

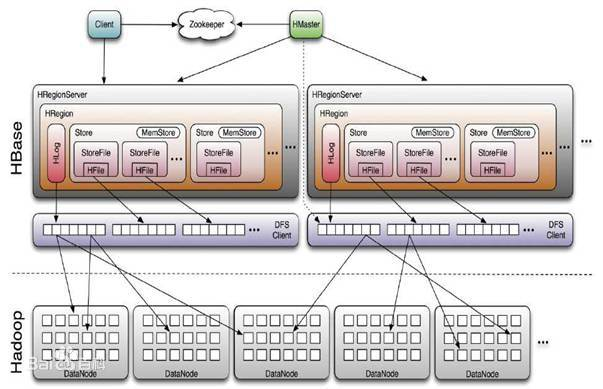
hbase预分区
eg:
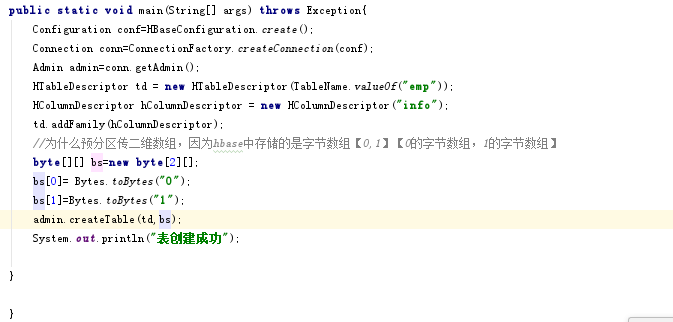
rowkey设置:0|代表 任何0_xxx都比0|小 (本来0_xxx比0大的,但是0_xxx比0|小)【|是ASCII中第二大值,最大是},但一般不使用}】
hbase在创建表的时候,一开始只有一个Region,当数据量越来越大时,此region不能承受数据量,就会进行split
这种方式有两种缺点:1.数据往一个region上写,会有写热点问题
2.region split会消耗宝贵的集群I/O资源
所以引入了预分区概念。
https://blog.csdn.net/javajxz008/article/details/51913471
rowkey的设计:一条数据存储于哪个分区,取决于rowkey处于哪个预分区的区间内,设计rowkey的目的,就是让数据均匀的分布于所有的region中,在一定程度上防止数据倾斜。
rowkey的设计原则:
(1)唯一性原则
(2)长度原则(不能太长,不能太短)(满足查询条件下越短越好)(60-80字节,最大值是64k)
(3)散列原则(rowkey均匀分配,均匀的分配在各个节点上,避免Region热点问题)
解决region热点问题:
【1】Reverse反转:(这样可以使Rowkey中经常改变的部分放在最前面,可以有效的随机rowkey.例如:反转rowkey的例子通常以手机为例,可以将手机号反转后的字符串作为rowkey,这样就避免了以手机号那样比较固定开头导致热点问题)
【2】salt加盐(salting是将没哟个rowkey加一个前缀,前缀使用一些随机数字符,使得数据分散在多个不同的region,达到region负载均衡的目标)
