



kafka介绍
kafka中的ISR和ack=-1保证了kafka数据的最大可靠性
https://blog.csdn.net/zhaoyachao123/article/details/89527233
1)kafka的producer的send方法是异步的,当调用send方法提交一条记录到缓冲区之后,立即被返回。这就能够允许生产者能够进行高效组织以批处理来发送数据===》producer.send()===>数据====》producer的缓冲区===》缓冲区满了,或者时间到之后=====》发送数据到kafka集群,send方法立即返回,添加下一条记录。(这样可以防止I/O过多,性能下降)(kafka集群中的数据是存储在磁盘中的,而不是内存中,而且是顺序读写,其速度和内存持平)(磁盘有顺序读写和随机读写)
2)从kafka0.11版本之后,kafka生产者提供两种生产模式:幂等的生产模式和事务的生产模式
在幂等操作下,发送数据不会产生重复的数据。
幂等操作----多次操作的结果和操作一次的结果是一样的。
事务操作----发送数据在一个事务中,如果有异常,将会回滚。
为了运行幂等操作,需要开启参数enable.idempotence=true.一旦被设置,参数retries将会默认设置为Integer.MAX_VALUE,以及参数acks被设置为all.这种幂等api上面没有任何的变化,也就是说在前面的代码中如果开启幂等操作,整个生产的程序就是幂等的。
3)kafka消费组:不同组的消费不受影响,相同组内的消费,需要注意,如果partition有3个,消费者有3个,那么便每一个消费者消费其中一个partition对应的数据。
如何保证kafka的数据一致性:kafka生产者开启幂等或者事务机制。
4)kafka进入分区的策略:
1如果指定的partition,那么直接进入该partition.
2如果没有指定 partition,但是指定了key,使用key的hash选择partition
3如果既没有指定partition,也没有指定key,使用轮询的方式进入partition
生产者可以自己编写分区代码,发送数据
自定义指定分区,自定义hash分区,自定义轮询分区,自定义分组分区(根据业务需要将数据发送到指定分区中)写法:继承Partitioner类,实现里面的parobject RandomPartitioner extends Partitioner{
//随机分区
