

Linux下MySQL的操作(最全)
注意:这里以mariadb为例
启动mysql服务
systemctl start mariadb
登录mysql
mysql -u root -p
SQL语言分类
- 数据定义语言:简称【DDL】(Data Definition Language),用来定义数据库对象:数据库,表,列等。 关键字:create,alter,drop等 - 数据操作语言:简称【DML】(Data Manipulation Language),用来对数据库中表的记录进行更新。关键 字:insert,delete,update等 - 数据控制语言:简称【DCL】(Data Control Language),用来定义数据库的访问权限和安全级别,及创建 用户;关键字:grant等 - 数据查询语言:简称【DQL】(Data Query Language),用来查询数据库中表的记录。关键字:select, from,where等
如果要了解标准的内容,比较推荐的方法是【泛读SQL92】(因为它涉及了SQL最基础和最核心的一些内容),然
后增量式的阅读其他标准。
DDL语句
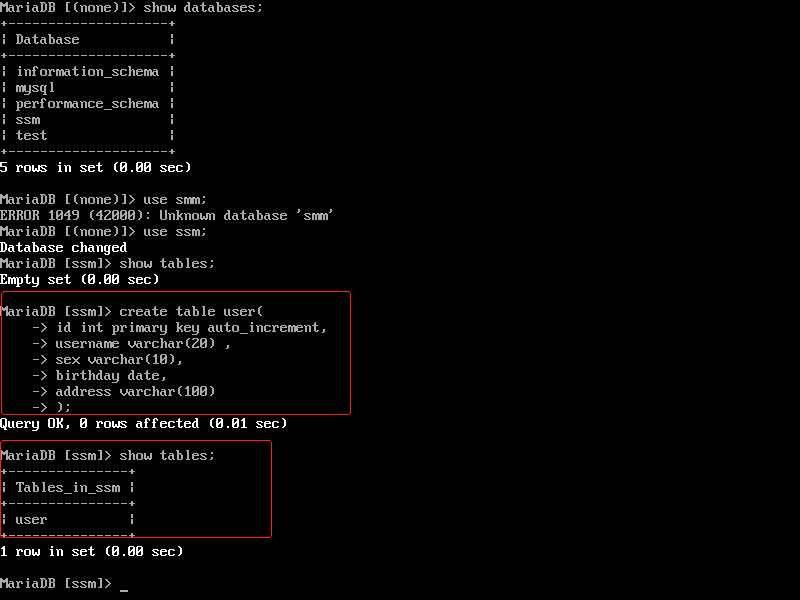
数据库操作:database
创建数据库
create database 数据库名; create database 数据库名 character set 字符集;
查看数据库
查看数据库服务器中的所有的数据库:
show databases;
查看某个数据库的定义的信息:
show create database 数据库名;
删除数据库(慎用)
drop database 数据库名称;
其他数据库操作命令
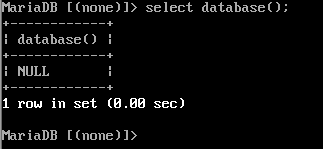
切换数据库:
use 数据库名;
查看正在使用的数据库:
select database();
表操作:table
创建表
create table 表名( 字段名 类型(长度) 约束, 字段名 类型(长度) 约束 );
比如创建一个用户表
单表约束:
主键约束:primary key - 唯一约束:unique - 非空约束:not null
主键约束 = 唯一约束 + 非空约束
查看表
查看数据库中的所有表:
show tables;
查看表结构:
desc 表名;
删除表
drop table 表名;
