



spark算子介绍
spark底层的通信框架:
spark作为分布式的计算框架,多个服务器节点进行相互通信。
spark在最初的时候使用akka的内部通信部件。在spark1.3年代为了接近类似shuffle这样的传输问题。引入了netty通信框架。从1.6配置使用akka或者netty。spark2.0开始完全抛弃了akka,全面使用netty。
为什么不用akka?
不同版本的akka之间无法进行通信。
为什么用netty?
因为netty是作为一个异步的高性能通信框架。
(netty和tomcat区别)https://blog.csdn.net/qq_36318234/article/details/80667878
1)map :返回的结果是one2one
2)flatmap:返回的结果是one2many,对数据中的每一个元素都执行函数。
3)sample:通常查看rdd数据的分布情况从而来完成一些调优和优化工作,数据倾斜(dataskew),通常sample+reduceBykey算子就可以知道哪个key出现的次数最多,出现次数最多的key往往就是发生数据倾斜的key,接下来就是进行数据倾斜的优化了。
4)Union两个算子合并,相当于++
5)join (左半连接:left semi join,结果集只出现左表中的字段信息)
6)groupByKey,因为这个算子没有做本地聚合,性能比较差,一般情况下我们推荐使用reduceByKey或combineByKey或aggregateByKey尽量代替。
7)sortByKey在spark中是分区内有序,不保证全局有序。
8)mapPartitions性能比map要高,但是要注意内存溢出问题,他需要将整个分区中的数据全部加载到内存,分区中数据处理完之后才会释放内存。
