

一致性哈希
一致性哈希算法在1997年由麻省理工学院的Karger等人在解决分布式缓存中提出的,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似。一致性哈希修正了CARP使用的简单哈希算法带来的问题,使得DHT可以在P2P环境中真正得到应用。
首先,对存储节点的哈希值进行计算,其将存储空间抽象为一个环,将存储节点配置到环上。环上所有的节点都有一个值。其次,对数据进行哈希计算,按顺时针方向将其映射到离其最近的节点上去。当有节点出现故障离线时,按照算法的映射方法,受影响的仅仅为环上故障节点开始逆时针方向至下一个节点之间区间的数据对象,而这些对象本身就是映射到故障节点之上的。当有节点增加时,比如,在节点A和B之间重新添加一个节点H,受影响的也仅仅是节点H逆时针遍历直到B之间的数据对象,将这些重新映射到H上即可,因此,当有节点出现变动时,不会使得整个存储空间上的数据都进行重新映射,
解决了简单哈希算法增删节点,重新映射所有数据带来的效率低下的问题。
具体在计算一致性hash时采用如下步骤:
- 首先求出服务器(节点)的哈希值,并将其配置到0~232的圆(continuum)上。
- 然后采用同样的方法求出存储数据的键的哈希值,并映射到相同的圆上。
- 然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过232仍然找不到服务器,就会保存到第一台服务器上。

余数分布式算法由于保存键的服务器会发生巨大变化而影响缓存的命中率,但Consistent Hashing中,只有在圆环(continuum)上增加服务器的地点逆时针方向的第一台服务器上的键会受到影响,如下图所示:
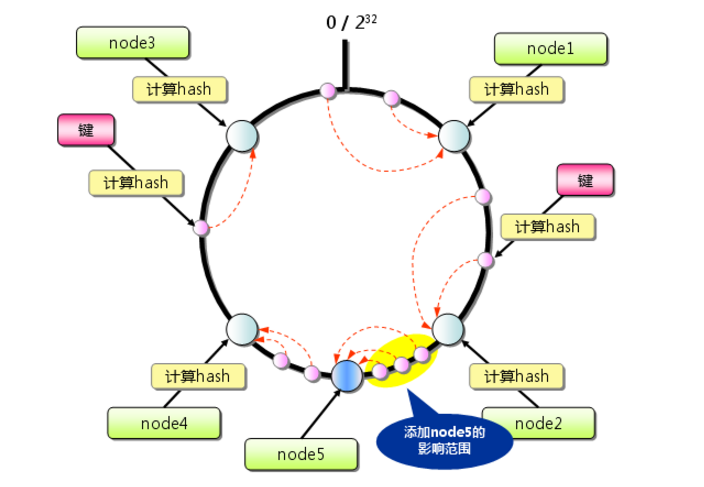
一致性Hash算法的容错性和可扩展性
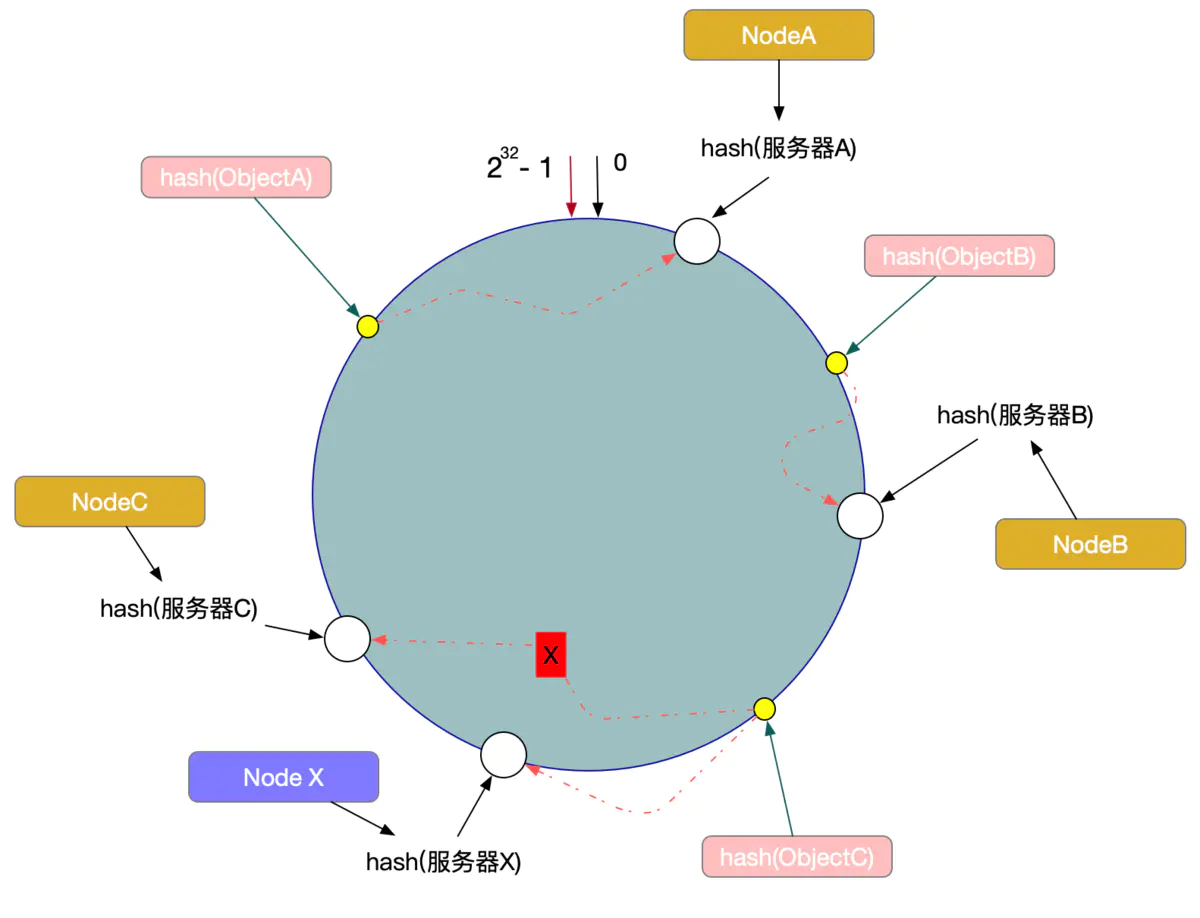
另外一种情况,现在我们系统增加了一台服务器Node X,如图
此时对象ObjectA、ObjectB没有受到影响,只有Object C重新定位到了新的节点X上。
