集合
集合框架
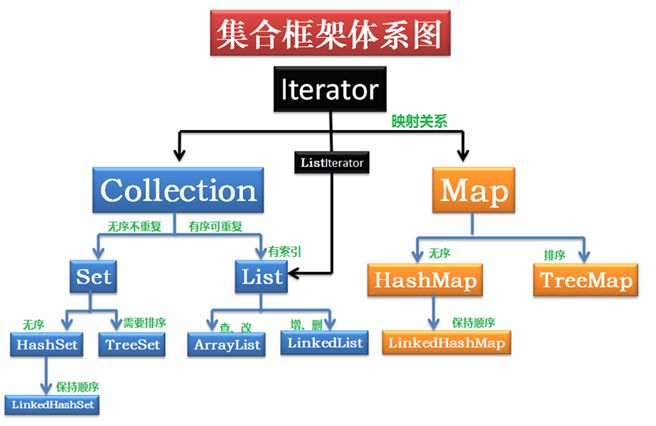
什么是集合:
集合是Java提供的一种容器,用于存放引用类型的数据。
集合和数组的区别;
数组是一种长度不可变的容器,用于存放基本数据类型和引用数据类型。
集合是一种长度可变的容器,它的实现类多种多样,然后列举图中的实现类的特点 ;只能存放引用数据类型,如果想要存放基本数据类型,必须转化成其对应的包装类才能存放。
怎么学习集合 ,要从上往下学习
先学习Collection中的方法
boolean add(E e) 添加元素
boolean remove(Object o) 删除元素
void clear() 清空元素,删除所有
boolean contains(Object o) 是否包含某个元素
boolean isEmpty()
int size()
1 import java.util.ArrayList; 2 import java.util.Collection; 3 4 public class MyCollection_Test { 5 6 public static void main(String[] args) { 7 // 多态,调用的是父类自己的方法,但是父类是接口,调用的是实现类类实现了的方法,但是不能调用实现类特有的 8 Collection<Student> lists = new ArrayList<>(); 9 lists.add(new Student("张三")); 10 lists.add(new Student("李四")); 11 lists.add(new Student("王五")); 12 // 这样是移除不了的,除非重写equals方法,因为重新new了一个对象,地址是不同的;或者在存放是用一个学生变量接收,这样在删除时就好操作了 13 System.out.println(lists.remove(new Student("张三"))); //执行结果是false 14 } 15 } 16 17 class Student { 18 private String name; 19 20 public Student(String name) { 21 super(); 22 this.name = name; 23 } 24 25 }
Java集合框架的集合类,我们有时候称之为容器。容器的种类有很多种,比如ArrayList、LinkedList、HashSet...,每种容器都有自己的特点,ArrayList底层维护的是一个数组;LinkedList是链表结构的;HashSet依赖的是哈希表,每种容器都有自己特有的数据结构。
因为容器的内部结构不同,很多时候可能不知道该怎样去遍历一个容器中的元素。所以为了使对容器内元素的操作更为简单,Java引入了迭代器模式!
把访问逻辑从不同类型的集合类中抽取出来,从而避免向外部暴露集合的内部结构。
1.迭代器Iterator接口的实现方式
在JDK中它是这样定义的:对Collection进行迭代的迭代器。迭代器取代了Java Collection Framework中的Enumeration。迭代器与枚举有两点不同:
1. 迭代器在迭代期间可以从集合中移除元素。
2. 方法名得到了改进,Enumeration的方法名称都比较长。
其接口定义如下:
1 package java.util; 2 public interface Iterator<E> { 3 boolean hasNext();//判断是否存在下一个对象元素 4 5 E next();//获取下一个元素 6 7 void remove();//移除元素 8 }
2.Iterable
Java中还提供了一个Iterable接口,Iterable接口实现后的功能是‘返回’一个迭代器,我们常用的实现了该接口的子接口有:Collection<E>、List<E>、Set<E>等。该接口的iterator()方法返回一个标准的Iterator实现。实现Iterable接口允许对象成为For…each语句的目标。就可以通过for…each语句来遍历你的底层序列。
Iterable接口包含一个能产生Iterator对象的方法,并且Iterable被for…each用来在序列中移动。因此如果创建了实现Iterable接口的类,都可以将它用于for…each中。
Iterable接口的具体实现:
Package java.lang;
import java.util.Iterator;
public interface Iterable<T> {
Iterator<T> iterator();
}
遍历方法:
第一种:(基本原理)
第一步:实现迭代器
1 Iterator it= lists.iterator();
第二步:使用while循环 while(it.hasNext()){ sysout( it.next()); }
第二种:(实质还是第一种)
不用实现迭代器,直接使用for…each输出
