如何在 Ubuntu 14.04 上安装 Elasticsearch,Logstash 和 Kibana
 on Ubuntu 14.04")
介绍
在本教程中,我们将去的 Elasticsearch 麋鹿堆栈安装 Ubuntu 14.04 — — 那就是,Elasticsearch 5.2.x,Logstash 2.2.x 和 Kibana 4.4.x。我们也将向你展示如何将其配置为收集和可视化系统日志转移您的系统在一个集中的位置,使用 Filebeat 1.1.x.Logstash 是收集、 分析和存储日志供将来使用开源工具。Kibana 是一个 web 界面,可用于搜索和查看 Logstash 已索引的日志。这两种工具都基于 Elasticsearch,用于存储日志。
集中的日志记录可以非常有用,当试图确定问题与您的服务器或应用程序,因为它允许您所有您在一个地方的日志中进行搜索。它也是有用的因为它允许您确定通过关联及其日志在特定的时间内跨越多个服务器的问题。
它是可以使用 Logstash 来收集日志的所有类型,但我们将限制到 syslog 收集本教程的范围。
我们的目标
本教程的目标是建立 Logstash 收集系统日志转移的多个服务器,并设置 Kibana 可视化收集的日志。
我们的麋鹿堆栈设置具有四个主要组件︰
- Logstash: Logstash 处理传入日志的服务器组件
- Elasticsearch︰ 存储所有的日志
- Kibana︰ 用于搜索和可视化日志,将可通过 Nginx 代理 Web 接口
- Filebeat︰ 安装在客户端将向服务器发送服务器及其日志 Logstash,Filebeat 作为利用伐木工人网络协议与 Logstash 进行通信的日志传送代理
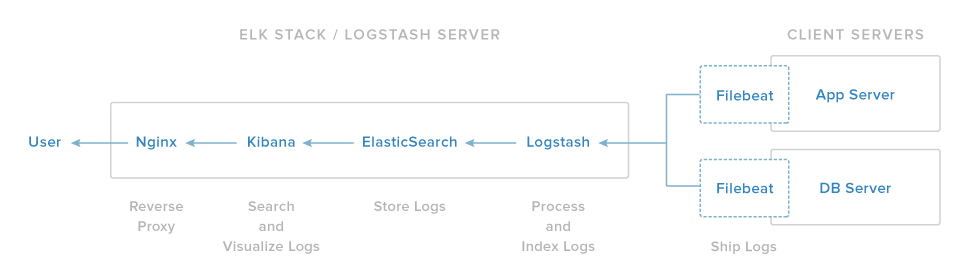
我们将在一个单一的服务器,我们将我们的麋鹿服务器称为上安装的第三个组成部分。Filebeat 将在所有客户端服务器,我们想要收集日志,我们将集体称为我们的客户端服务器上安装。
系统必备组件
若要完成本教程,您将需要 Ubuntu 14.04 VPS 根访问。设置了才能发现这里 (步骤 3 和 4) 的说明︰ Ubuntu 14.04 初始服务器安装程序。
如果您愿意使用 CentOS 的相反,查阅本教程︰如何对安装麋鹿在 CentOS 7 上。
CPU、 RAM 和你麋鹿服务器将需要的存储量取决于你打算收集的日志量。在本教程中,我们将使用一个 VPS 与以下规格为我们麋鹿服务器︰
- OS: Ubuntu 14.04
- 内存︰ 4 GB
- CPU: 2
除了您麋鹿的服务器,你会想要几个其他服务器从您将收集日志。
我们建立我们的麋鹿服务器开始吧 !
