Day 03
(三 )自动调整学习率
- RMSprop(root mean square prop 算法)
- RMSprop与动量梯度下降法(Momentum)类似,都优化了梯度下降过程中的摆动幅度大的问题。(Momentum:tan90:动量梯度下降法(gradient descent with momentum))
为了进一步优化损失函数在更新中存在摆动幅度过大的问题,并且进一步加快函数的收敛速度,RMSProp算法对权重 W 和偏置 b 的梯度使用了微分平方加权平均数。
- Adam:RMSProp+Momentum(momentum是解决卡在鞍点的,RMSProp是解决梯度学习率不随机调整的问题,这样可能会卡在山谷两边震荡)
Learning Rate Scheduling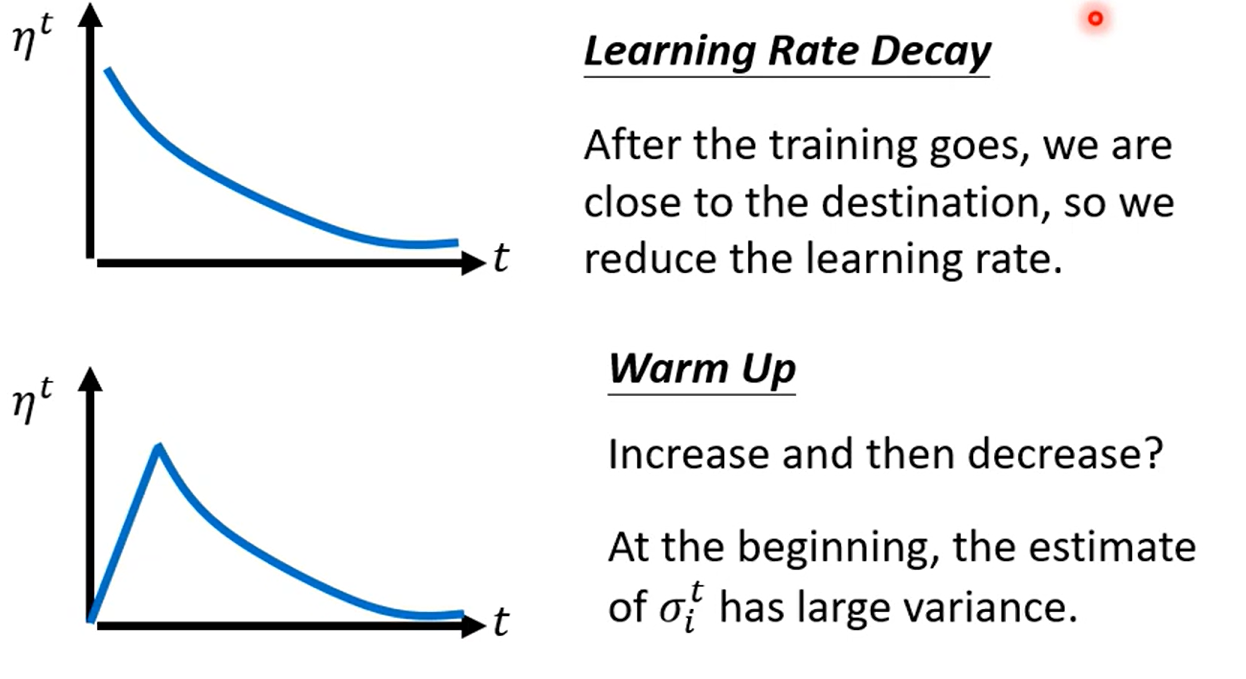
(四)损失函数Loss可能也有影响
- Class as one-hot vector
one-hot vector(独热编码)_目睹闰土刺猹的瓜的博客-CSDN博客 - softmax 将本来y可以放任何值这件事make all values between 0 and 1→理解成变成概率
![]() 每一个yi'都在0和1之间,总和为1
每一个yi'都在0和1之间,总和为1 -
cross entropy(交叉熵)比Mean Square Error更加适合用在分类(classfication)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号