
python爬取图片
希望用python爬取京东手机图片,但是pdb调试发现期望用来保存匹配的图片的列表一直是空
怀疑两个原因:
- 获取到的要匹配关键字的html网页有问题
- 正则表达式没写对
将获取到的要匹配关键字的html的字符串写入txt,以utf-8解码,看看是否能查到浏览器打开html搜索到的关键字

发现str(urllib.request.urlopen.read())这个字符串和浏览器ctrl u看到的html代码不一样
查了一下发现问题:
参考文章:
https://www.cnblogs.com/yuantup/p/9761534.html

这篇文章还提供了一段爬京东手机图片的代码,跑了一下,能跑通
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/10/8 15:11
# @Author : yuantup
# @Site :
# @File : jdshouji_image.py
# @Software: PyCharm
import urllib.request
import re
import os
def open_url(url):
head={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.37'}
# head = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/5'
# '37.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
req = urllib.request.Request(url, headers=head)
response = urllib.request.urlopen(req)
# print(response.getcode())
html = response.read()
return html
def get_img_addr(html):
html_str = html.decode('utf-8')
# print(html_str)
img_addrs =[]
pattern1 = '<img width="220" height="220" data-img="1" src="(.+?[.jpg|.png])"'
pattern2 = '<img width="220" height="220" data-img="1" data-lazy-img="done" title=.+? src="(.+?[.jpg|.png])"'
pattern2 = '<img width="220" height="220" data-img="1" data-lazy-img="(.+?[.jpg|.png])"'
img_addrs1 = re.compile(pattern1).findall(html_str)
# print(img_addrs)
img_addrs2 = re.compile(pattern2).findall(html_str)
# print(len(img_addrs))
img_addrs.extend(img_addrs1)
img_addrs.extend(img_addrs2)
print(img_addrs)
return img_addrs
def save_img(img_addrs):
i = 0
for each in img_addrs:
i = i+1
img_name = each.split("/")[-1]
with open(img_name, 'wb') as f:
correct_url = 'http:' + each
img = open_url(correct_url)
f.write(img)
return i
def main():
path = r'F:/Code/Py/myweb'
a = os.getcwd()
print(a)
if os.path.exists(path):
os.chdir(path)
print(os.getcwd())
else:
os.mkdir(path)
# os.chdir(path)
for i in range(1, 11):
url = 'https://list.jd.com/list.html?cat=9987,653,655&page=' + str(i)
html = open_url(url)
img_addrs = get_img_addr(html)
print(url)
save_img(img_addrs)
if __name__ == '__main__':
main()
观察了一下这段代码是怎么解决html不一致的问题的