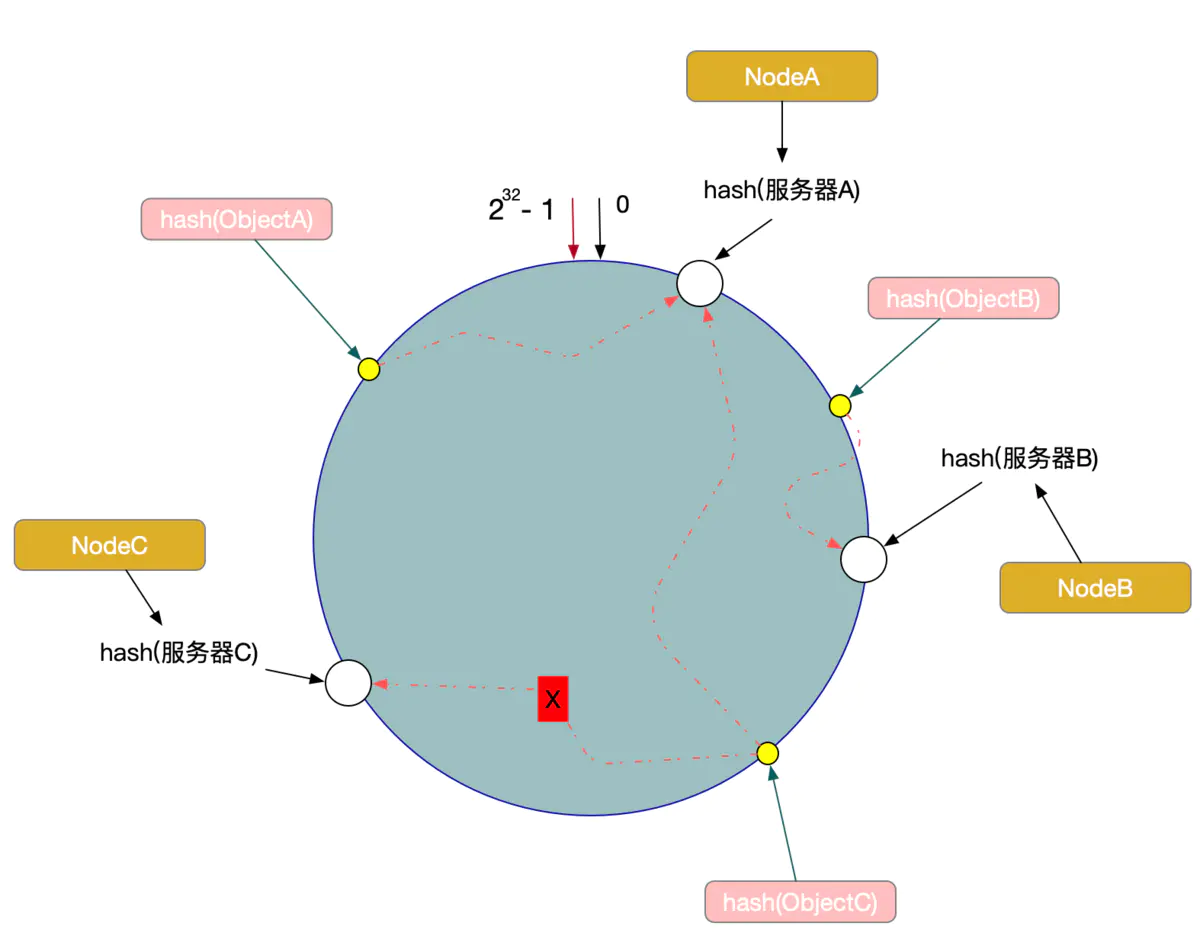
数据倾斜问题
在一致性Hash算法服务节点太少的情况下,容易因为节点分布不均匀面造成数据倾斜(被缓存的对象大部分缓存在某一台服务器上)问题,如图
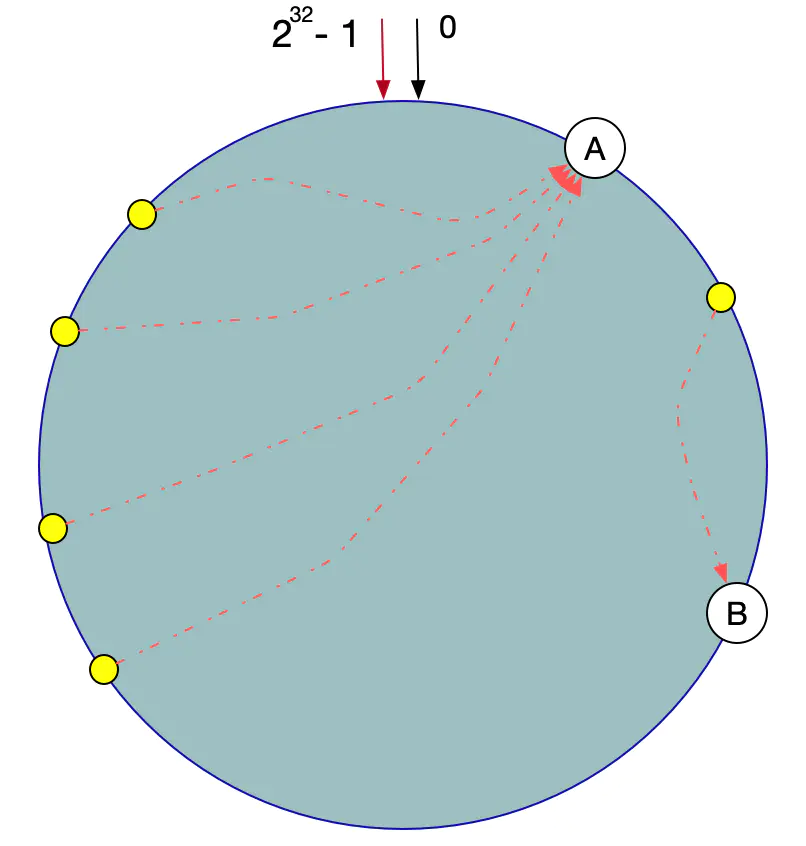
虚拟节点机制,即对每一个服务器节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体操作可以为服务器IP或主机名后加入编号来实现,实现如图

数据定位算法不变,只需要增加一步:虚拟节点到实际点的映射。
所以加入虚拟节点之后,即使在服务节点很少的情况下,也能做到数据的均匀分布。
参考文章:
https://www.jianshu.com/p/528ce5cd7e8f
https://www.cnblogs.com/lpfuture/p/5796398.html



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!