def partition(topic: String, key: Any, keyBytes: Array[Byte], value: Any, valueBytes: Array[Byte], cluster: Cluster): Int={
var partitionNum: Int = cluster.partitionCountForTopic("")
val i=new Random().nextInt(partitionNum)
i
}
//hash分区(key的hash%partitionNum)
def partition(topic: String, key: Any, keyBytes: Array[Byte], value: Any, valueBytes: Array[Byte], cluster: Cluster): Int={
//获取topic的分区数
var partitionNum: Int = cluster.partitionCountForTopic("")
if(keyBytes!=null){
Math.abs(key.hashCode())%partitionNum
}
0
}
//轮询分区(默认方式)
private var atomicInteger: AtomicInteger = new AtomicInteger()
def partition(topic: String, key: Any, keyBytes: Array[Byte], value: Any, valueBytes: Array[Byte], cluster: Cluster): Int={
//获取topic的分区数
var partitionNum: Int = cluster.partitionCountForTopic("")
atomicInteger.getAndDecrement()%partitionNum
}
//将要分区的数据划分好
var map = new util.HashMap[String,Integer]()
map.put("",0)
map.put("",1)
map.put("",2)
map.put("",3)
//分组分区(按照业务要求的分区)
def partition(topic: String, key: Any, keyBytes: Array[Byte], value: Any, valueBytes: Array[Byte], cluster: Cluster): Int={
val line=value.toString.split(" ")