安装 Java
首先,你将需要 Java 运行时环境 (JRE) 上你滴,因为 Elasticsearch 在 Java 编程语言编写。Elasticsearch 需要 Java 7 或更高。Elasticsearch 建议 Oracle JDK 版本 1.8.0_73,但本机的 Ubuntu OpenJDK 本机包为 JRE 行之有效。
此步骤显示了如何安装这两个版本,所以你可以决定哪些是最适合你。
安装 OpenJDK
JRE 的本机 Ubuntu OpenJDK 本机包是免费的、 好的支持,通过 Ubuntu APT 安装管理器自动托管的。
在安装之前 OpenJDK apt,更新列表中可用的软件包安装在你的 Ubuntu Droplet 通过运行命令︰
- sudo apt-get update
在那之后,你可以安装 OpenJDK 的命令︰
- sudo apt-get install openjdk-7-jre
若要验证您的 JRE 安装并可以使用,请运行命令︰
- java -version
结果应如下所示︰
java version "1.7.0_79"
OpenJDK Runtime Environment (IcedTea 2.5.6) (7u79-2.5.6-0ubuntu1.14.04.1)
OpenJDK 64-Bit Server VM (build 24.79-b02, mixed mode)
安装 Java 8
当你提前在使用 Elasticsearch,你开始寻找更好的 Java 性能和兼容性时,您可以选择安装 Oracle 的专有 Java (Oracle JDK 8)。
将 Oracle Java PPA 添加到易︰
- sudo add-apt-repository -y ppa:webupd8team/java
更新您的 apt 软件包数据库︰
- sudo apt-get update
用此命令安装最新的稳定版本的 Oracle Java 8 (并接受弹出许可协议)︰
- sudo apt-get -y install oracle-java8-installer
最后,验证它安装了︰
- java -version
下载并安装 Elasticsearch
Elasticsearch 可以直接从elastic.co在 zip、 tar.gz、 deb 或 rpm 包下载。它为 Ubuntu,最好使用 deb (Debian) 程序包,它将安装一切您需要运行 Elasticsearch。
在撰写本文时,最新的 Elasticsearch 版本是 5.3.2。下载您选择的命令的目录中︰
- wget https://download.elastic.co/elasticsearch/elasticsearch/elasticsearch-5.3.2.deb
然后将其安装在 Ubuntu 如常与所示的命令︰dpkg
- sudo dpkg -i elasticsearch-5.3.2.deb
提示︰如果你想要最新的发布的版本的 Elasticsearch,去elastic.co可以找到那链接,然后使用wget下载到您的液滴。一定要下载 deb 包。
这会导致的 Elasticsearch 正在安装使用其配置文件放在和中添加其 init 脚本。/usr/share/elasticsearch//etc/elasticsearch/etc/init.d/elasticsearch
若要确保 Elasticsearch 启动和自动停止与液滴,请将其 init 脚本添加到默认运行级别的命令︰
- sudo update-rc.d elasticsearch defaults
配置Elastic
既然已安装了 Elasticsearch 和其 Java 依赖关系,它是配置 Elasticsearch 的时间。
Elasticsearch 配置文件是在目录中。有两个文件︰/etc/elasticsearch
-
elasticsearch.yml— — 配置 Elasticsearch 服务器设置。这是除那些日志记录,为所有选项的都存储位置,这就是为什么我们最感此文件中。 -
logging.yml— — 为提供配置日志记录。在开始的时候,你不需要编辑此文件。您可以保留所有默认日志记录选项。默认情况下,可以发现所产生的日志中。/var/log/elasticsearch
若要自定义在任何 Elasticsearch 服务器是和第一个变量。正如其名称所示,指定的服务器 (节点) 和群集,后者是相关联的名称。node.namecluster.nameelasticsearch.ymlnode.name
如果你不自定义这些变量,将会自动分配方面对液滴的主机名。将自动设置为默认群集的名称。node.namecluster.name
值是由用于自动发现功能的 Elasticsearch 自动发现和关联 Elasticsearch 节点到群集。因此,如果你不改变默认值,你可能需要找到在同一网络上,群集中的节点。cluster.name
开始编辑主配置文件︰elasticsearch.yml
- sudo nano /etc/elasticsearch/elasticsearch.yml
删除字符开头的行,并取消注释,,然后更改它们的值。文件中的第一个配置更改应如下所示︰#node.namecluster.name/etc/elasticsearch/elasticsearch.yml
...
node.name: "My First Node"
cluster.name: mycluster1
...