9)coalesce和repartition:都是重分区,其实repartition就是使用coalesce实现的。coalesce默认是窄依赖,repartition产生宽依赖,coalesce一般用于减少分区的操作,repartition一般用于增大分区。【注意】(coalesce默认是没有开启shuffle,所以他只能做分区减少操作,要想增加分区,必须开启shuffle)【一般使用repartition,既能增大分区,也能减少分区】
10)cogroup:可以对多个RDD根据key进行分组,然后将每个key相同的元素分别聚集为一个集合返回一个新的RDD(k,(Iterable[v],Iterable[w])),将两个pairRDD按key进行合并,返回各自的迭代。
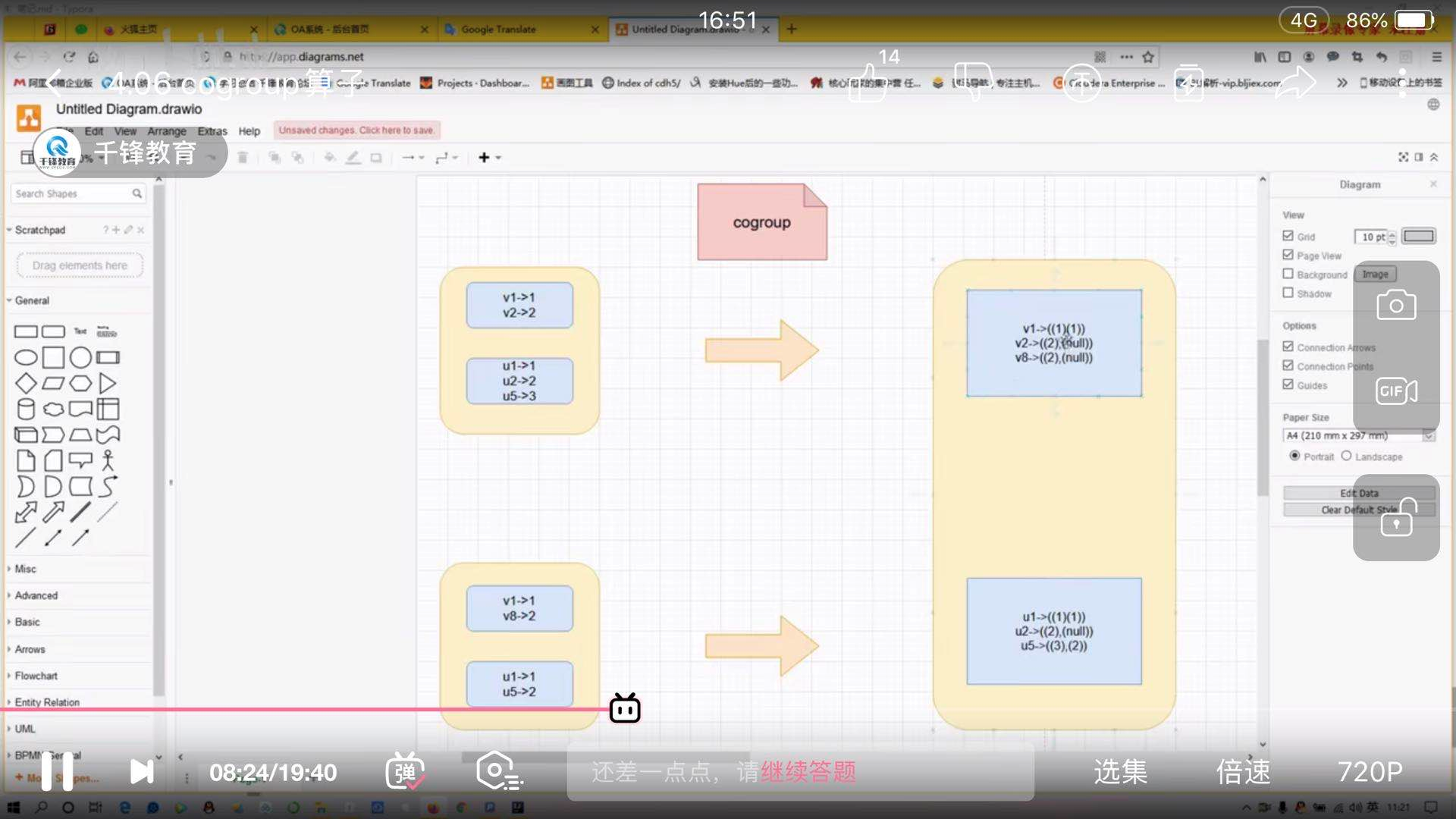
11)mapPartitionsWithIndex:该算子可以获取具体的分区信息,func函数的第一个参数类型是Int,含义是分区的partition编号
mapPartitionsWithIndex(func:(Int,Iterator[T])=>Iterator[U]])
12)combineByKey:
源码:def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C,
partitioner: Partitioner,
mapSideCombine: Boolean = true,
serializer: Serializer = null)
createCombiner相同的key在每个分区中调用一次函数,用于创建聚合之后的类型,为了和后续key相同的数据进行聚合(在每个分区中进行局部聚合)