【3】Hash散列或者Mod(用Hash散列来替代随机Salt前缀的好处是能让一个给定的行有相同的前缀,这在分散了region负载的同时,使读操作也能够推断。确定性hash(比如MD5后取前4位做前缀)能让客户端重建完整的rowkey,可以使用get操作直接get想要的行,如果rowkey是数据类型的,也可以考虑Mod方法)
1.生成随机数,hash,散列值
2.字符串反转(20170524000001-》10000042507102,20170524000002-》20000042507102,散列)
3.字符串拼接(20170524000001-》20170524000001_a12e,20170524000001-》20170524000001_93i7)
当MemStore达到阈值,将MemStore中的数据flush进StoreFile;compact机制则是把flush出来的小文件合并成大的StoreFile文件,split则是当Region达到阈值,会把过大的Region一分为二。
hbase写流程:
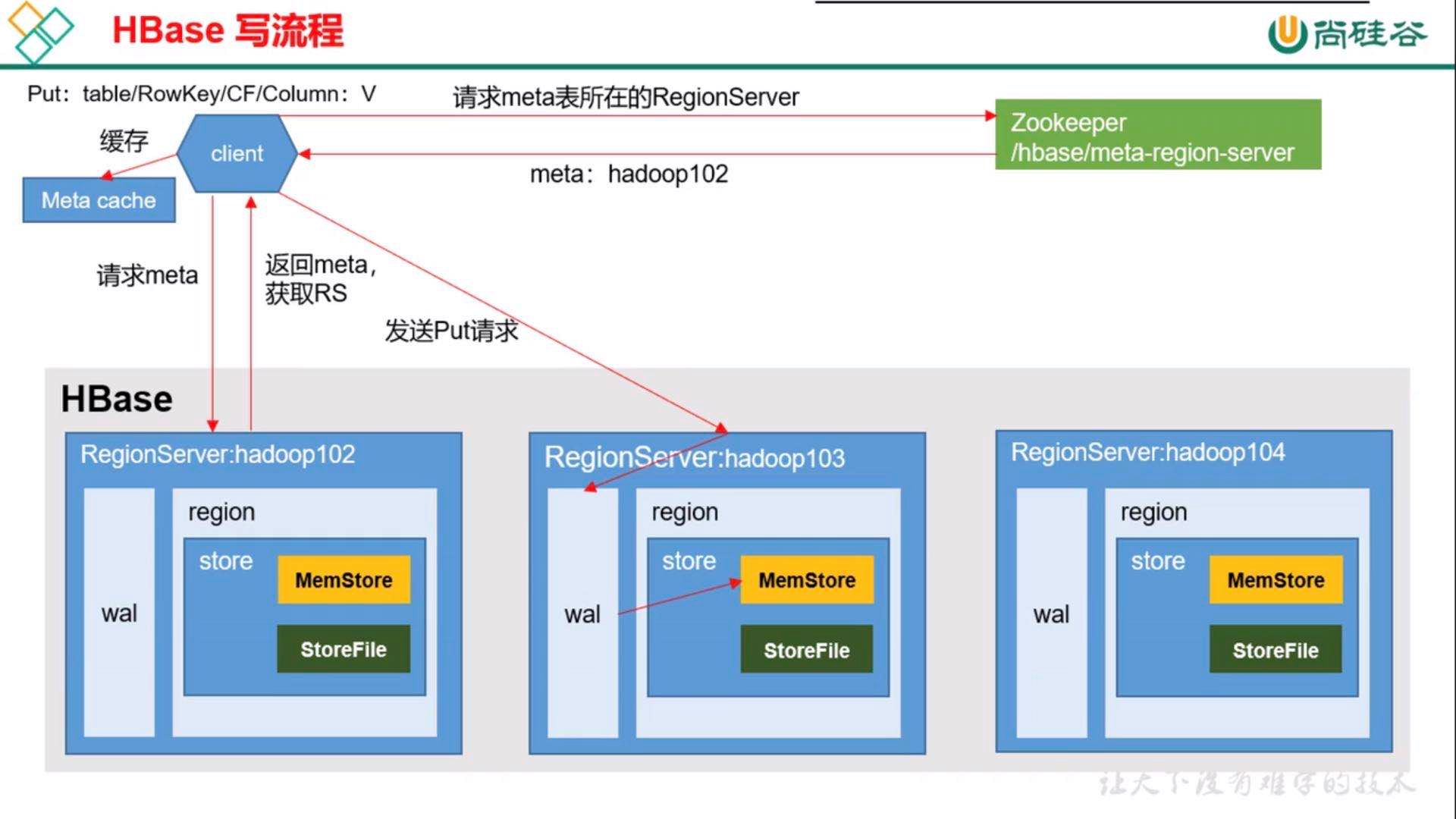
MemStore flush机制:(1)当内存到达设置的大小时,flush到StoreFile,默认是堆内存的40%,flush会阻塞客户端的读写。堆内存的40%*95%时,开始flush,如果写速度大于flush速度时,memstore继续增大,当达到40%时,阻塞客户端读写。(全部的memstore都会flush,且按照memstore内存大小进行排序flush)
(2)当数据写入后1小时,一直没有再写数据且没有到达内存的flush大小时,就会把写入的数据flush到storeflie.
