大数据课程-------hadoop部分
1.namenode元数据管理:

2.linux shell脚本日志采集上传到hdfs脚本
https://www.cnblogs.com/biehongli/p/9010933.html
3.yarn 资源调度器
FIFO(先进先出)调度器
容量调度器(浪费资源)
公平调度器(动态分配)(最优)
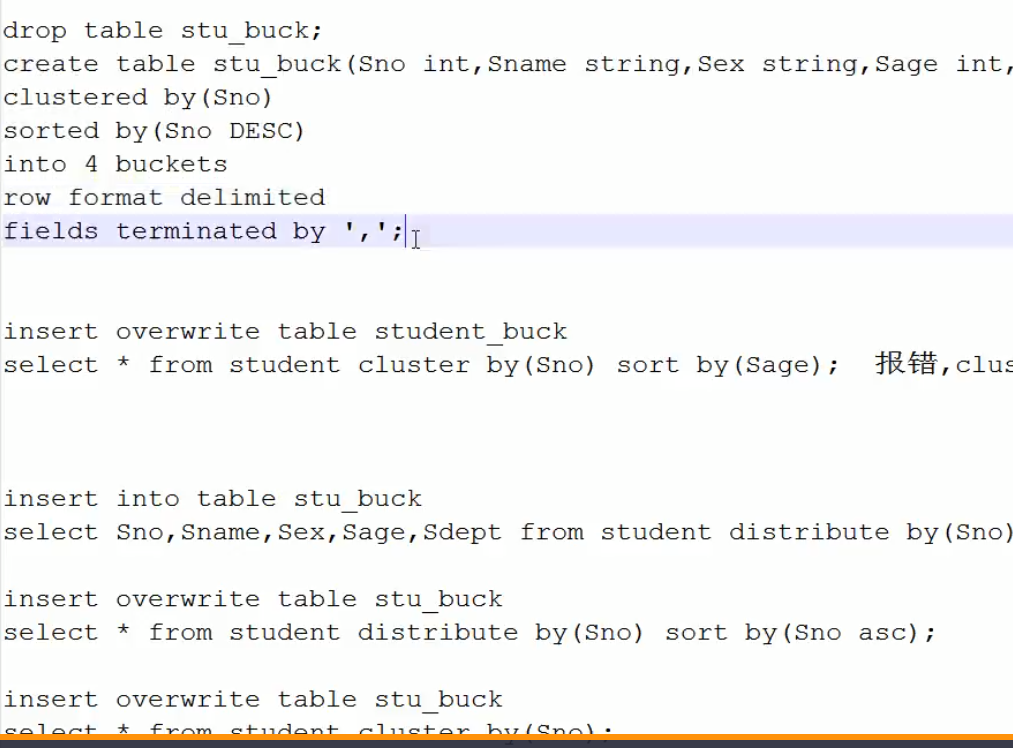
4.hive 的桶表不能通过load加载数据,否则达不到桶的效果。


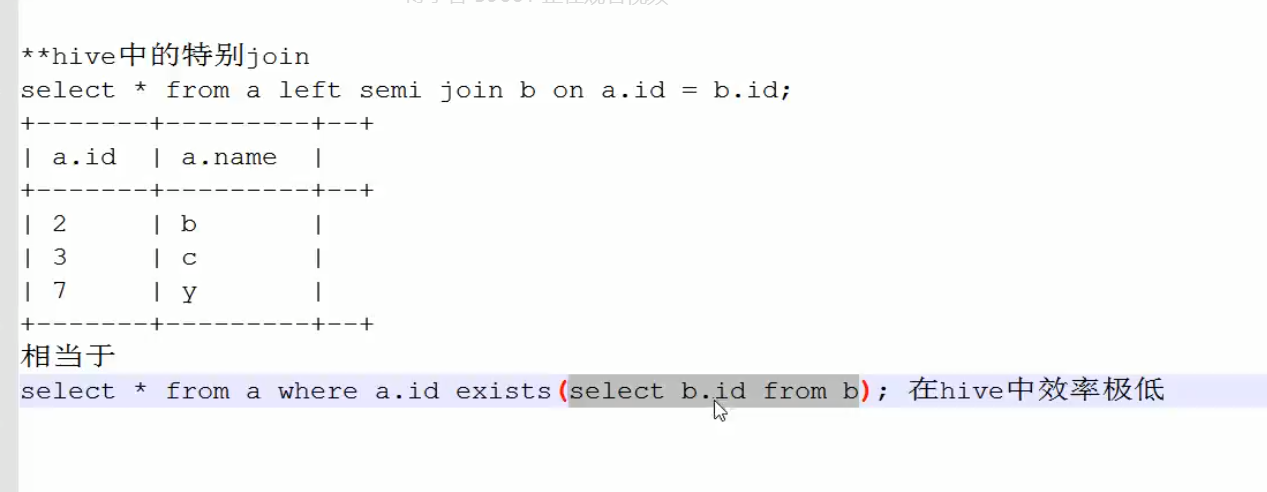
5.hive中的join(exists性能比较低,可以使用left semi join 替代)
6.hive中使用transform实现使用脚本对数据进行处理
https://www.jianshu.com/p/4b7baa050738
7.https://blog.csdn.net/Post_Yuan/article/details/78845273