mergeValue在相同的分区中基于上述createCombiner基础之上进行聚合(在每个分区中进行)
mergeCombiners该函数把2个元素C合并 (这个操作在不同分区间进行)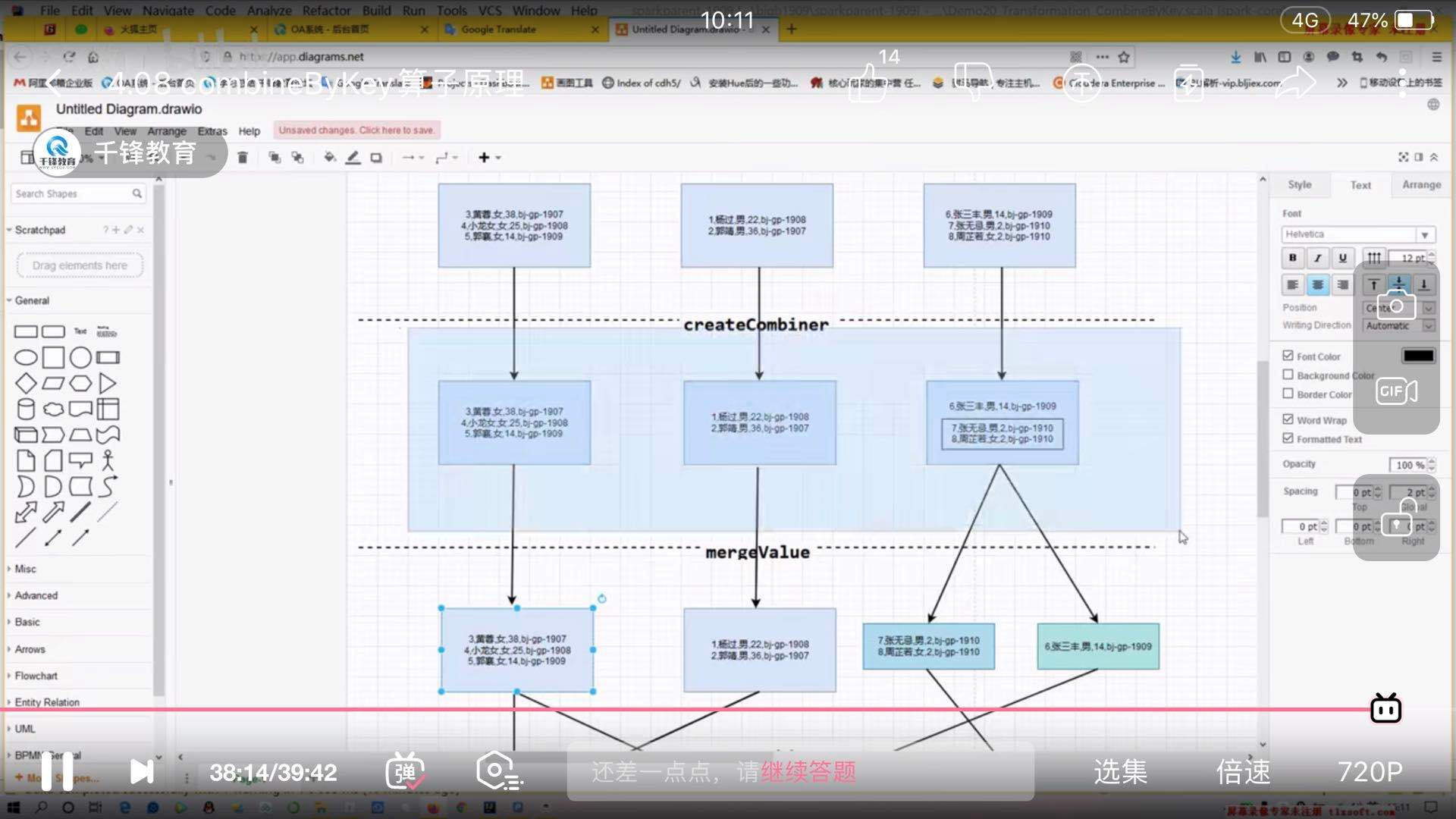
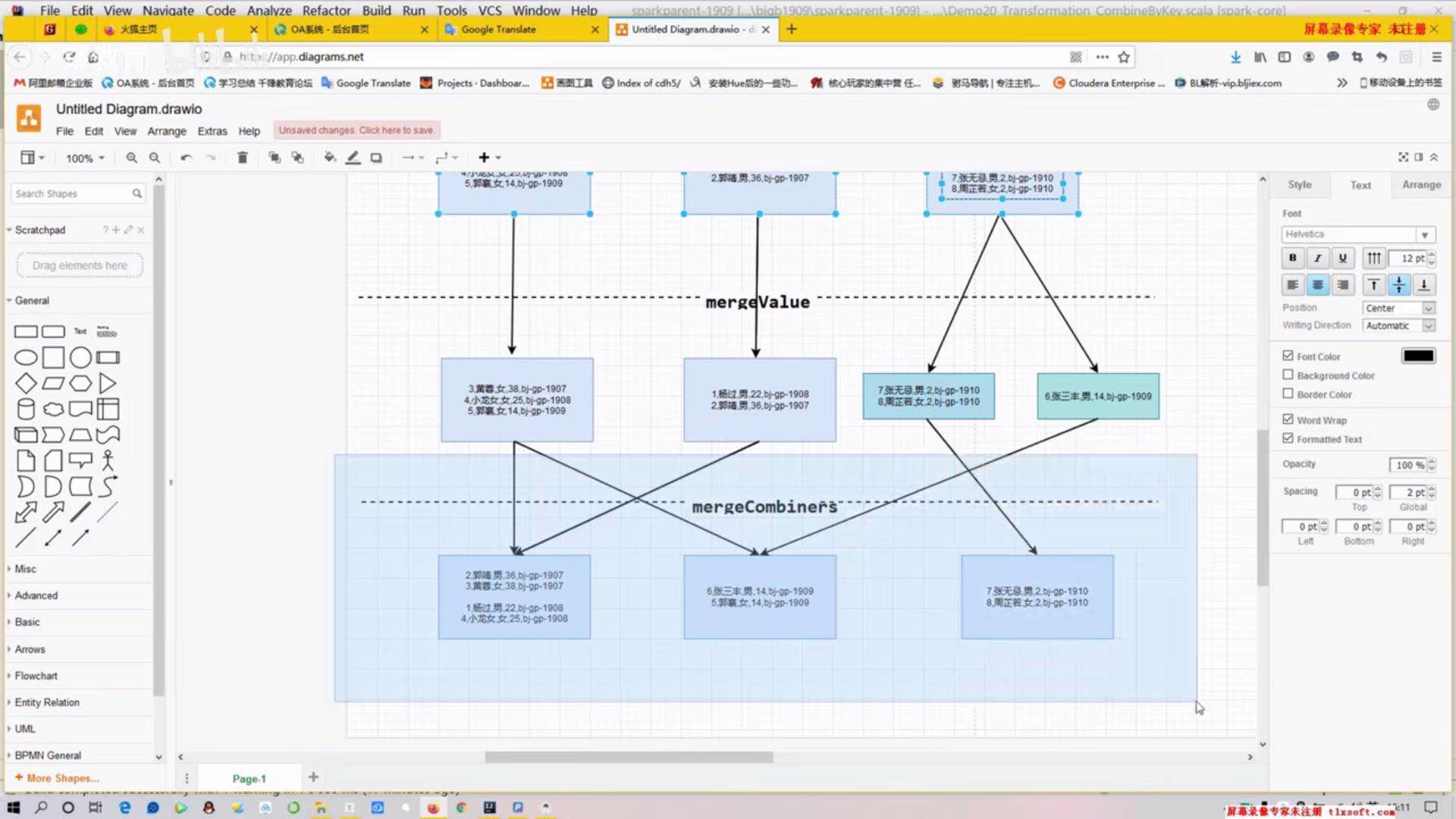
combineByKey可以代替groupByKey和reduceByKey.
/* //combineByKey模拟reduceByKey
val mapRDD=sc.parallelize(list).flatMap(line=>line.split(",")).map(line=>(line,1))
mapRDD.combineByKey((num:Int)=>num,
(sum:Int,num:Int)=>sum+num,
(sum1:Int,sum2:Int)=>sum1+sum2).foreach(println)
//或者下边写法
mapRDD.combineByKey(createCombiner,mergeValue,mergeCombiners)*/
//groupByKey
/*def createCombiner(num:Int):Int = num
//每个分区内聚合
def mergeValue(sum:Int,num:Int): Int ={
sum+num
}
//全局分区内聚合
def mergeCombiners(sum1:Int,sum2:Int):Int = sum1 + sum2*/
//combineByKey模拟groupByKey
