极客时间-左耳听风-程序员攻略-分布式架构经典图书和论文
经典图书
- Distributed Systems for fun and profit,讲述以亚马逊的 Dynamo、谷歌的 Bigtable 和 MapReduce 等为代表的分布式系统背后的核心思想。
- Designing Data Intensive Applications,这本书深入到 B-Tree、SSTables、LSM 这类数据存储结构中,并且从外部的视角来审视这些数据结构对 NoSQL 和关系型数据库的影响。
- Distributed Systems: Principles and Paradigms ,介绍了分布式系统的七大核心原理,并给出了大量的例子;系统讲述了分布式系统的概念和技术,包括通信、进程、命名、同步化、一致性和复制、容错以及安全等;讨论了分布式应用的开发方法(即范型)。但本书不是一本指导“如何做”的手册,仅适合系统性地学习基础知识,了解编写分布式系统的基本原则和逻辑。中文翻译版为《分布式系统原理与范型》(第二版)。
- Scalable Web Architecture and Distributed Systems,
中文翻译版 可扩展的 Web 架构和分布式系统。本书主要针对面向互联网(公网)的分布式系统,作者的观点是,通过了解大型网站的分布式架构原理,小型网站的构建也能从中受益。本书从大型互联网系统的常见特性,如高可用、高性能、高可靠、易管理等出发,引出了一个类似于 Flickr 的典型的大型图片网站的例子。 - Principles of Distributed Systems ,讲述了多种分布式系统中会用到的算法。
经典论文
分布式事务
2009 年的 Google I/O 大会上的演讲《Transaction Across DataCenter》(YouTube 视频)。
在这个演讲中,巴雷特讲述了各种经典的解决方案如何在一致性、事务、性能和错误上做平衡。而最后得到为什么分布式系统的事务只有 Paxos 算法是最好的。
下面这个图是这个算法中的结论。
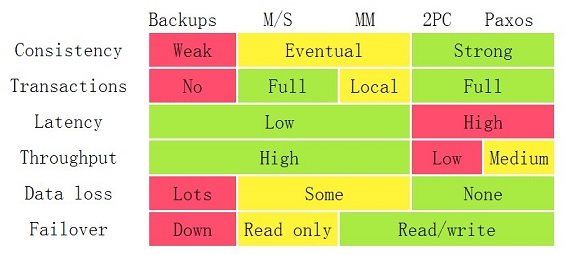
文章《分布式系统的事务处理》。
Paxos 一致性算法
Google 两篇论文。
- Bigtable: A Distributed Storage System for Structured Data
- The Chubby lock service for loosely-coupled distributed systems
Google 与 Bigtable 相齐名的还有另外两篇论文。
Paxos 算法上的细节,Paxos Made Live - An Engineering Perspective 这篇论文详细解释了 Google 实现 Paxos 时遇到的各种问题和解决方案,讲述了从理论到实际应用二者之间巨大的鸿沟。
易读的—— Neat Algorithms - Paxos , Paxos by Examples。
Raft 一致性算法
因为 Paxos 算法太过于晦涩,而且在实际的实现上有太多的坑,并不太容易写对。所以有人搞出了另外一个一致性的算法,叫 Raft。其原始论文是 In search of an Understandable Consensus Algorithm (Extended Version) ,译文在 InfoQ 上,题为《Raft 一致性算法论文译文》。
Raft 算法的动画演示。
- Raft - The Secret Lives of Data
- Raft Consensus Algorithm
- Raft Distributed Consensus Algorithm Visualization
Gossip 一致性算法
Amazon 的 DynamoDB,其论文Dynamo: Amazon’s Highly Available Key Value Store 的影响力非常大。这篇论文中讲述了 Amazon 的 DynamoDB 是如何满足系统的高可用、高扩展和高可靠的。其中展示了系统架构是如何做到数据分布以及数据一致性的。GFS 采用的是查表式的数据分布,而 DynamoDB 采用的是计算式的,也是一个改进版的通过虚拟结点减少增加结点带来数据迁移的一致性哈希。
这篇文章中有几个关键的概念,一个是 Vector Clock,另一个是 Gossip 协议。
- Time, Clocks and the Ordering of Events in a Distributed System ,这篇文章是莱斯利·兰伯特(Leslie Lamport)于 1978 年发表的,并在 2007 年被选入 SOSP 的名人堂,被誉为第一篇真正的“分布式系统”论文,该论文曾一度成为计算机科学史上被引用最多的文章。分布式系统中的时钟同步是一个非常难的问题,因为分布式系统中是使用消息进行通信的,若使用物理时钟来进行同步,一方面是不同的 process 的时钟有差异,另一方面是时间的计算也有一定的误差,这样若有两个时间相同的事件,则无法区分它们谁前谁后了。这篇文章主要解决分布式系统中的时钟同步问题。
- 马萨诸塞大学课程 Distributed Operating System 中第 10 节 Clock Synchronization,这篇讲义讲述了时钟同步的问题。
- 关于 Vector Clock, Why Vector Clocks are Easy](http://basho.com/posts/technical/why-vector-clocks-are-easy/) 和 Why Vector Clocks are Hard 。
用来做数据同步的 Gossip 协议的原始论文是 Efficient Reconciliation and Flow Control for Anti-Entropy Protocols。Gossip 算法也是 Cassandra 使用的数据复制协议。
Gossip 协议也是 NoSQL 数据库 Cassandra 中使用到的数据协议: Understanding Gossip (Cassandra Internals)。
关于 Gossip 的一些图示化的东西, Gossip Visualization。
分布式存储和数据库
Amazon 的 DynamoDB 的论文。
- 一篇是 AWS Aurora 的论文 Amazon Aurora: Design Considerations for High Throughput Cloud -Native Relation Databases。
- 另一篇是比较有代表的论文是 Google 的 Spanner: Google’s Globally-Distributed Database。 其 2017 年的新版论文:Spanner, TrueTime & The CAP Theorem。