(3)当单个的Hregion中memstore到达128M时(设置的),单个的Hregion flush。
Hbase读流程:
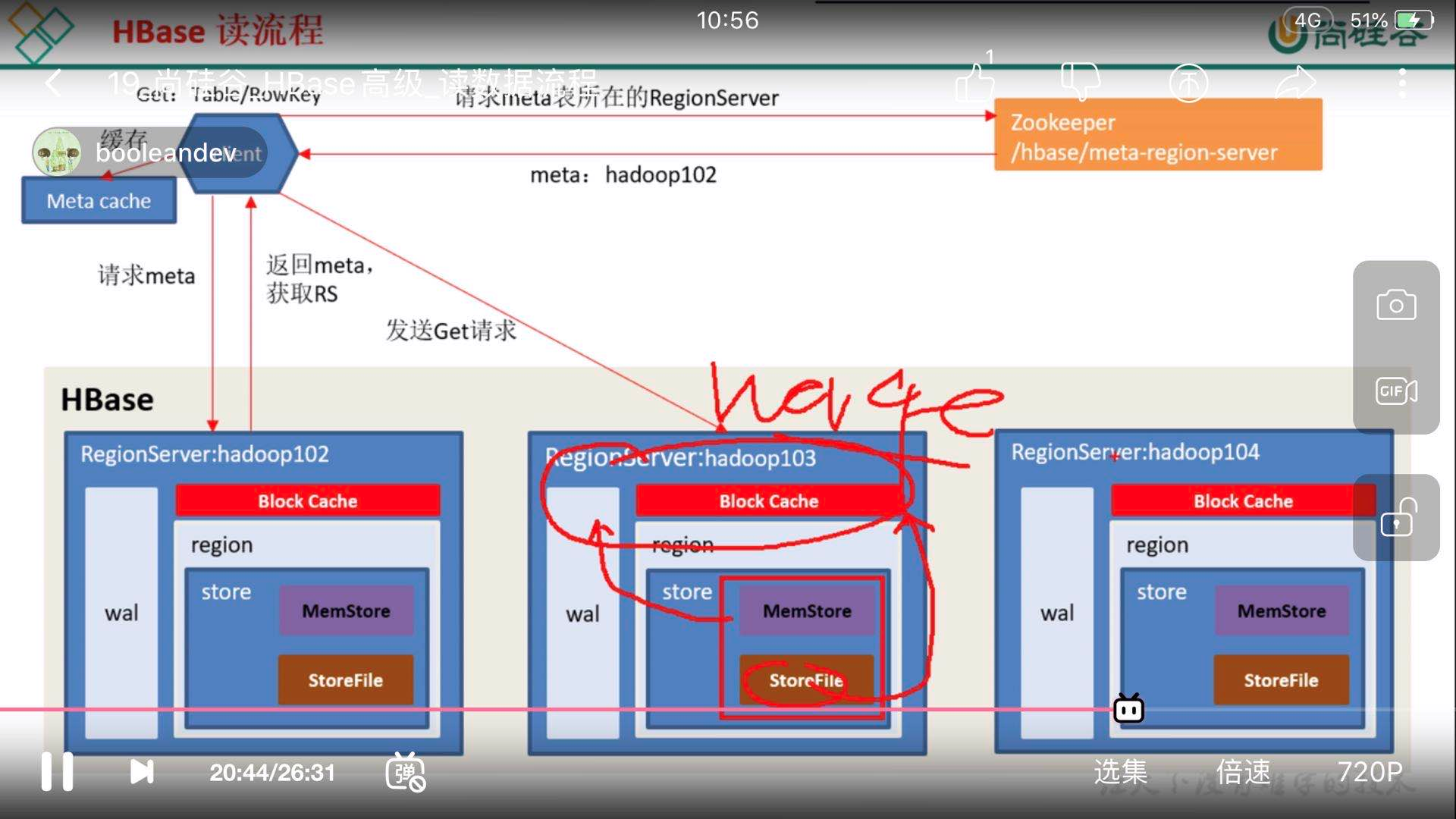
先读取内存中的数据,如果没有读取再到BlockCache里面读,BlockCache还没有,再到StoreFile上读(为了读取的效率);
storefile compaction(磁盘文件合并)
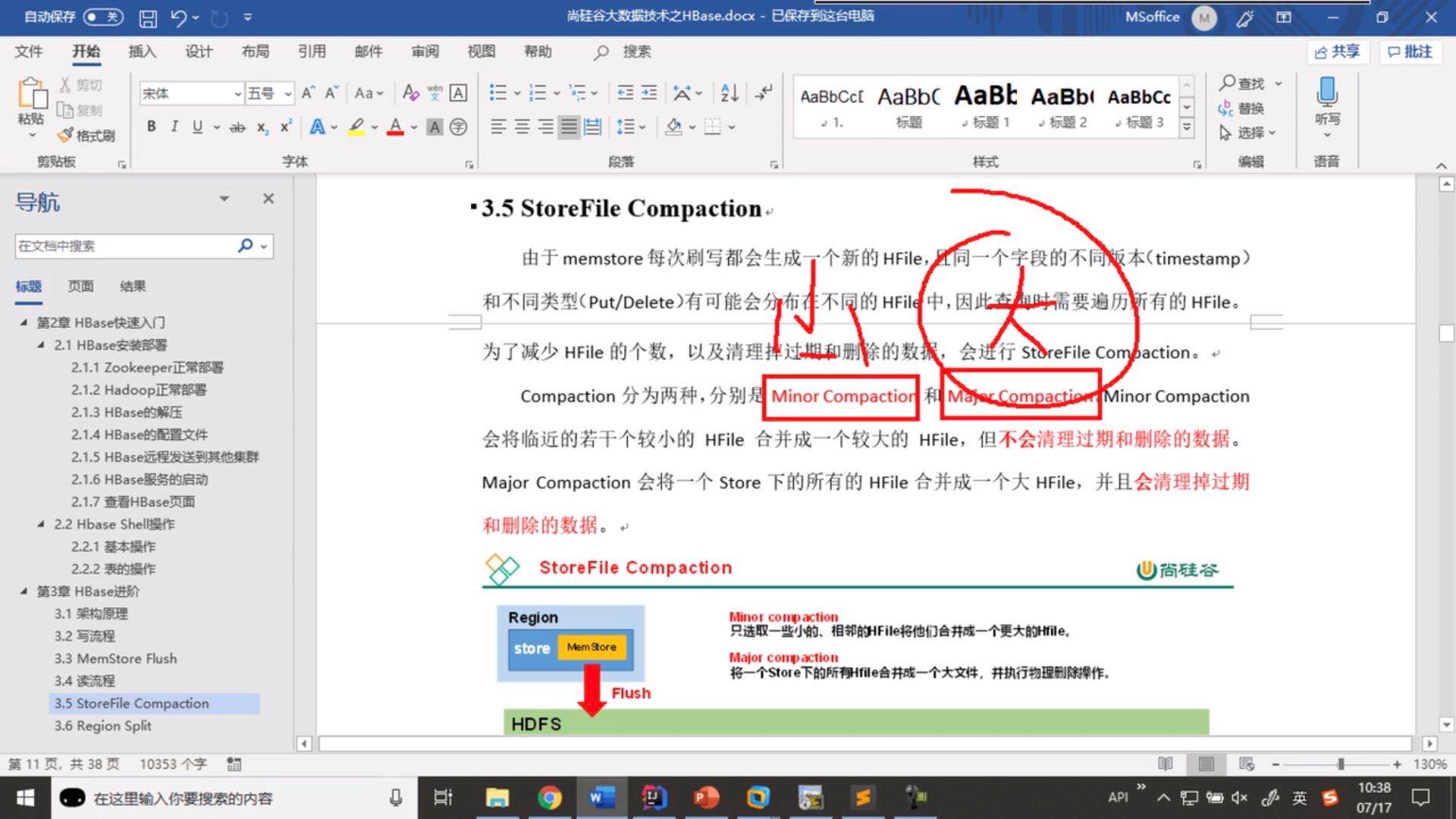
