
爬虫综合大作业
一、爬取的对象
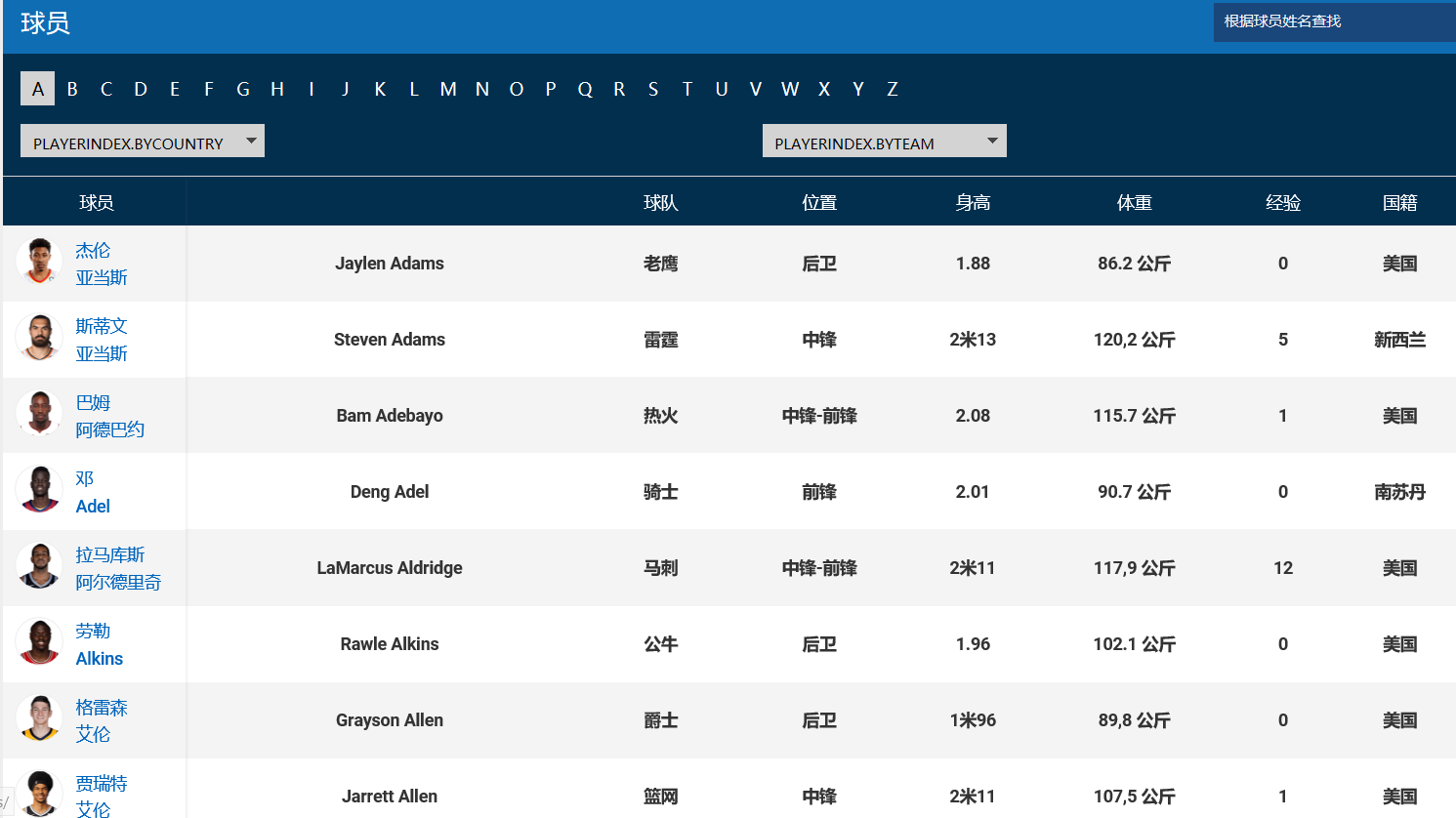
NBA球员基本数据分析
数据来源:NBA中国官网
链接:http://china.nba.com/playerindex/
二、代码如下:
在爬取过程中,只根据html元素来爬取网站数据,只能爬到第一页数据。由于球员的数据是按照名字首字母分页的,在点击其它首字母之后会显示下一页的数据,而且网址并没有发生变化。
因此,需获取JSON数据页面链接:http://china.nba.com/static/data/league/playerlist.json
import requests #用于解析页面文本数据
import pandas as pd
headers = {'User-Agent':user_agent}
url='http://china.nba.com/static/data/league/playerlist.json'
#解析网页
res=requests.get(url,headers=headers).json()
num=int(len(res['payload']['players']))-1 #得到列表r['payload']['players']的长度
p1_cols=[] #用来存放p1数组的列
p2_cols=[] #用来存放p2数组的列
#遍历其中一个['playerProfile'],['teamProfile'] 得到各自列名,添加到p1_cols和p2_cols列表中
for x in res['payload']['players'][0]['playerProfile']:
p1_cols.append(x)
for y in res['payload']['players'][0]['teamProfile']:
p2_cols.append(y)
p1=pd.DataFrame(columns=p1_cols) #初始化一个DataFrame p1 用来存放playerProfile下的数据
p2=pd.DataFrame(columns=p2_cols) #初始化一个DataFrame p1 用来存放playerProfile下的数据
#遍历一次得到一个球员的信息,分别添加到DataFrame数组中
for z in range(num):
player=pd.DataFrame([res['payload']['players'][z]['playerProfile']])
team=pd.DataFrame([res['payload']['players'][z]['teamProfile']])
p1=p1.append(player,ignore_index=True)
p2=p2.append(team,ignore_index=True)
p3=pd.merge(p1,p2,left_index=True,right_index=True) #数据合并
p3.to_csv('d://PyC//4.csv',index=False,encoding='utf_8_sig')
三、保存数据为excel格式
四、数据分析
了解下基本的数据情况
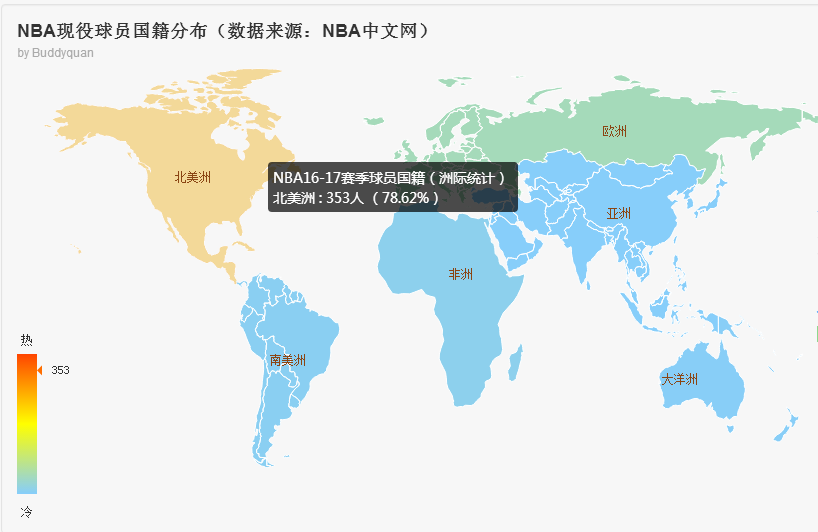
NBA球员国籍'country'的情况