修改表
alter table 表名 add 列名 类型(长度) 约束; --修改表添加列. alter table 表名 modify 列名 类型(长度) 约束; --修改表修改列的类型长度及约束. alter table 表名 change 旧列名 新列名 类型(长度) 约束; --修改表修改列名. alter table 表名 drop 列名; --修改表删除列. rename table 表名 to 新表名; --修改表名 alter table 表名 character set 字符集; --修改表的字符集
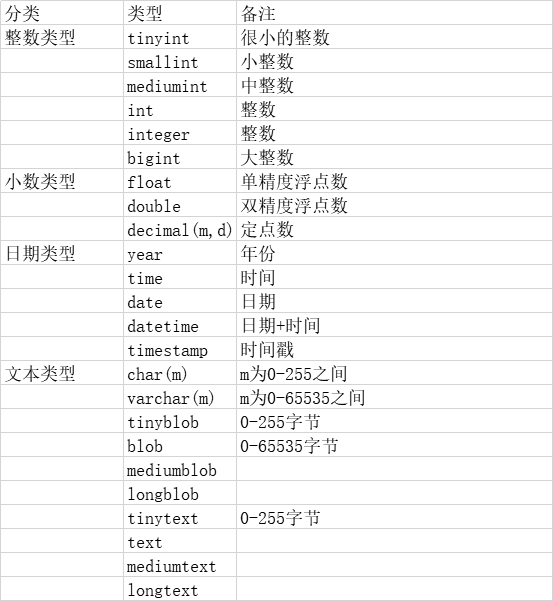
字段类型
常用的类型有:
DML语句
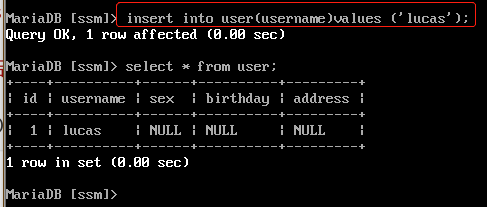
插入记录:insert
insert into 表 (列名1,列名2,列名3..) values (值1,值2,值3..); -- 向表中插入某些列 insert into 表 values (值1,值2,值3..); --向表中插入所有列 insert into 表 (列名1,列名2,列名3..) values select (列名1,列名2,列名3..) from 表 insert into 表 values select * from 表
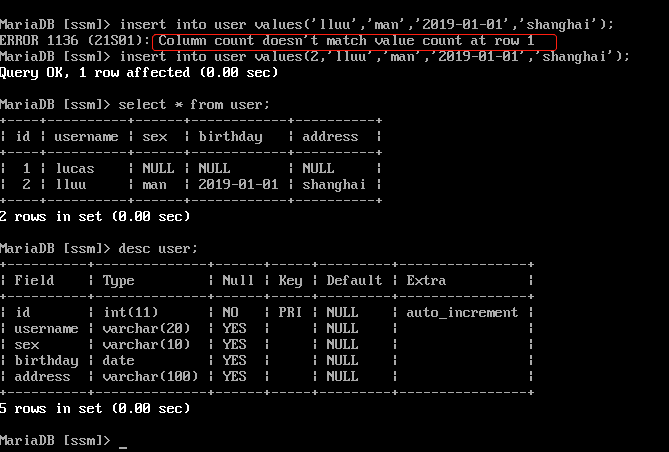
注意: 1. 列名数与values后面的值的个数相等 2. 列的顺序与插入的值得顺序一致 3. 列名的类型与插入的值要一致. 4. 插入值得时候不能超过最大长度. 5. 值如果是字符串或者日期需要加引号’’ ,一般是单引号
注意插入的时候如果没有申明列,那么需要插入每一列,不然会报错:column count doesn`t match value count at row xx.
更新记录:update
update 表名 set 字段名=值,字段名=值; update 表名 set 字段名=值,字段名=值 where 条件;
注意:
1. 列名的类型与修改的值要一致.
2. 修改值得时候不能超过最大长度.
3. 值如果是字符串或者日期需要加’’
删除记录:delete
delete from 表名 [where 条件];
删除表中所有记录使用【delete from 表名】,还是用【truncate table 表名】?