val list = List(
"1,杨过,男,22,1908",
"2,郭靖,男,36,1907",
"3,黄蓉,女,38,1907",
"4,小龙女,女,25,1908",
"5,郭襄,女,14,1909",
"6,张三丰,男,14,1909",
"7,张无忌,男,2,1910",
"8,周芷若,女,2,1910"
)
val class2InfoRdd = sc.parallelize(list, 3).mapPartitionsWithIndex {
case (partition, iterator) => {
val array = iterator.toArray
array.map(line => {
val dotIndex = line.lastIndexOf(",")
val classname = line.substring(dotIndex + 1)
val info = line.substring(0, dotIndex)
(classname, info)
}).toIterator
}
}
class2InfoRdd.combineByKey(createCombiner,mergeValue,mergeCombiners)
//key相同的会被存放到同一个ArrayBuffer
def createCombiner(stu:String):ArrayBuffer[String] ={
val ab=ArrayBuffer[String]()
ab.append(stu)
ab
}
//每个分区部分聚合
def mergeValue(ab:ArrayBuffer[String],stu:String):ArrayBuffer[String]={
ab.append(stu)
ab
}
//全局聚合
def mergeCombiners(ab1:ArrayBuffer[String],ab2:ArrayBuffer[String]):ArrayBuffer[String]={
ab1.++:(ab2)
}
combineByKey链接:https://www.jianshu.com/p/b77a6294f31c
13)aggregateByKey
aggregateByKey和combineByKey本质上二者之间没有啥太大的区别,区别在于使用的选择而已。
//
/*
seqOp:按相同的一组key的分区内部进行聚合
combOp:按相同的一组key的全分区进行聚合
zeroValue初始值是0
*/
//模拟reduceByKey,第一个函数实现局部聚合,第二个函数实现全局聚合
val reduceByKeyRdd=sc.parallelize(list).flatMap(line=>line.split(",")).map(line=>(line,1)).aggregateByKey(0)(_+_,_+_)
reduceByKeyRdd.foreach(println)
//模拟groupByKey
val class2InfoRdd = sc.parallelize(list, 3).mapPartitionsWithIndex {
case (partition, iterator) => {
val array = iterator.toArray
array.map(line => {
val dotIndex = line.lastIndexOf(",")