另一项重要的设定是服务器,可以是"大师"或"奴隶"的角色。"大师"是负责集群健康和稳定。在大型部署的群集节点很多,它已建议有多个专用"大师"。通常情况下,专用的"大师"将不存储数据,或创建索引。因此,应当没有机会被重载,其中集群健康可能受到威胁。
"奴隶"作为"主力"可以装载数据的任务。即使重载"奴隶"节点,群集健康不该受到严重影响,提供有其他节点采取额外的负荷。
被称为设置用于确定服务器的角色。如果你有一个 Elasticsearch 节点,你应该离开这选项注释掉,以便保持其默认值 — — 即唯一的节点应该也是一位大师。或者,如果您想要配置的节点作为一个奴隶,移除字符开头的行,并将该值更改为︰node.mastertrue#node.masterfalse
...
node.master: false
...
另一个重要的配置选项,则决定了节点会将存储的数据。在大多数情况下此选项应该留给其默认值 (),但有两种情况,你可能不想将数据存储在一个节点上。正如我们已经提到,一个是当节点是专用的"大师"。另一个是在一个节点仅用于从节点获取数据并将结果聚合时。在后者的情况下节点会出毛病"搜索负载平衡器"。node.datatrue
再次,如果你有一个 Elasticsearch 节点,你应该离开中国此设置注释掉,以便保持默认值。否则为若要禁用本地存储数据,取消注释以下行,并将该值更改为︰truefalse
...
node.data: false
...
其他两个重要的选项是和。第一个确定成多少块 (碎片) 的索引将被分成。第二个定义将分布在群集的副本的数量。有更多的碎片,提高索引的性能,同时有更多的副本,搜索速度更快。index.number_of_shardsindex.number_of_replicas
假设你仍在探索和在单个节点上测试 Elasticsearch,它是更好的开始只有一个碎片和没有副本。因此,应将它们的值设置为以下 (请确保移除在直线的起点):#
...
index.number_of_shards: 1
index.number_of_replicas: 0
...
一个最后的设置,你可能会感兴趣变化是,这决定了数据的存储位置的路径。默认路径是。在生产环境中它被建议你用于存储 Elasticsearch 数据使用一个专用的分区和装载点。在最好的情况下,此专用的分区将会提供更好的性能和数据隔离单独的存储媒体。取消注释行并改变其值,可以指定一个不同的路径︰path.data/var/lib/elasticsearchpath.datapath.data
...
path.data: /media/different_media
...
一旦你做的所有更改,请保存并退出该文件。现在你可以开始 Elasticsearch 第一次使用命令︰
- sudo service elasticsearch start
请等待至少 10 秒钟以便 Elasticsearch 完全启动之前,您将能够使用它。否则,你可能得到一个关于不能够连接错误。
确保弹性
Elasticsearch 没有内置的安全性和可控制的人可以访问 HTTP API。这一节不是保护 Elasticsearch 的综合指南。采取一切措施防止未经授权的访问到它和它正在其运行的服务器/虚拟机所需。考虑使用iptables来进一步保护您的系统。
第一次的安全调整是防止公共访问。要删除公共访问编辑文件︰elasticsearch.yml
- sudo nano /etc/elasticsearch/elasticsearch.yml
找到包含的行注释它通过删除的字符开头的行,并将该值更改为所以它看起来像这样︰network.bind_host#localhost
...
network.bind_host: localhost
...
警告︰因为 Elasticsearch 没有任何内置的安全机制,它是非常重要的你不要设置这是你不控制或不信任的任何服务器可以访问的任何 IP 地址。不要到公共或共享的专用网络的 IP 地址绑定 Elasticsearch !