(1)设置中有一个参数,默认多少天(不管有多少个hfile)都进行一次合并(生产中是关闭的,合并耗费资源)
(2)当超过多少个storefile时,执行一次合并,合并成一个storefile。
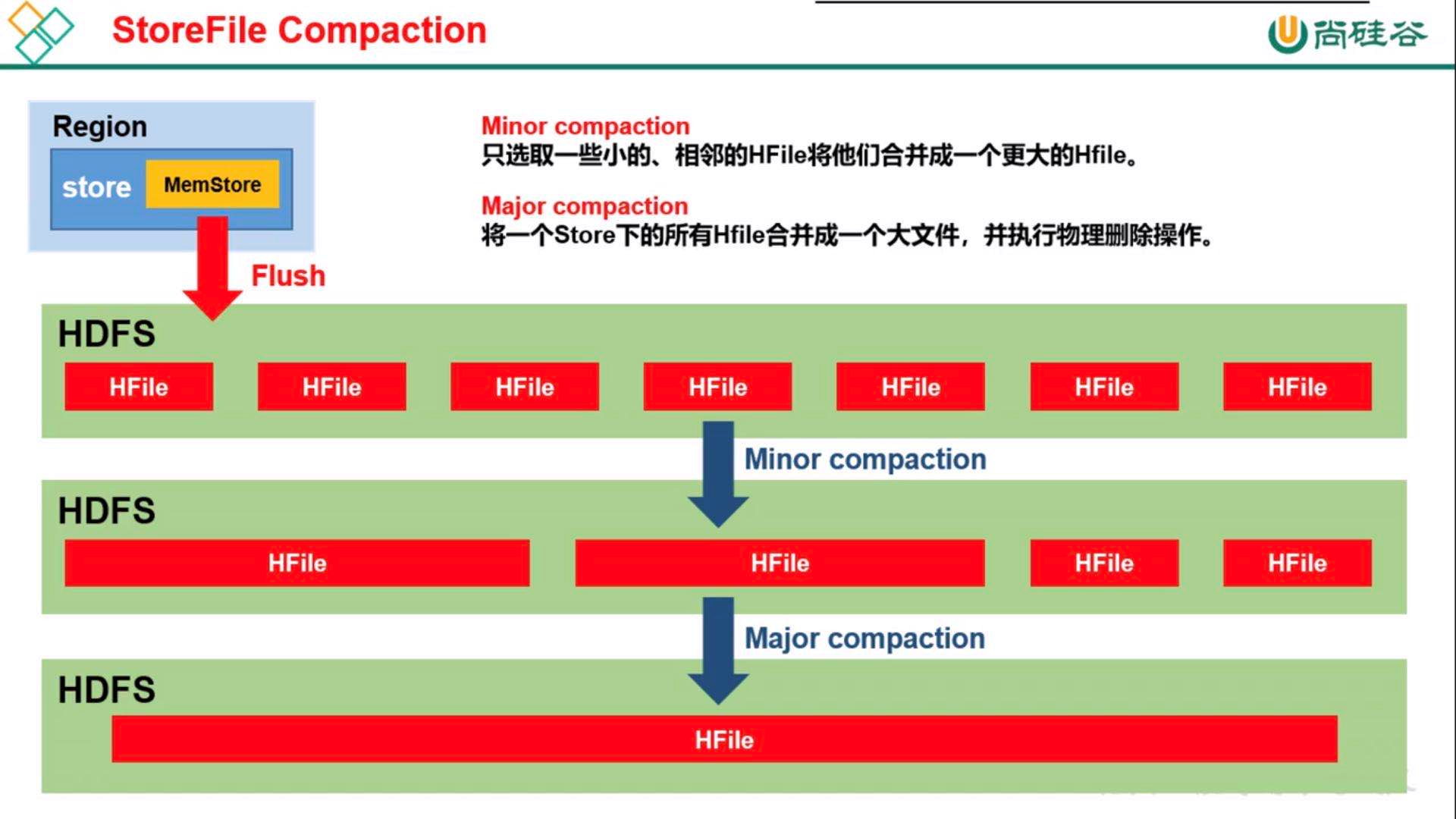
数据真正删除时间:
(1)flush时,如果同一个storeflie进入相同的key,会删除.(但是flush到不同storefile中的相同的key不会删除,他的删除是在compact时)
(2)major compaction时,删除。
Region Split
0.94版本之后的Region,每次split大小就会增大,region中的数据量就会增大,容易导致数据分布不均匀,数据倾斜。(索引引入了预分区)
列簇的设置(不建议使用多个列簇):如果多个列簇中数据量相隔比较大的话,当较大的数据量的列族到达设置值时,会触发全部region flush,就会导致数据量少的列族形成小文件。
Hbase协处理器:
https://www.cnblogs.com/frankdeng/p/9310340.html