val classname = line.substring(dotIndex + 1)
val info = line.substring(0, dotIndex)
(classname, info)
}).toIterator
}
}
class2InfoRdd.aggregateByKey(ArrayBuffer[String]())(seqOp,combOp).foreach(println)
}
//局部聚合
def seqOp(ab:ArrayBuffer[String],info:String):ArrayBuffer[String]={
ab.append(info)
ab
}
//全局聚合
def combOp(ab1:ArrayBuffer[String],ab2:ArrayBuffer[String]):ArrayBuffer[String]={
ab1.++:(ab2)
}
14)行动算子foreach,count,take,first,collect(字面解释就是收集,拉取的意思。该算子的含义是将分布在集群中的各个partition中的数据拉取到driver中,进行统一的处理;
但是这个算子有很大的安全危险,第一,对driver造成比较大的压力,第二,数据在网络中大规模效率低;所以一般不建议使用,如果非要使用,请先进行filter),reduce(reduce是action算子,
reduceByKey是一个transfmation算子,reduce对一个rdd执行聚合,并返回结果集),countByKey(key出现的次数)
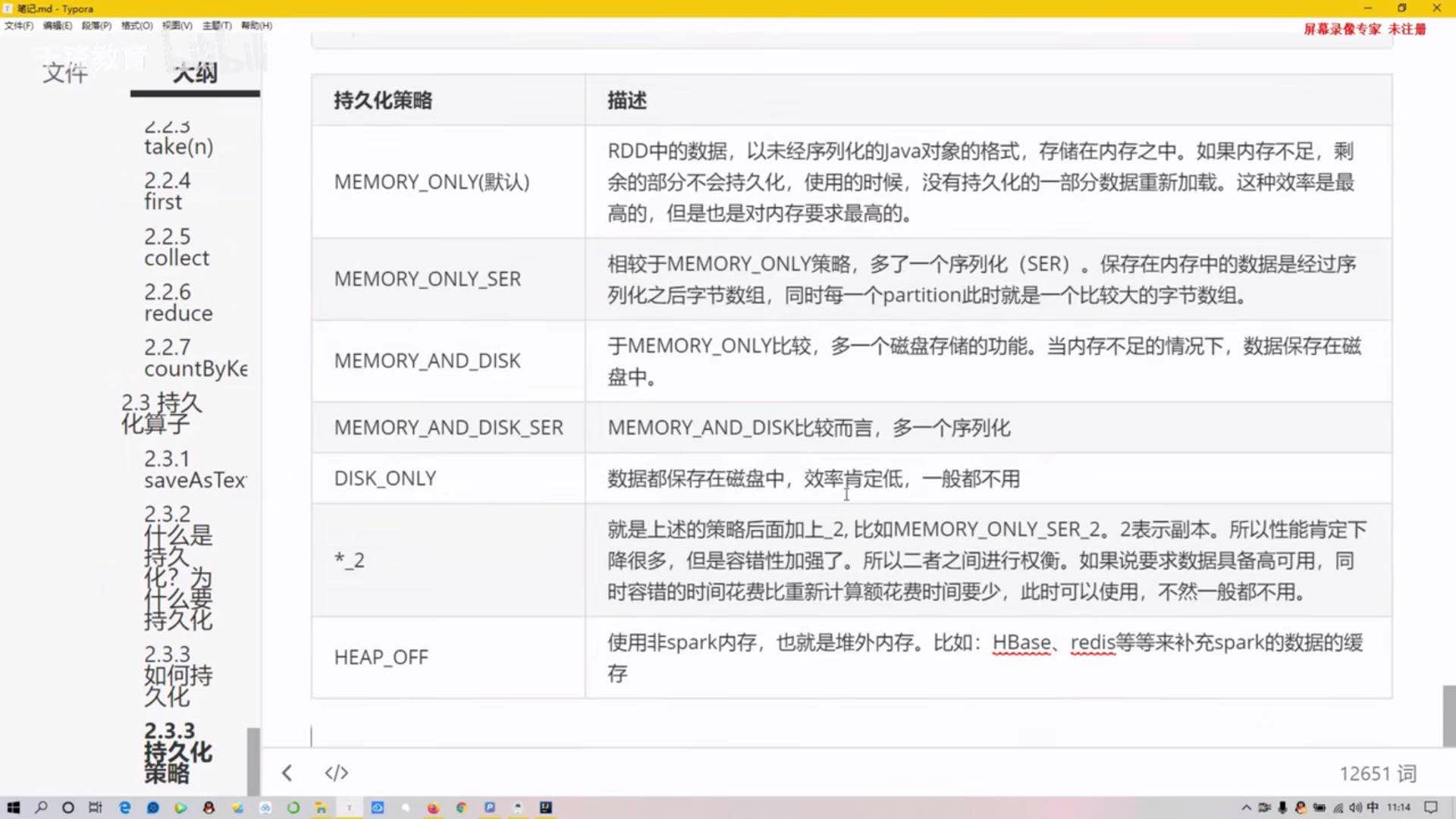
15)持久化算子
saveAsTextFile()