而且,为额外的安全性,您可以禁用动态脚本,用来计算自定义表达式。通过手工创建自定义的恶意言论,攻击者可能能够破坏您的环境。
若要禁用自定义表达式,添加下面的行是在文件的末尾︰/etc/elasticsearch/elasticsearch.yml
...
script.disable_dynamic: true
...
测试
到目前为止,应该在 9200 端口上运行 Elasticsearch。您可以测试它与卷曲,命令行客户端 URL 传输工具和一个简单的 GET 请求像这样︰
- curl -X GET 'http://localhost:9200'
您应看到以下的响应︰
{
"status" : 200,
"name" : "Harry Leland",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "5.3.2",
"build_hash" : "e43676b1385b8125d647f593f7202acbd816e8ec",
"build_timestamp" : "2015-09-14T09:49:53Z",
"build_snapshot" : false,
"lucene_version" : "4.10.4"
},
"tagline" : "You Know, for Search"
}
如果你看到类似上面的一个响应,Elasticsearch 工作正常。如果没有,请确保您已正确地按照安装说明进行安装和您已允许 Elasticsearch 完全开始一段时间。
使用 Elasticsearch
要开始使用 Elasticsearch,让我们先添加一些数据。正如前文所述,Elasticsearch 使用基于 Rest 的 API,响应通常的 CRUD 命令︰ 创建、 读取、 更新和删除。它的工作,我们会再次使用卷曲。
您可以添加您的命令的第一个条目︰
- curl -X POST 'http://localhost:9200/tutorial/helloworld/1' -d '{ "message": "Hello World!" }'
您应看到以下的响应︰
{"_index":"tutorial","_type":"helloworld","_id":"1","_version":1,"created":true}
与卷曲,我们有到 Elasticseach 服务器发送一个 HTTP POST 请求。请求的 URI 是。它是重要的是理解这里的参数︰/tutorial/helloworld/1
tutorial是 Elasticsearch 中的数据的索引。helloworld是的类型。1是的我们条目下的上述指标和类型的标识符。
您可以检索 HTTP GET 请求,这样这第一项︰
- curl -X GET 'http://localhost:9200/tutorial/helloworld/1'
结果应该看起来像︰
{"_index":"tutorial","_type":"helloworld","_id":"1","_version":1,"found":true,"_source":{ "message": "Hello World!" }}
若要修改现有的条目,您可以使用 HTTP 请求像这样︰
- curl -X PUT 'localhost:9200/tutorial/helloworld/1?pretty' -d '
- {
- "message": "Hello People!"
- }'
Elasticsearch 应该承认这样的成功修改︰
{
"_index" : "tutorial",
"_type" : "helloworld",
"_id" : "1",
"_version" : 2,
"created" : false
}
在上面的例子我们已修改的第一个条目于民"你好 !"。这一点,版本号码会自动增加到。message2
你可能已经注意到在上述请求中的额外参数。它使人类可读的格式,以便您可以在一个新行上编写每个数据字段。你也可以"美化"你的结果中检索数据时和得到这样多更好的输出︰pretty
- curl -X GET 'http://localhost:9200/tutorial/helloworld/1?pretty'
现在的响应将是在更好的格式︰
{
"_index" : "tutorial",
"_type" : "helloworld",
"_id" : "1",
"_version" : 2,
"found" : true,
"_source":{ "message": "Hello World!" }
}
到目前为止我们已经添加到和查询 Elasticsearch 中的数据。为了了解其它操作请检查API 文档。
安装 Kibana
Kibana 可以安装程序包管理器通过增加弹性的软件包源列表。
创建 Kibana 源列表︰
- echo "deb http://packages.elastic.co/kibana/4.4/debian stable main" | sudo tee -a /etc/apt/sources.list.d/kibana-4.4.x.list
