帮助你利用谓词对流进行分片(即便你要处理的流是无限流也毫无困难)。更妙的是,它会在遭遇第一个不符合要求的元素时停止处理。
List<Dish> slicedMenu1 = specialMenu.stream()
.takeWhile(dish -> dish.getCalories() < 320)
.collect(toList());
dropWhile操作是对takeWhile操作的补充。它会从头开始,丢弃所有谓词结果为false的元素。一旦遭遇谓词计算的结果为true,它就停止处理,并返回所有剩余的元素,即便要处理的对象是一个由无限数量元素构成的流,它也能工作得很好。
List<Dish> slicedMenu2 = specialMenu.stream()
.dropWhile(dish -> dish.getCalories() < 320)
.collect(toList());
截短流
流支持limit(n)方法,该方法会返回另一个不超过给定长度的流。
List<Dish> dishesLimit3 = menu.stream()
.filter(d -> d.getCalories() > 300)
.limit(3)
.collect(toList());
请注意,limit也可以用在无序流上,比如源是一个Set。这种情况下,limit的结果不会以任何顺序排列。
跳过元素
流还支持skip(n)方法,返回一个扔掉了前n个元素的流。如果流中元素不足n个,则返回一个空流。limit(n)和skip(n)是互补的。
List<Dish> dishes = menu.stream()
.filter(d -> d.getCalories() > 300)
.skip(2)
.collect(toList());
映射
一个非常常见的数据处理套路就是从某些对象中选择信息。比如在SQL里,你可以从表中选择一列。Stream API也通过map和flatMap方法提供了类似的工具。
对流中每一个元素应用函数
流支持map方法,它会接受一个函数作为参数。这个函数会被应用到每个元素上,并将其映射成一个新的元素。
List<String> dishNames = menu.stream()
.map(Dish::getName)
.collect(toList());
因为getName方法返回一个String,所以map方法输出的流的类型就是Stream
map方法是中间操作,可以多次使用map方法
List<Integer> dishNameLengths = menu.stream()
.map(Dish::getName)
.map(String::length)
.collect(toList());
流的扁平化
使用flatMap方法的效果是,各个数组并不是分别映射成一个流,而是映射成流的内容。所有使用flatMap(Arrays::stream)时生成的单个流都被合并起来,即扁平化为一个流。
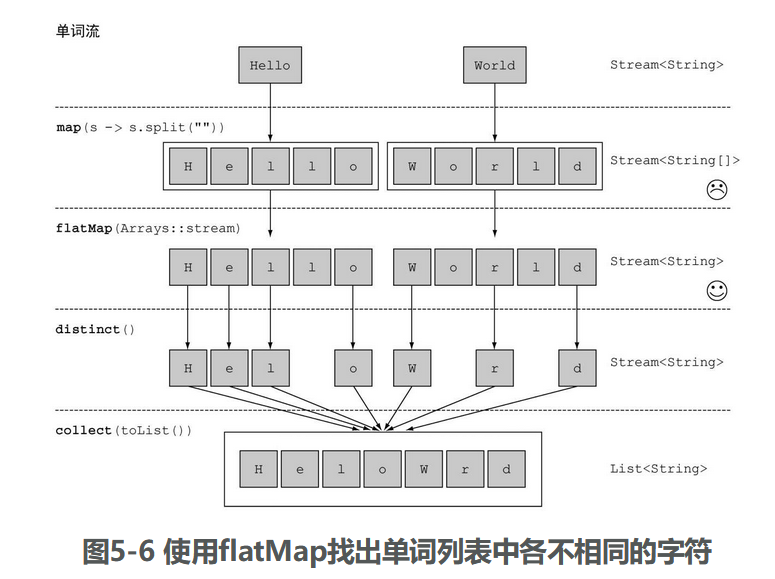
flatMap方法让你把一个流中的每个值都换成另一个流,然后把所有的流连接起来成为一个流。
查找和匹配
Stream API通过allMatch、anyMatch、noneMatch、findFirst和findAny方法提供了这样的工具。
检查谓词是否至少匹配一个元素
anyMatch方法可以回答“流中是否有一个元素能匹配给定的谓词”。
if(menu.stream().anyMatch(Dish::isVegetarian)){
System.out.println("The menu is (somewhat) vegetarian friendly! ! ");
}
anyMatch方法可以回答“流中是否有一个元素能匹配给定的谓词”。
anyMatch方法返回一个boolean,因此是一个终端操作。
检查谓词是否匹配所有元素
allMatch方法检查流中的元素是否都能匹配给定的谓词。
boolean isHealthy = menu.stream()
.allMatch(dish -> dish.getCalories() < 1000);
noneMatch方法确保流中没有任何元素与给定的谓词匹配。
boolean isHealthy = menu.stream()
.noneMatch(dish -> dish.getCalories() >= 1000);
查找元素
findAny方法将返回当前流中的任意元素。它可以与其他流操作结合使用。
Optional<Dish> dish =
menu.stream()
.filter(Dish::isVegetarian)
.findAny();
查找第一个元素
findFirst方法查找第一个元素。
如果你不关心返回的元素是哪个,请使用findAny,因为它在使用并行流时限制较少。
归约
元素求和
reduce方法将流中所有元素反复结合起来,得到一个值,比如一个Integer。这样的查询可以被归类为归约操作(将流归约成一个值)
int sum = numbers.stream().reduce(0, (a, b) -> a + b);
reduce接受两个参数:
- 一个初始值,这里是0;
- 一个
BinaryOperator<T>来将两个元素结合起来产生一个新值,这里用的是lambda (a, b)-> a + b。
reduce还有一个重载的变体,它不接受初始值,但是会返回一个Optional对象。
考虑流中没有任何元素的情况。reduce操作无法返回其和,因为它没有初始值。这就是为什么结果被包裹在一个Optional对象里,以表明和可能不存在。
最大值和最小值
计算最大值:
Optional<Integer> max = numbers.stream().reduce(Integer::max);
计算最小值:
Optional<Integer> min = numbers.stream().reduce(Integer::min);
数值流
int calories = menu.stream()
.map(Dish::getCalories)
.reduce(0, Integer::sum);
这段代码的问题是,它有一个暗含的装箱成本。每个Integer都必须拆箱成一个原始类型,再进行求和。
Stream API还提供了原始类型流特化,专门支持处理数值流的方法。
Java 8引入了三个原始类型特化流接口来解决这个问题:IntStream、DoubleStream和LongStream,分别将流中的元素特化为int、long和double,从而避免了暗含的装箱成本。
Optional 类
Optionaljava.util.Optional)是一个容器类,代表一个值存在或不存在。
isPresent()将在Optional包含值的时候返回true,否则返回false。
ifPresent(Consumer<T> block)会在值存在的时候执行给定的代码块
T get()会在值存在时返回值,否则抛出一个NoSuchElement异常。
T orElse(T other)会在值存在时返回值,否则返回一个默认值。


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 微软正式发布.NET 10 Preview 1:开启下一代开发框架新篇章
· 没有源码,如何修改代码逻辑?
· PowerShell开发游戏 · 打蜜蜂
· 在鹅厂做java开发是什么体验
· WPF到Web的无缝过渡:英雄联盟客户端的OpenSilver迁移实战