


大数据课程------scala部分
1.foldLeft,初始值是0,0+_._2,然后作为初始值_,再继续进行累加。
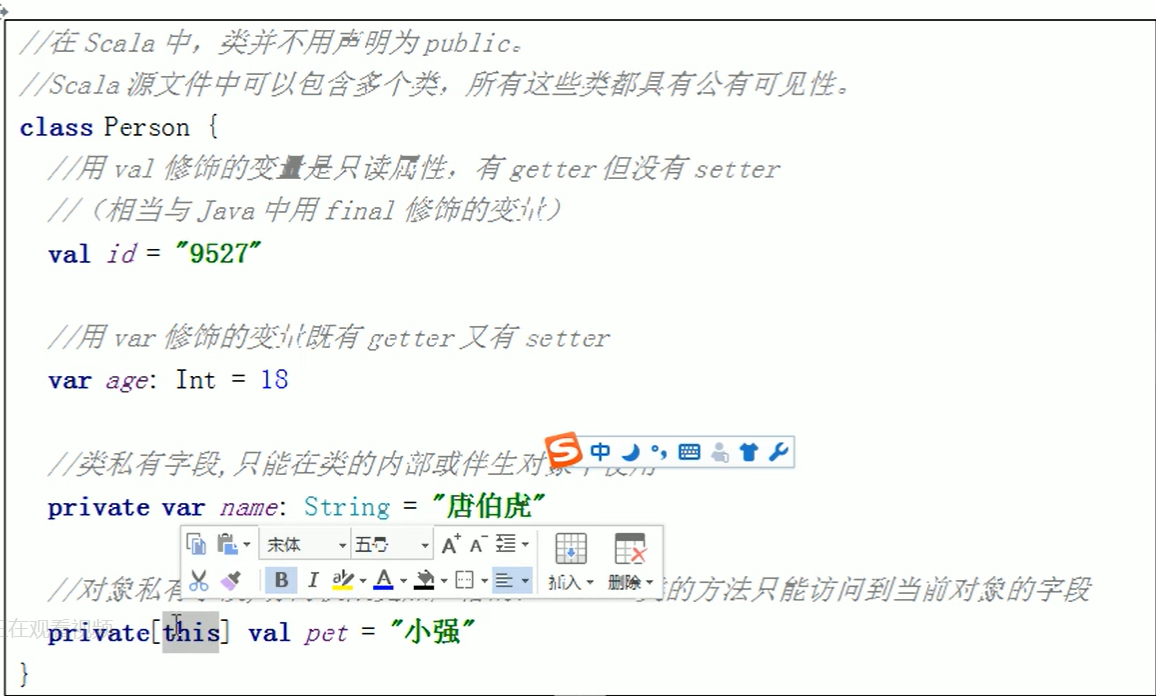
2.伴生类中private 定义的变量,只能在伴生对象中访问,在别的地方访问需要在伴生类中定义获取的方法。