更新您的 apt 软件包数据库︰
- sudo apt-get update
用此命令安装 Kibana:
- sudo apt-get -y install kibana
现在安装 Kibana。
打开 Kibana 配置文件进行编辑︰
- sudo vi /opt/kibana/config/kibana.yml
在 Kibana 配置文件中,找到的行的指定,并将 IP 地址 (默认情况下的"0.0.0.0") 替换"localhost":server.host
server.host: "localhost"
保存并退出。此设置使 Kibana 将只能访问本地主机。这是好的因为我们将使用 Nginx 反向代理服务器以允许外部访问。
现在启用 Kibana 服务,并启动它︰
- sudo update-rc.d kibana defaults 96 9
- sudo service kibana start
我们可以使用 Kibana web 界面之前,我们必须建立一个反向代理。现在开始吧,与 Nginx。
安装 Nginx
因为我们配置 Kibana 侦听,我们必须设置反向代理服务器以允许外部访问它。为此目的,我们将使用 Nginx。localhost
注︰如果你已经有你想要使用 Nginx 实例,随意使用,相反。只是一定要配置 Kibana,所以它是由你 (你可能想要更改的值,在对您的 Kibana 服务器专用的 IP 地址或主机名) 的 Nginx 服务器到达。此外,建议您启用 SSL/TLS。host/opt/kibana/config/kibana.yml
使用容易安装 Nginx 和 Apache2 utils:
- sudo apt-get install nginx apache2-utils
使用 htpasswd 创建管理员用户,被称为"kibanaadmin"(你应该使用另一个名称),可以访问 Kibana web 界面︰
- sudo htpasswd -c /etc/nginx/htpasswd.users kibanaadmin
输入一个密码提示符。因为你需要它来访问 Kibana web 界面,请记住此登录。
现在在你最喜欢的编辑器中打开 Nginx 默认服务器块。我们将使用 vi:
- sudo vi /etc/nginx/sites-available/default
删除该文件的内容,并将下面的代码块粘贴到该文件。一定要更新以匹配您的服务器的名称︰server_name
- server {
- listen 80;
- server_name example.com;
- auth_basic "Restricted Access";
- auth_basic_user_file /etc/nginx/htpasswd.users;
- location / {
- proxy_pass http://localhost:5601;
- proxy_http_version 1.1;
- proxy_set_header Upgrade $http_upgrade;
- proxy_set_header Connection 'upgrade';
- proxy_set_header Host $host;
- proxy_cache_bypass $http_upgrade;
- }
- }
保存并退出。这配置 Nginx 将您的服务器的 HTTP 流量引导到 Kibana 的应用程序正在侦听。此外,Nginx 将使用我们刚才创建的文件,并且需要基本身份验证。localhost:5601htpasswd.users
现在重新启动 Nginx 使我们更改生效︰
- sudo service nginx restart
现在可以通过你的 FQDN 或麋鹿服务器即http://elk \_server\_public\_ip/的公共 IP 地址访问 Kibana。如果你去那里在 web 浏览器中之后输入"kibanaadmin"的凭据,, 您应该看到 Kibana 欢迎页面,将要求您配置索引模式。让我们回到那晚,我们安装的所有其他组件后。
安装 Logstash
Logstash 包是从同一存储库中可用,如 Elasticsearch,和我们已经安装了该公钥,因此,让我们共创 Logstash 源列表︰
- echo 'deb http://packages.elastic.co/logstash/2.2/debian stable main' | sudo tee /etc/apt/sources.list.d/logstash-2.2.x.list
更新您的 apt 软件包数据库︰
- sudo apt-get update
用此命令安装 Logstash:
- sudo apt-get install logstash
Logstash 已安装但尚未配置。
生成 SSL 证书
因为我们要使用 Filebeat 将从我们的客户端服务器的日志传送到我们的麋鹿服务器,我们需要创建一个 SSL 证书和密钥对。该证书用 Filebeat 来验证麋鹿服务器的身份。创建目录将存储的证书和私钥使用以下命令︰
- sudo mkdir -p /etc/pki/tls/certs