主要是上面这一段
所以我尝试用urllib.request.Request(url, headers=head)解决问题,但是首先我需要知道headers
下面这篇博文教给如何看headers:
https://blog.csdn.net/ysblogs/article/details/88530124
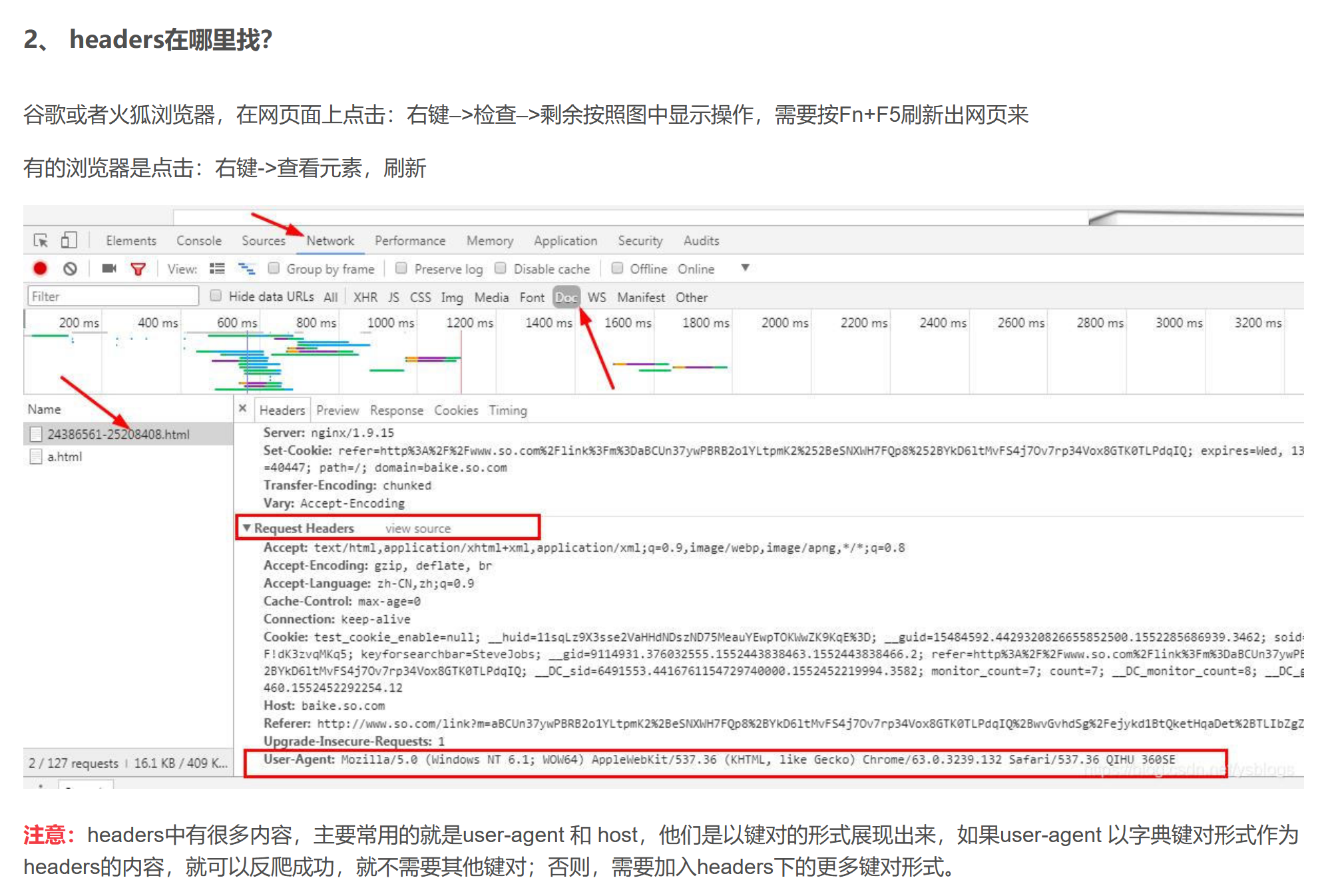
我查看了自己的headers,再修改代码:
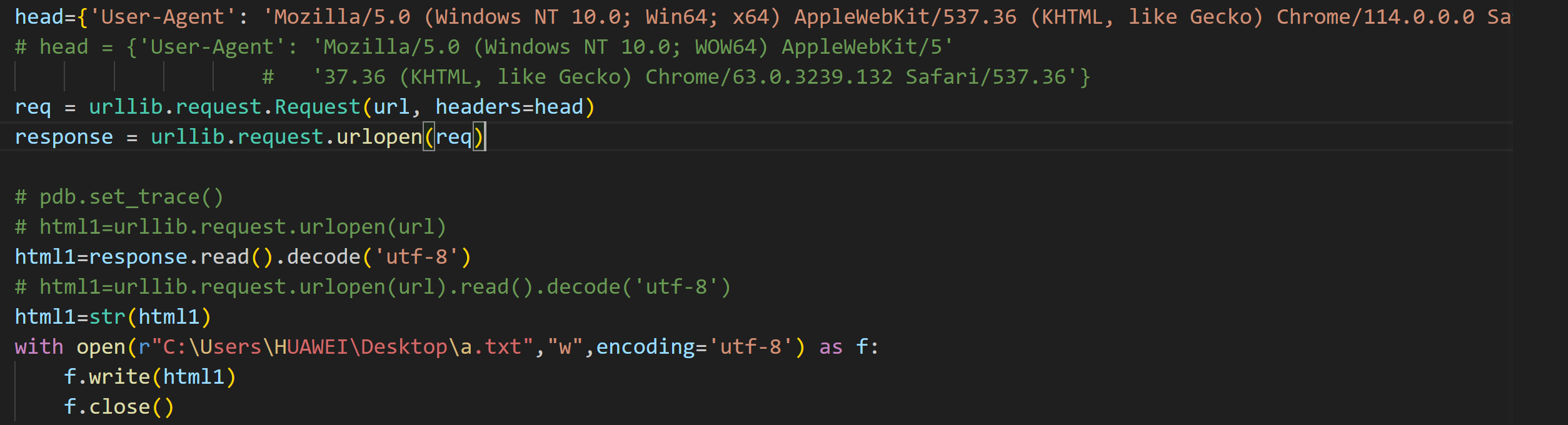
这次能在txt搜索到我在html上搜索到的关键字了
但是发现正则表达式有问题
第一个过滤条件是许多行组成的,因此(?s)能匹配多行