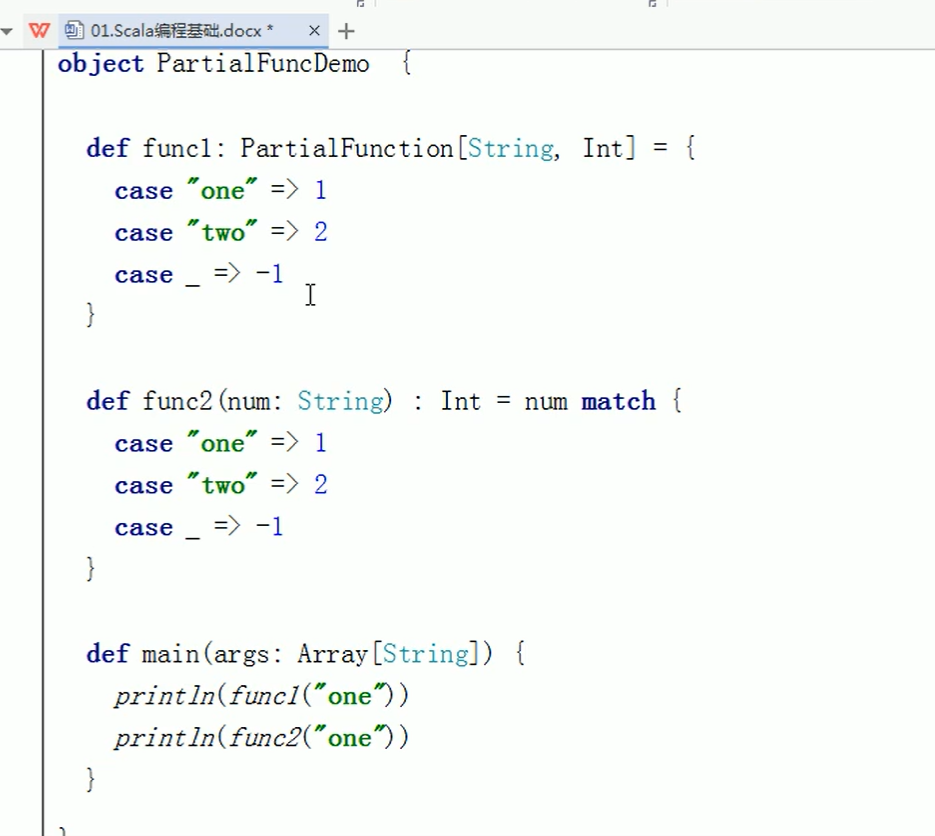
4.隐式转换: https://blog.csdn.net/caoli98033/article/details/41479155
5.泛型:
UpperBound:https://blog.csdn.net/qq_41851454/article/details/80033933

意思是:只要是继承了Comparable接口的子类就可以
ViewBound: https://blog.csdn.net/weixin_33998125/article/details/92430001
ViewBound,形如B<%A,表示B类型要转化成A类型。(结合隐式转换使用)
ContextBound: https://blog.csdn.net/weixin_33781606/article/details/92430004

总的使用方法:https://blog.csdn.net/Vinsuan1993/article/details/74853323?locationNum=1&fps=1
6.二分查找算法:https://baijiahao.baidu.com/s?id=1669750553177807262&wfr=spider&for=pc
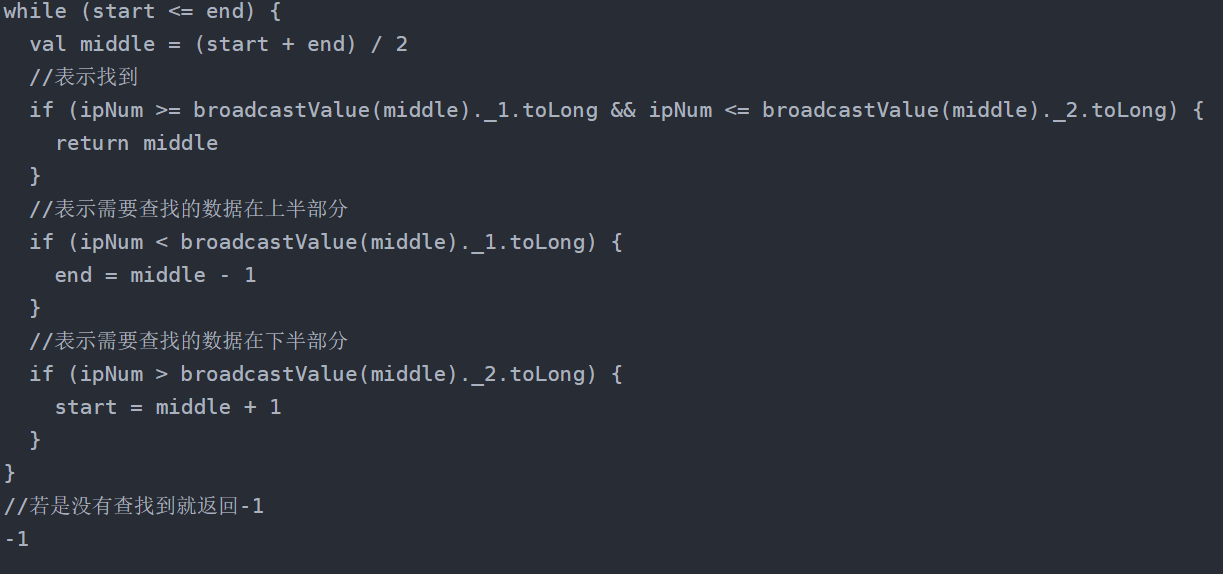
最上边的if必须写return ,加上return跳出while,for,if 等循环,并且不再返回-1,而是返回return后面的值。
iplocation 案例详解:https://blog.csdn.net/NextAction/article/details/107679040
7.spark中的cache和checkpoint