- F1 - The Fault-Tolerant Distributed RDBMS Supporting Google’s Ad Business 。
- Cassandra: A Decentralized Structured Storage System 。
- CRUSH: Controlled, Scalable, Decentralized Placement of Replicated Data, 这里提到的算法被应用在了 Ceph 分布式文件系统中,其架构可以读一下 RADOS - A Scalable, Reliable Storage Service for Petabyte-scale
Storage Clusters 以及 Ceph 的架构文档。
分布式消息系统
- 分布式消息系统, Kafka: a Distributed Messaging System for Log Processing。
- Wormhole: Reliable Pub-Sub to Support Geo-replicated Internet Services ,Wormhole 是 Facebook 内部使用的一个 Pub-Sub 系统,目前还没有开源。它和 Kafka 之类的消息中间件很类似。但是它又不像其它的 Pub-Sub 系统,Wormhole 没有自己的存储来保存消息,它也不需要数据源在原有的更新路径上去插入一个操作来发送消息,是非侵入式的。其直接部署在数据源的机器上并直接扫描数据源的 transaction logs,这样还带来一个好处,Wormhole 本身不需要做任何地域复制(geo-replication)策略,只需要依赖于数据源的 geo-replication 策略即可。
- All Aboard the Databus! LinkedIn’s Scalable Consistent Change Data Capture Platform , 在 LinkedIn 投稿 SOCC 2012 的这篇论文中,指出支持对不同数据源的抽取,允许不同数据源抽取器的开发和接入,只需该抽取器遵循设计规范即可。该规范的一个重要方面就是每个数据变化都必须被一个单调递增的数字标注(SCN),用于同步。这其中的一些方法完全可以用做异地双活的系统架构中。(和这篇论文相关的几个链接如下:PDF 论文 、 PPT 分享。)
日志和数据
- The Log: What every software engineer should know about real-time data’s unifying abstraction ,中译版《日志:每个软件工程师都应该知道的有关实时数据的统一概念》。
- The Log-Structured Merge-Tree (LSM-Tree) ,N 多年前,谷歌发表了 Bigtable 的论文,论文中很多很酷的方面,其一就是它所使用的文件组织方式,这个方法更一般的名字叫 Log Structured-Merge Tree。LSM 是当前被用在许多产品的文件结构策略:HBase、Cassandra、LevelDB、SQLite,甚至在 MongoDB 3.0 中也带了一个可选的 LSM 引擎(Wired Tiger 实现的)。LSM 有趣的地方是它抛弃了大多数数据库所使用的传统文件组织方法。(中文社区文章:文章一、文章二。)
- Immutability Changes Everything ,这篇论文是现任 Salesforce 软件架构师帕特·赫兰德(Pat Helland)在 CIDR 2015 大会上发表的(相关视频演讲)。
- Tango: Distributed Data Structures over a Shared Log)。这个论文非常经典,其中说明了不可变性(immutability)架构设计的优点。Tango 为开发人员提供了一个由共享日志支持的内存复制数据结构(例如地图或树)的抽象。Tango 对象易于构建和使用,通过共享日志上简单的追加和读取操作来复制状态,而不是复杂的分布式协议。在这个过程中,它们从共享日志中获得诸如线性化、持久性和高可用性等属性。Tango 还利用共享日志支持跨不同对象的快速事务处理,允许应用程序跨机器进行状态划分,并在不牺牲一致性的情况下扩展到底层日志的上限。
分布式监控和跟踪
- Google 的分布式跟踪监控论文 - Dapper, a Large-Scale Distributed Systems Tracing Infrastructure, 其开源实现有三个 Zipkin、Pinpoint 和 HTrace。
数据分析
- The Unified Logging Infrastructure for Data Analytics at Twitter ,Twitter 公司的一篇关于日志架构和数据分析的论文。
- Scaling Big Data Mining Infrastructure: The Twitter Experience ,讲 Twitter 公司的数据分析平台在数据量越来越大,架构越来越复杂,业务需求越来越多的情况下,数据分析从头到底是怎么做的。
- Dremel: Interactive Analysis of Web-Scale Datasets,Google 公司的 Dremel,是一个针对临时查询提供服务的系统,它处理的是只读的多层数据。本篇文章介绍了它的架构与实现,以及它与 MapReduce 是如何互补的。
- Resident Distributed Datasets: a Fault-Tolerant Abstraction for In-Memory Cluster Computing,这篇论文提出了弹性分布式数据集(Resilient Distributed Dataset,RDD)的概念,它是一个分布式存储抽象,使得程序员可以在大型集群上以容错的方式执行内存计算;解释了其出现原因:解决之前计算框架在迭代算法和交互式数据挖掘工具两种应用场景下处理效率低下的问题,并指出将数据保存在内存中,可以将性能提高一个数量级;同时阐述了其实现原理及应用场景等多方面内容。
与编程相关的论文
- Distributed Programming Model
- PSync: a partially synchronous language for fault-tolerant distributed algorithms
- Programming Models for Distributed Computing
- Logic and Lattices for Distributed Programming
其它的分布式论文阅读列表
不错的分布式系统论文的阅读列表。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号