try{
if(line==null || line.length!=2)
{
0
}else{
val url=new URL(line(1))
val host=url.getHost()
map.get(host)
}
}catch {
case e:Exception=>e.printStackTrace()
}
0
}
//消费者从指定的topic分区中的指定位置消费消息
/**
* 从指定的位置开始消费kafka数据,需要使用assign api
* 自动提交偏移量(容易造成数据的重复)和手动提交偏移量
*/
object ConsumerOffsetTest {
def main(args: Array[String]): Unit = {
//加载配置文件
val properties: Properties = new Properties()
properties.load(this.getClass.getClassLoader.getResourceAsStream(".properties"))
//构建消费者
val consumer: KafkaConsumer[String, String] = new KafkaConsumer[String, String](properties)
//消费的topic
consumer.assign(util.Arrays.asList(
new TopicPartition("topic",0),
new TopicPartition("topic",1),
new TopicPartition("topic",2)
))
//指定消费的偏移量,从offset 10 ,11 处消费,
consumer.seek(new TopicPartition("topic",0),10)
consumer.seek(new TopicPartition("topic",1),11)
consumer.seek(new TopicPartition("topic",2),10)
while(true){
val consumerRecords: ConsumerRecords[String, String] = consumer.poll(1000)
while(consumerRecords.iterator().hasNext){
val consumerRecord=consumerRecords.iterator().next()