删除方式: - delete :一条一条删除,不清空auto_increment记录数。 - truncate :直接将表删除,重新建表,auto_increment将置为零,从新开始。
DQL语句
DQL语法顺序
完整DQL语法顺序
SELECT DISTINCT < select_list > FROM < left_table > < join_type > JOIN < right_table > ON < join_condition > WHERE < where_condition > GROUP BY < group_by_list > HAVING < having_condition > ORDER BY < order_by_condition > LIMIT < limit_number >
简单查询
查询所有的商品
select * from product;
* 表示表的所有字段,也可以指定具体字段,甚至可以给字段取别名
select pname ,price from product;
别名查询,使用的as关键字,as可以省略的
select * from product as p;
去掉重复值
select distinct price from product;
运算查询
select pname,price+10 from product;
数据库的运算查询是很消耗时间的,不建议在数据库这样操作,应该将数据在后台程序进行操作,数据库只处理数据,不应该处理逻辑。
条件查询
查询商品价格>60元的所有的商品信息
select * from product where price > 60;
符号说明
> ,<,=,>=,<=,<> like 使用占位符 _ 和 % _代表一个字符 %代表任意个字符. select * from product where pname like '%新%'; in在某个范围中获得值(exists). select * from product where pid in (2,5,8);

排序
查询所有的商品,按价格进行排序.(asc-升序,desc-降序)
默认就是asc
select * from product order by price;
聚合函数(组函数)
特点:只对单列进行操作
常用的聚合函数
sum():求某一列的和 avg():求某一列的平均值 max():求某一列的最大值 min():求某一列的最小值 count():求某一列的元素个数
获得所有商品的价格的总和:
select sum(price) from product;
获得所有商品的个数
select count(*) from product;
分组
根据cid字段分组,分组后统计商品的个数
select cid,count(*) from product group by cid;
根据cid分组,分组统计每组商品的平均价格,并且平均价格> 60;
select cid,avg(price) from product group by cid having avg(price)>60;
注意事项
select语句中的列(非聚合函数列),必须出现在group by子句中 group by子句中的列,不一定要出现在select语句中 聚合函数只能出现select语句中或者having语句中,一定不能出现在where语句中。
分页查询
分页分为逻辑分页和物理分页
逻辑分页:将数据库中的数据查询到内存之后再进行分页。 物理分页:通过LIMIT关键字,直接在数据库中进行分页,最终返回的数据,只是分页后的数据。
lIMIT 关键字不是 SQL92 标准提出的关键字,它是 MySQL 独有的语法。
通过 limit 关键字, MySQL 实现了物理分页
SELECT * FROM table LIMIT [offset,] rows
子查询
子查询允许把一个查询嵌套在另一个查询当中。 子查询,又叫内部查询,相对于内部查询,包含内部查询的就称为外部查询。 子查询可以包含普通select可以包括的任何子句,比如:distinct、 group by、order by、limit、join和 union等; 但是对应的外部查询必须是以下语句之一:select、insert、update、delete
其他查询语句
union 集合的并集(不包含重复记录) unionall 集合的并集(包含重复记录
SQL解析顺序
SELECT DISTINCT < select_list > FROM < left_table > < join_type > JOIN < right_table > ON < join_condition > WHERE < where_condition > GROUP BY < group_by_list > HAVING < having_condition > ORDER BY < order_by_condition > LIMIT < limit_number >
然而它的执行顺序是这样的
1 FROM <left_table> 2 ON <join_condition> 3 <join_type> JOIN <right_table> 第二步和第三步会循环执行 4 WHERE <where_condition> 第四步会循环执行,多个条件的执行顺序是从左往右的。 5 GROUP BY <group_by_list> 6 HAVING <having_condition> 7 SELECT 分组之后才会执行SELECT 8 DISTINCT <select_list> 9 ORDER BY <order_by_condition> 10 LIMIT <limit_number> 前9步都是SQL92标准语法。limit是MySQL的独有语法。
关于sql解析还有很多,另开一个篇章专门介绍吧