8.flume采集目录中的文件
【注意点】使用source spooldir采集目录中文件时,不能有同名的文件,否则报错
flume采集文件中的日志
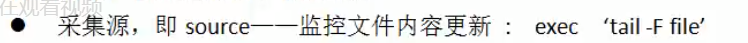
拦截器:使用在source 和channel之间
时间戳拦截器,主机拦截器,静态拦截器,正则过滤拦截器,自定义拦截器
flume的故障转移failover (https://www.cnblogs.com/shay-zhangjin/p/7946282.html)
flume 负载均衡:load_balance(https://blog.csdn.net/weixin_42641909/article/details/88812785)
9.hbase列族越多,在取一行数据时所要参与IO,搜寻的文件就越多,所以,如果没有必要,不要设置太多的列族。
10.habase的读写过程:



布隆过滤器:

hbase的预分区:

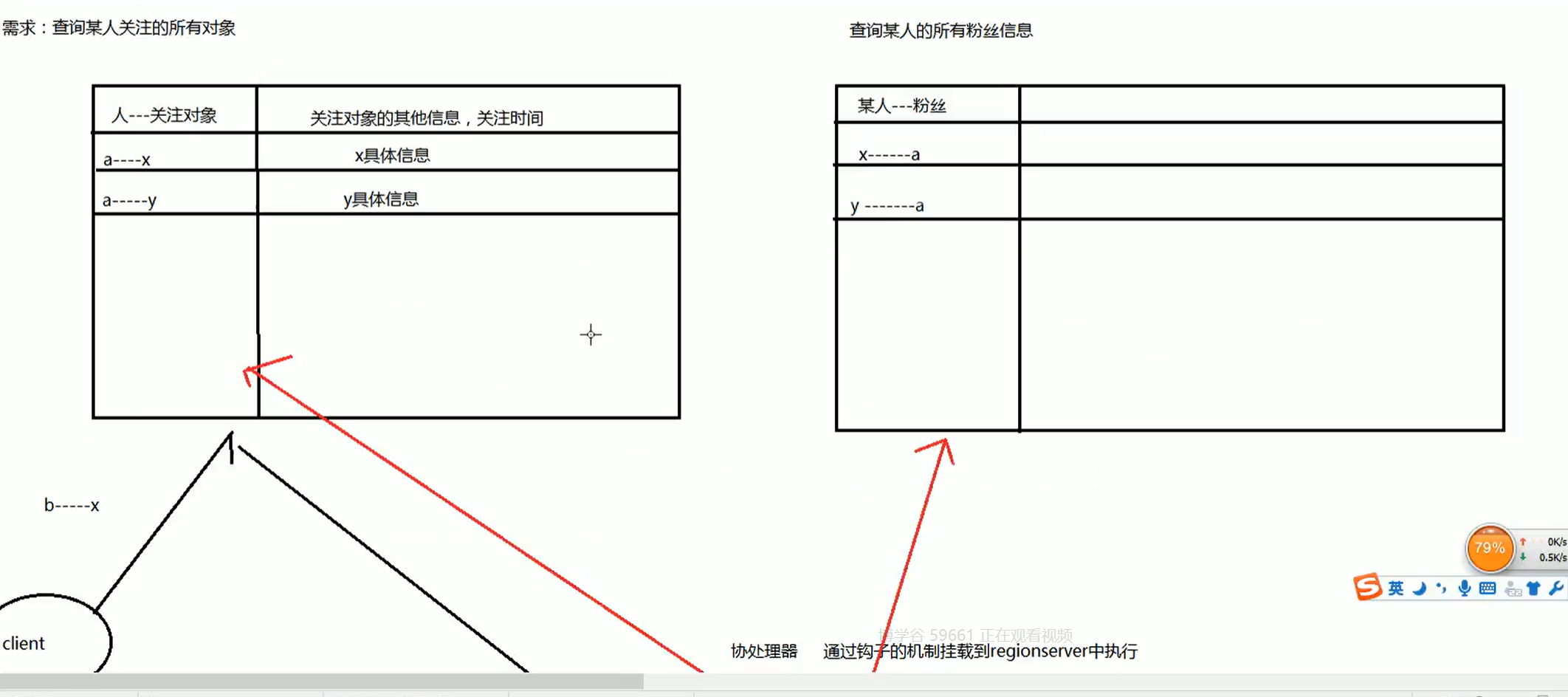
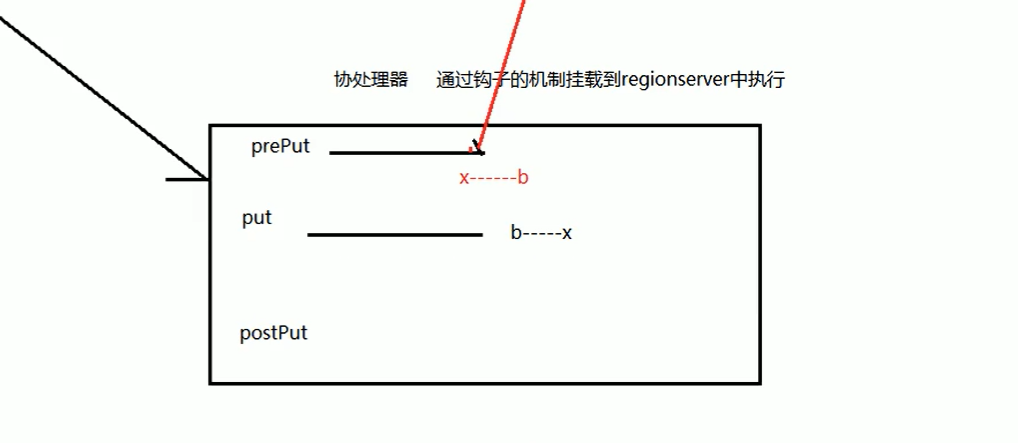
hbase协处理器:【https://blog.csdn.net/moshang_3377/article/details/90723983】