val topic=consumerRecord.topic()
val partition=consumerRecord.partition()
val key=consumerRecord.key()
val value=consumerRecord.value()
val offset=consumerRecord.offset()
}
}
}
}
5)kafka组成:kafka topic 由多个分区组成,一个分区由多个segment组成。
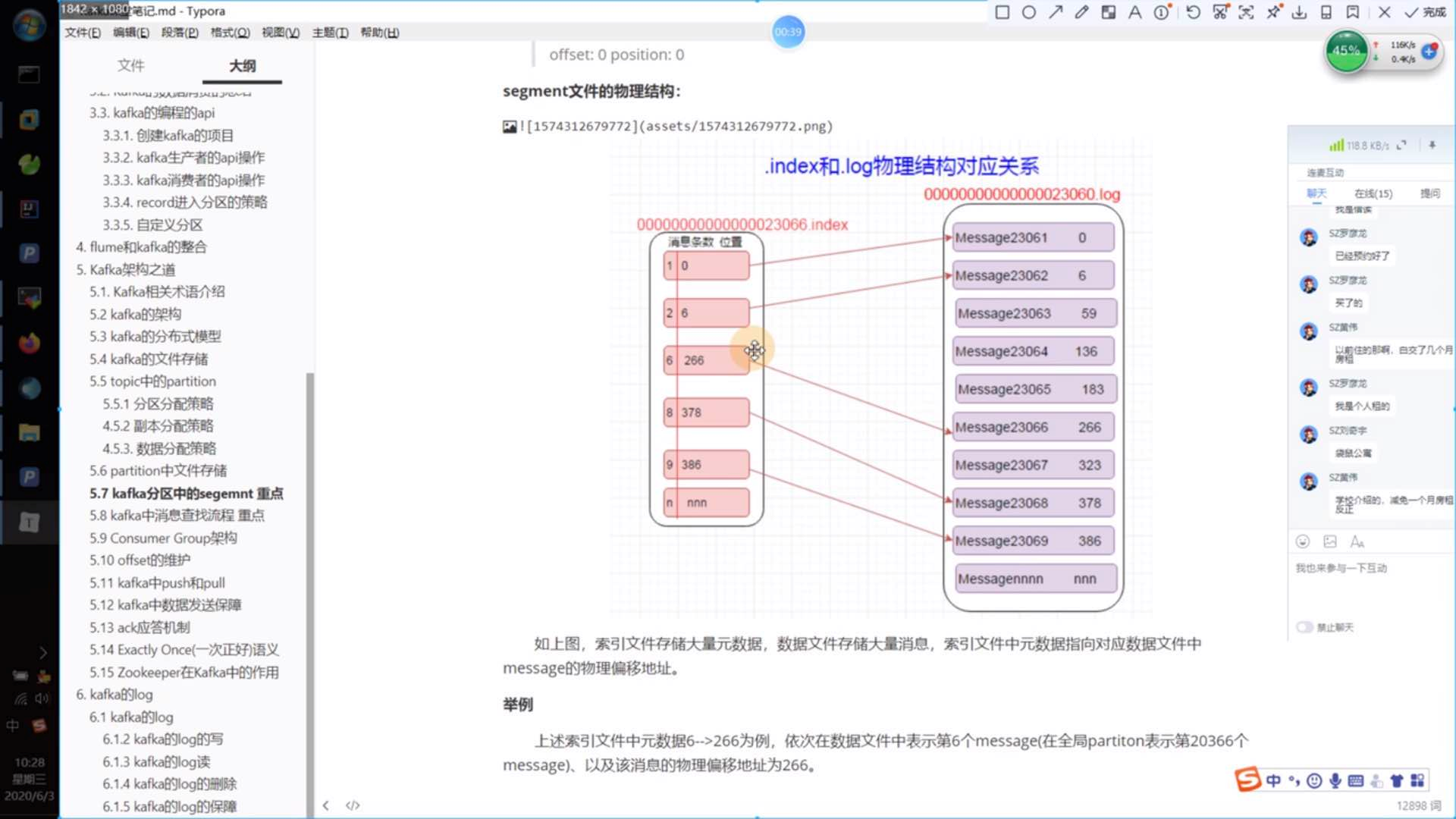
segment file组成:由2大部分组成,分别为index file和log file(即数据文件),这2个文件一一对应,成对出现,后缀.index和.log分别表示为segment索引文件,数据文件。
segment文件命名规则:partition 全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值。数值最大为64位long大小,20位数字字符长度,
不够的左边用0填充。
6)offset维护方式:kafka0.9版本之前默认将offset保存在zookeeper中,但是zookeeper其实并不适合进行大批量的读写操作,尤其是写操作。因此0.9版本之后默认将offset保存在kafka一个
内置的topic中,该topic为_consumer_offsets
查看index和log文件命令:https://www.jianshu.com/p/d12898b74c76
7)kafka中生产者push(推)数据,消费者poll(拉)数据
8)数据发送保障:生产者生产消息的时候会有一个消息保障机制(应答机制),即配置ack机制
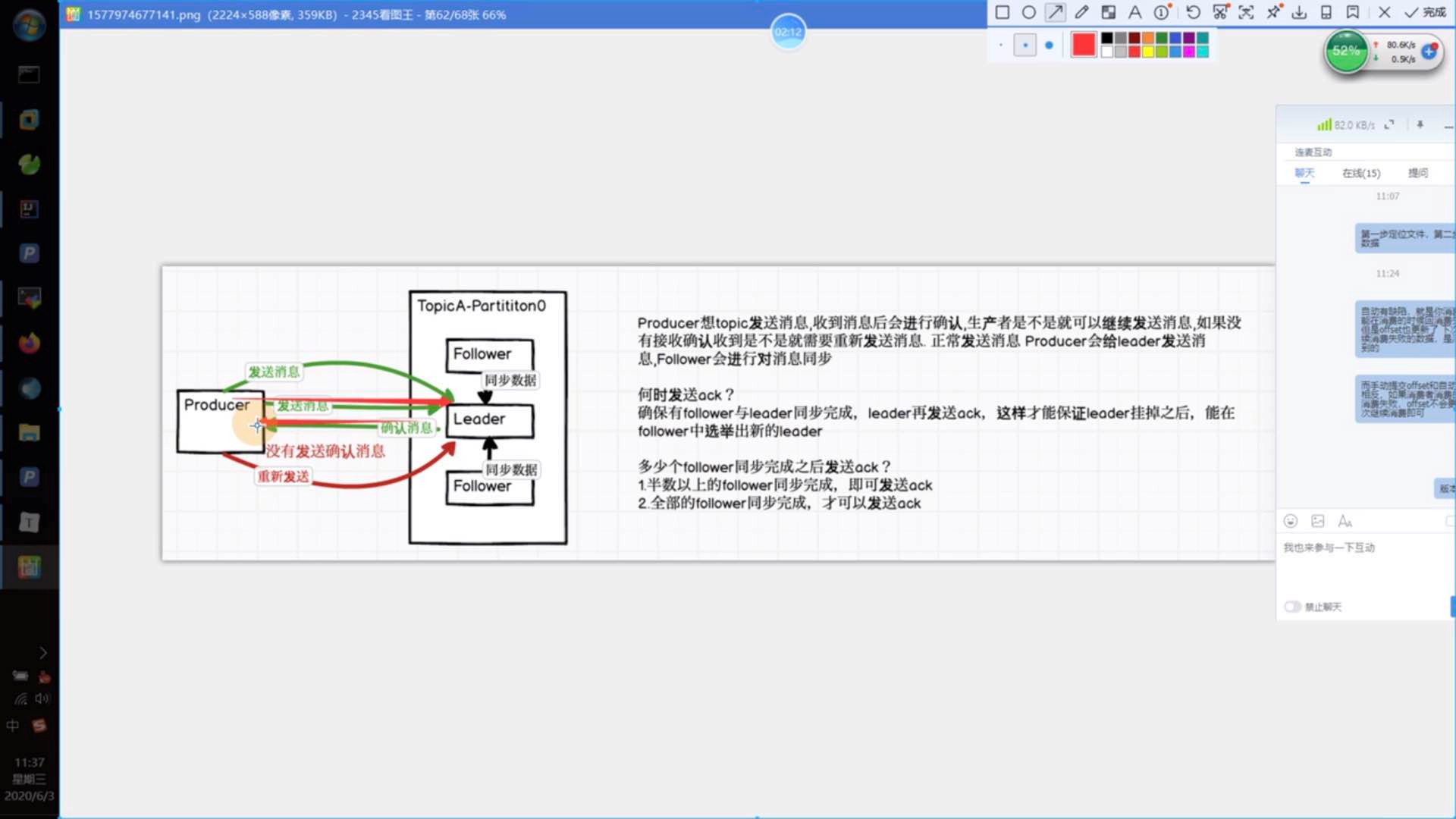
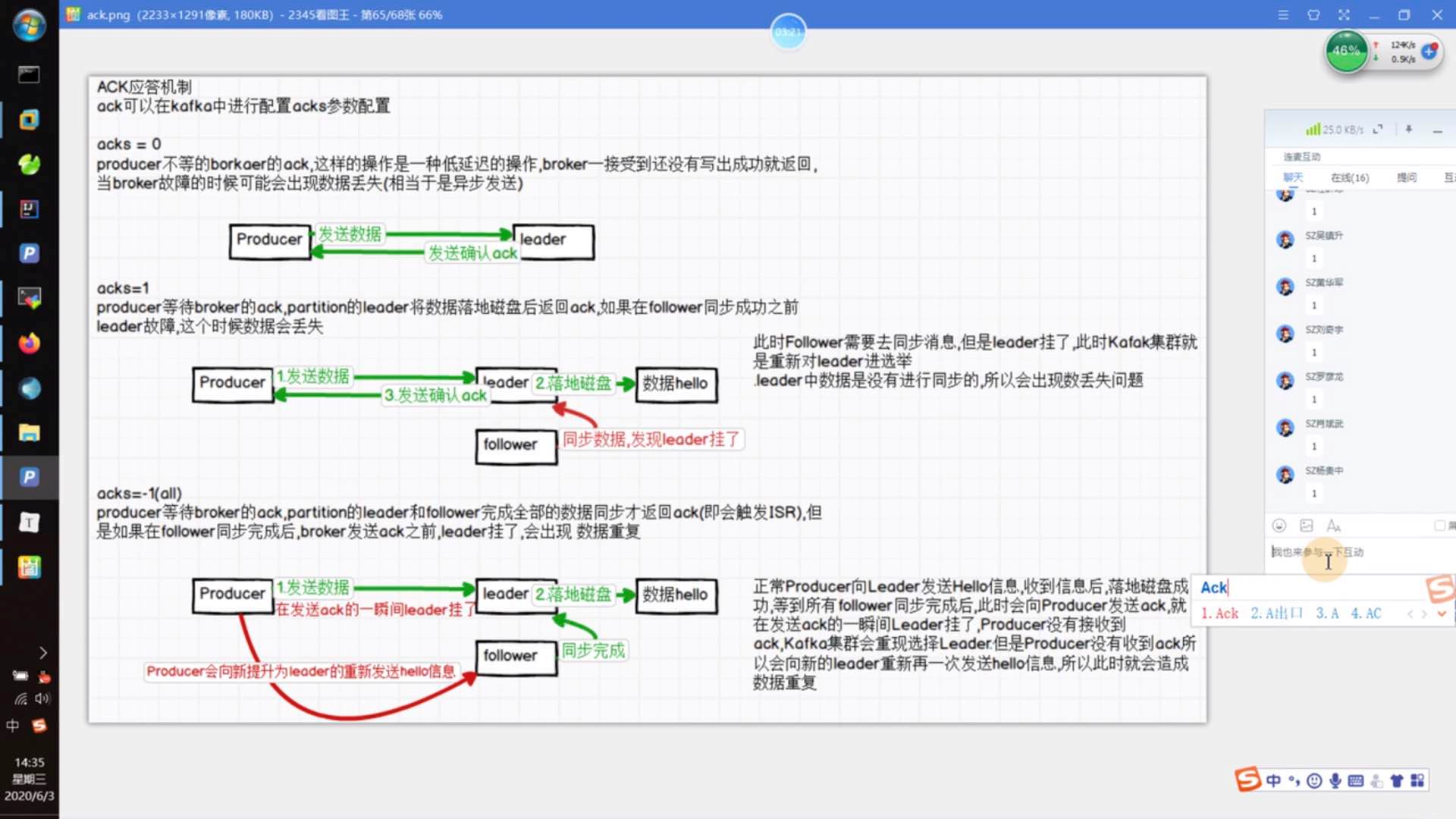
ack=0,1时会出现数据丢失,ack=-1/all时会出现数据重复
exactly one(一次正好)语义:幂等性和ack=all/-1两者结合正好实现一次正好语义。
9)ISR就是保障我们的副本正常同步,如果有其中一个未同步成功,那么此时ISR会将此副本判定为失败副本,会将其清除,再启动一个新的副本进行同步。
10)log消息的读取是先将磁盘中的数据拉取到缓冲区中
11)log消息的删除时间默认是7天,也就是kafka数据默认保存时间是一周。(根据你数据的处理时间和集群的硬件条件设置)