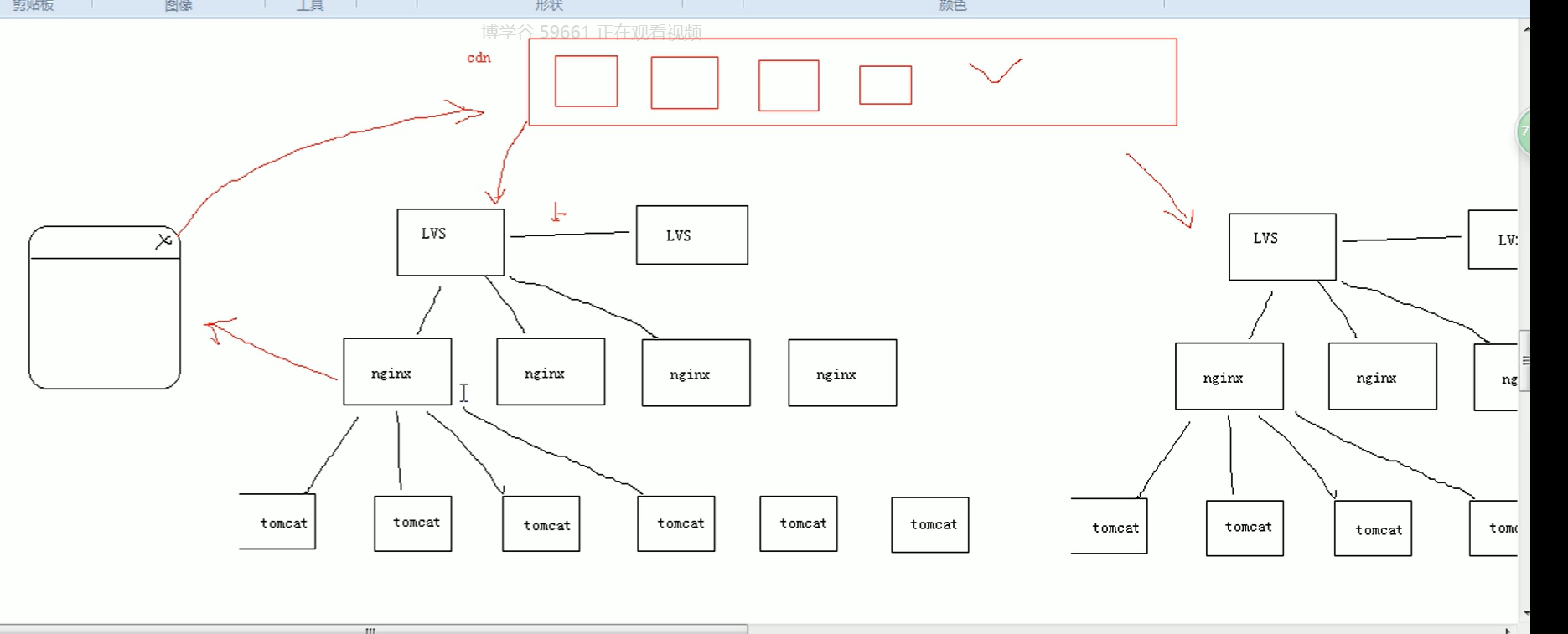
8.双11,双12实际的高可用框架
9.flume对接sparkstreaming的两种方式:https://blog.csdn.net/qq_20641565/article/details/76685697
10.hive和hbase的结合使用:https://blog.csdn.net/weixin_44694973/article/details/98845551
