
spark sql
1)dataframe和dataset区别:
DataFrame 每一行的类型固定为 Row,每一列的值没法直接访问,只有通过解析才能获取各个字段的值
DataSet是每一行的数据类型不同,DataFrame其实就是DataSet的一个特例,type DataFrame = DataSet[Row],DataFrame也可以叫DataSet[Row],每一行的类型为Row,每一行究竟有哪些字段,各个字段的类型是什么无从得知;而DataSet每一行是什么类型是不一定的,自定义case class之后可以很自由的获得每一行中的信息。
dataframe和dataset是spark sql中的编程模型。他们两个编程模型我们可以理解为一张mysql的二维表,表头,表名,表字段,字段类型,数据。RDD其实也可以理解二维表,但是RDD相较于dataframe和dataset来说却少了东西,RDD只有数据。
dataset是spark1.6之后开出的API。dataframe是1.3的时候出现的。早期的dataframe还叫做SchemaRDD,与其他的RDD比较,它多出了一个schema(表名,表字段,字段类型),这就是所谓的元数据信息。
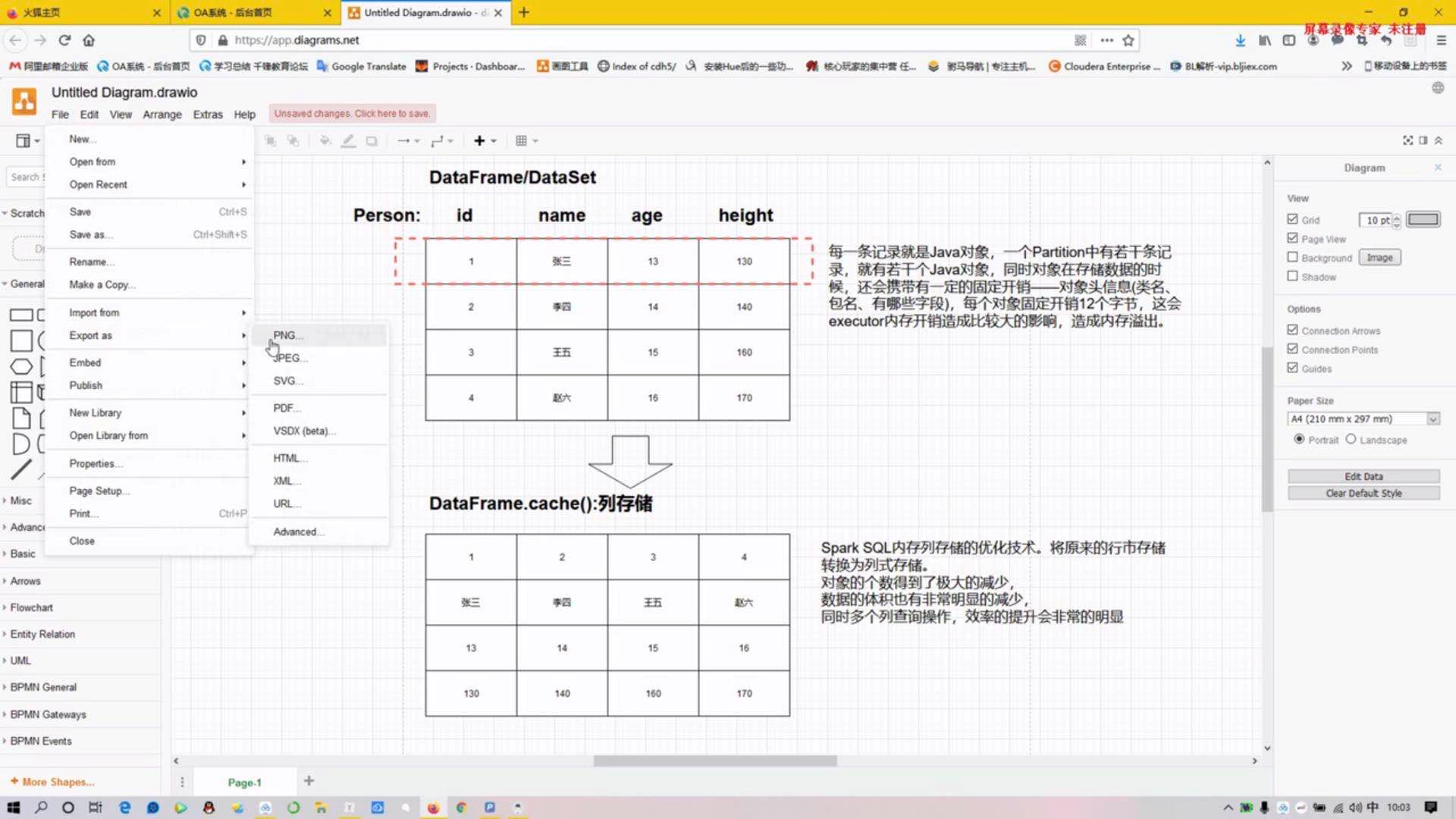
2)spark sql的优化-cache
3)spark sql的优化-数据倾斜,group by (解决方案:先局部聚合-》再全局聚合)
//进行有前缀的局部聚合
val sql2=
"""
|select t2.prefix_word ,count(1) countz from (
|select
|concat_ws("_",cast(floor(rand() * 4) as string),t1.word) as prefix_word
|from (
|select
|explode(split(line," ")) word
|from test
|) t1 ) t2
|group by t2.prefix_word
""".stripMargin
hiveContext.sql(sql2).show()
//去前缀全局聚合
val sql3=
"""
|select t4.up_word,sum(t4.countz) from (
|select substr(t3.prefix_word,instr(t3.prefix_word,'_') + 1) up_word,t3.countz
|from (
|select t2.prefix_word ,count(1) countz from (
|select
|concat_ws("_",cast(floor(rand() * 4) as string),t1.word) as prefix_word
|from (
|select
|explode(split(line," ")) word
|from test
|) t1 ) t2
|group by t2.prefix_word ) t3 ) t4
|group by t4.up_word
""".stripMargin