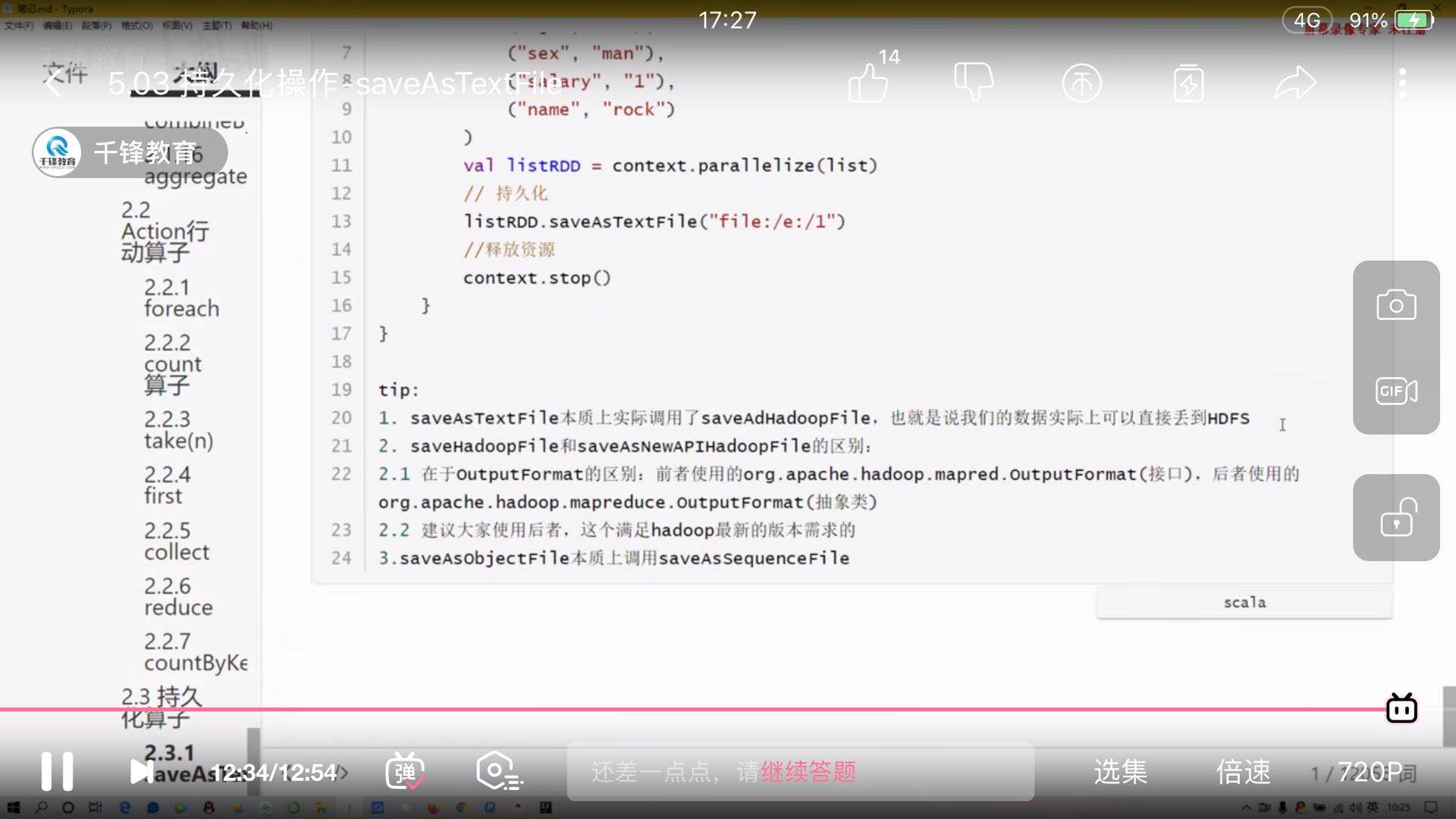
持久化策略:persist(),cache(),每个rdd使用不同的存储级别进行存储。(序列化会压缩数据,降低内存的开销)
共享变量:累加器和广播变量。
(1)广播变量:原先是将变量拷贝每个task,效率太低。广播变量就是变量广播给需要的executor,而需要运行的task直接从executor中直接调用需要的变量即可。此方式大大的提高了性能。
(2)累加器
16)高级排序
【sortByKey和sortBy都是分区内排序】
sortByKey(局部排序,分区内排序)【要想全部有序,设置分区为一】
sortBy算子除了正常的升序,分区个数以外的参数,还需要传递一个原始类型,提取其中用于排序的字段,并且也提供了一个用于比较的方式,以及运行时的数据类型classTag标记
def sortBy[K](
f: (T) => K,
ascending: Boolean = true,
numPartitions: Int = this.partitions.length)
(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T] = withScope {
this.keyBy[K](f)
.sortByKey(ascending, numPartitions)
.values
}
17)spark目前支持hash分区和range分区,用户也可以自定义分区。hash分区是默认的分区规则,spark中分区器直接决定了rdd中的分区的个数,rdd中的每条数据经过shuffle过程。
HashPartitioner:默认分区器。
RangePartitioner分区器。
自定义分区器。