第二个过滤条件也尝试修改,期间,可以尝试把正则表达式匹配的图片路径print()出来,然后直接用搜索引擎搜索图片,看正则表达式匹配的结果路径是否是正确的图片路径
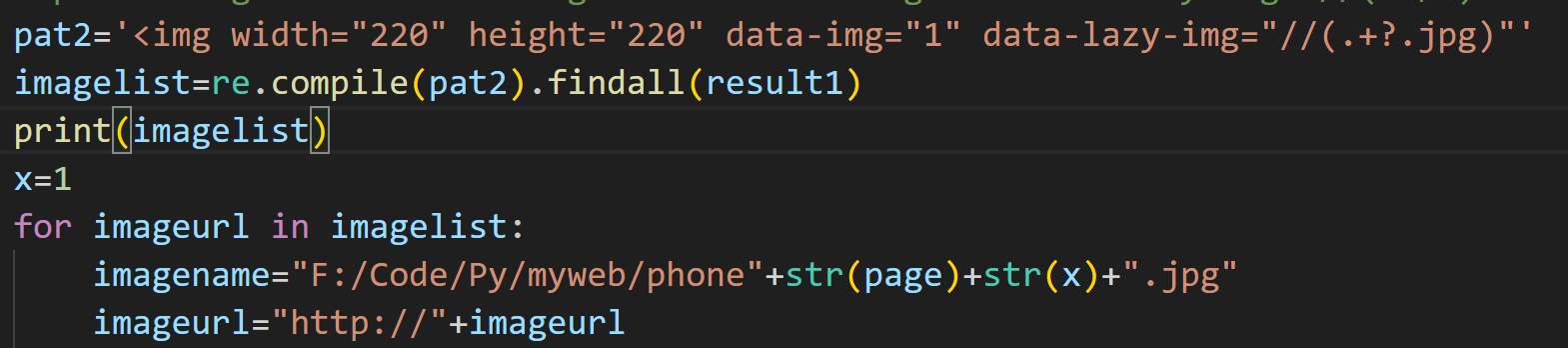
解决了这两个问题以后,能够成功爬取图片了,完整代码如下:
import pdb
import re
import urllib.request
def craw(url,page):
head={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.37'}
req = urllib.request.Request(url, headers=head)
response = urllib.request.urlopen(req)
html1=response.read().decode('utf-8')
html1=str(html1)
with open(r"C:\Users\HUAWEI\Desktop\a.txt","w",encoding='utf-8') as f:
f.write(html1)
f.close()
pat1='(?s)<div id="J_goodsList"(.*)<div class="page clearfix">'
result1=[]
temp1=re.compile(pat1).findall(html1)
result1.extend(temp1)
result1=result1[0]
pat2='<img width="220" height="220" data-img="1" data-lazy-img="//(.+?.jpg)"'
imagelist=re.compile(pat2).findall(result1)
print(imagelist)
x=1
for imageurl in imagelist:
imagename="F:/Code/Py/myweb/phone"+str(page)+str(x)+".jpg"
imageurl="http://"+imageurl
try:
urllib.request.urlretrieve(imageurl,filename=imagename)
except urllib.error.URLError as e:
if hasattr(e,"code"):
x+=1
if hasattr(e,"reason"):
x+=1
x+=1
for i in range(1,10):
url="https://list.jd.com/list.html?cat=9987%2C653%2C655&page="+str(i)
craw(url,i)
参考文章:
https://www.cnblogs.com/yuantup/p/9761534.html
https://blog.csdn.net/ysblogs/article/details/88530124
https://blog.csdn.net/rj2017211811/article/details/89742073

 浙公网安备 33010602011771号
浙公网安备 33010602011771号