再学习它的子类List接口
list有类似于数组的操作
ArrayList---底层是数组
LinkedList---底层是链表
Vector--- 底层是数组(现在不怎么被使用,作为了解)
void add(int index,E element) 添加元素到指定的下标位置
E remove(int index) 删除指定下标位置的元素(注意这个和父类的移除不一样,这里可以返回自己移除的元素,有一个后悔的机会)
E get(int index) 获取指定下标位置的元素
E set(int index,E element) 修改指定下标位置的元素
ListIterator listIterator() Iterator的增强版 (增强版的迭代器,可以倒序遍历,但是迭代器的指针必须是在最后一个的位置上,否则不可以使用倒序输出,调用方法是 对象名.下面两个方法 )
boolean hasPrevious()
E previous()
ArrayList:
底层就是数组:查询快,增删慢
线程不安全,效率高
Vector:
底层就是数组:查询快,增删慢
线程安全,效率低
确实需要使用线程安全的ArrayList,也不建议使用,一般使用Collections类的方法
LinkedList
底层数据结构是链表,查询慢,增删快
线程不安全,效率高
面试常考题:
List的选择:
首先看这两类都实现List接口,而List接口一共有三个实现类,分别是ArrayList、Vector和LinkedList。List用于存放多个元素,能够维护元素的次序,并且允许元素的重复。3个具体实现类的相关区别如下:
- ArrayList是最常用的List实现类,内部是通过数组实现的,它允许对元素进行快速随机访问。数组的缺点是每个元素之间不能有间隔,当数组大小不满足时需要增加存储能力,就要讲已经有数组的数据复制到新的存储空间中。当从ArrayList的中间位置插入或者删除元素时,需要对数组进行复制、移动、代价比较高。因此,它适合随机查找和遍历,不适合插入和删除。
- Vector与ArrayList一样,也是通过数组实现的,不同的是它支持线程的同步,即某一时刻只有一个线程能够写Vector,避免多线程同时写而引起的不一致性,但实现同步需要很高的花费,因此,访问它比访问ArrayList慢。
- LinkedList是用链表结构存储数据的,很适合数据的动态插入和删除,随机访问和遍历速度比较慢。另外,他还提供了List接口中没有定义的方法,专门用于操作表头和表尾元素,可以当作堆栈、队列和双向队列使用。
- vector是线程(Thread)同步(Synchronized)的,所以它也是线程安全的,而Arraylist是线程异步(ASynchronized)的,是不安全的。如果不考虑到线程的安全因素,一般用Arraylist效率比较高。
-
如果集合中的元素的数目大于目前集合数组的长度时,vector增长率为目前数组长度的100%,而arraylist增长率为目前数组长度
的50%.如过在集合中使用数据量比较大的数据,用vector有一定的优势。 -
如果查找一个指定位置的数据,vector和arraylist使用的时间是相同的,都是0(1),这个时候使用vector和arraylist都可以。而
如果移动一个指定位置的数据花费的时间为0(n-i)n为总长度,这个时候就应该考虑到使用Linkedlist,因为它移动一个指定位置的数据
所花费的时间为0(1),而查询一个指定位置的数据时花费的时间为0(i)。
ArrayList 和Vector是采用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,
都允许直接序号索引元素,但是插入数据要设计到数组元素移动 等内存操作,所以索引数据快插入数据慢,
Vector由于使用了synchronized方法(线程安全)所以性能上比ArrayList要差
,LinkedList使用双向链表实现存储,按序号索引数据需要进行向前或向后遍历,但是插入数据时只需要记录本项的前后项即可,所以插入数度较快! -
笼统来说:LinkedList:增删改快
ArrayList:查询快(有索引的存在)
再学习Collection接口的另一个子接口Set
Set接口的实现类
hashSet的特点:无序且元素不重复,无序指的是添加的顺序和内存中存储的顺序是不一样的,元素不重复指的是元素在栈内存中的地址不重复,在调用add()方法时,内部调用了没有重写的hashCode和equals方法,所以如果是引用类型,就要重写这两个方法。
hashSet底层的add()方法是调用了Map接口的put(K key,V vaule)方法,key就是HashSet类型的元素,
public boolean add(E e) { return map.put(e, PRESENT)==null; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号