从爬出的数据不难发现,现役nba球员绝大部分是美国人。可想而知,美国本土的篮球文化是多么的浓厚。其中,也有其它国家的球员。那么我们可以从分析的数据中了解下其它国家的球员到底是谁....
西班牙籍球员:

法国籍球员:

原来爵士的内线高塔戈贝尔就是法国球员哦~
再来看下联盟球员球衣号码的数量统计

这样就能轻易知道3号是联盟球员选择最多的号码,那么我们平时在自己球场上看到最多的会是3号吗?
再来看下湖人队的球员资料: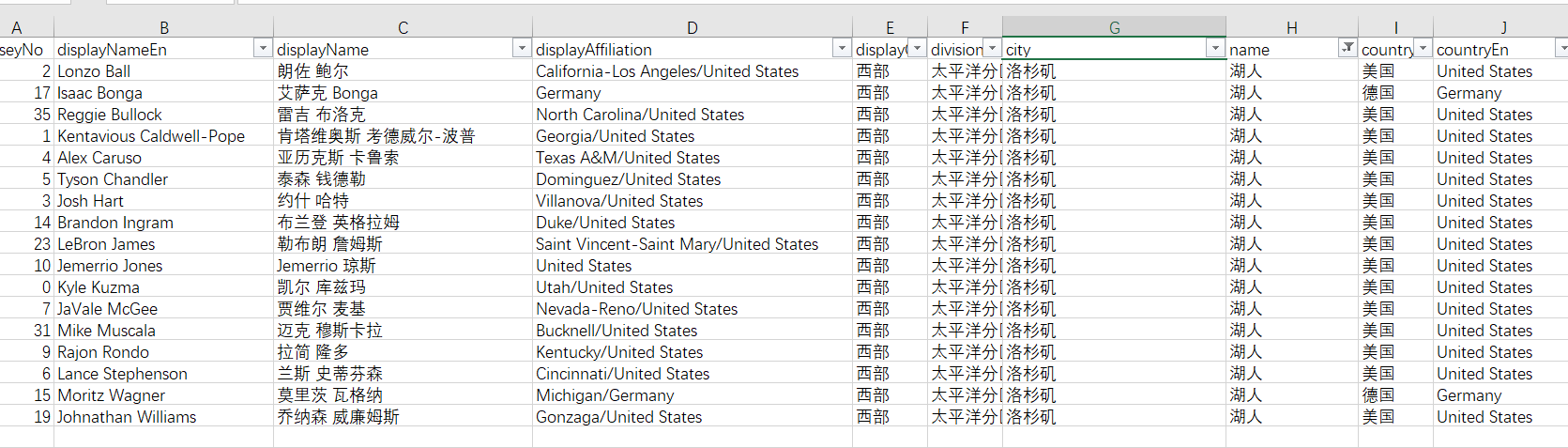
一条有趣的数据,联盟里有五个叫格林的人;其中最近大热的西部半决赛火箭vs勇士,两队都有一个叫格林的球员。那么到时候考验解说能力的时候到了~~