- sudo mkdir /etc/pki/tls/private
现在你有两个选项来生成您的 SSL 证书。如果你有将允许您的客户端服务器解析麋鹿服务器的 IP 地址的 DNS 设置,请使用选项 2。否则,选项 1将允许您使用的 IP 地址。
选项 1: IP 地址
如果你没有一个 DNS 设置 — — 这将使您的服务器,您将收集过程中的日志,来解决您的麋鹿服务器的 IP 地址 — — 您将不得不将你麋鹿服务器专用的 IP 地址添加到我们将要生成的 SSL 证书 (SAN) 字段。若要这样做,请打开 OpenSSL 配置文件︰subjectAltName
- sudo vi /etc/ssl/openssl.cnf
在文件中,找到的部分并添加此线下它 (代以麋鹿服务器专用的 IP 地址)︰[ v3_ca ]
subjectAltName = IP: ELK_server_private_IP
保存并退出。
现在生成 SSL 证书和私钥,在适当的位置 (/等/pki/tls/),使用以下命令︰
- cd /etc/pki/tls
- sudo openssl req -config /etc/ssl/openssl.cnf -x509 -days 3650 -batch -nodes -newkey rsa:2048 -keyout private/logstash-forwarder.key -out certs/logstash-forwarder.crt
Logstash forwarder.crt文件将被复制到所有服务器将发送到 Logstash 的日志,但我们会晚一点这样做。让我们完成我们的 Logstash 配置。如果你去使用此选项,跳过选项 2 和移动到配置的 Logstash。
选项 2: FQDN (DNS)
如果你有一个 DNS 设置与您的专用网络,则应创建包含麋鹿服务器私有 IP 地址的 A 记录 — — 此域的名称将用于在下一个命令中,生成 SSL 证书。或者,您可以使用指向服务器的公共 IP 地址的记录。只是确保您的服务器 (那些你将收集日志从) 将能够将域名解析到你麋鹿服务器。
现在生成 SSL 证书和私钥,在适当的位置 (等/pki/tls /......),用下面的命令 (在服务器的 FQDN,麋鹿代替)︰
- cd /etc/pki/tls; sudo openssl req -subj '/CN=ELK_server_fqdn/' -x509 -days 3650 -batch -nodes -newkey rsa:2048 -keyout private/logstash-forwarder.key -out certs/logstash-forwarder.crt
Logstash forwarder.crt文件将被复制到所有服务器将发送到 Logstash 的日志,但我们会晚一点这样做。让我们完成我们的 Logstash 配置。
配置 Logstash
Logstash 配置文件以 JSON 格式,并驻留在 /etc/logstash/conf.d 中。配置由三部分组成︰ 输入、 筛选器和输出。
让我们创建一个配置文件,称为和建立了我们的"filebeat"输入︰02-beats-input.conf
- sudo vi /etc/logstash/conf.d/02-beats-input.conf
插入下列输入配置︰
- input {
- beats {
- port => 5044
- ssl => true
- ssl_certificate => "/etc/pki/tls/certs/logstash-forwarder.crt"
- ssl_key => "/etc/pki/tls/private/logstash-forwarder.key"
- }
- }
保存并退出。此参数指定将侦听 tcp 端口的输入,它将使用的 SSL 证书和我们先前创建的私有密钥。beats5044
现在让我们创建一个配置文件,称为,在那里我们将添加一个筛选器的系统日志消息︰10-syslog-filter.conf
- sudo vi /etc/logstash/conf.d/10-syslog-filter.conf
插入下面的 syslog筛选器配置︰
- filter {
- if [type] == "syslog" {
- grok {
- match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" }
- add_field => [ "received_at", "%{@timestamp}" ]
- add_field => [ "received_from", "%{host}" ]
- }
- syslog_pri { }
- date {
- match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
- }
- }
- }
保存并退出。此过滤器会查找日志上都标记为"系统日志"类型 (通过 Filebeat),和它将尝试使用解析传入的 syslog 日志,使其结构和查询能力。grok
最后,我们将创建一个名为配置文件︰30-elasticsearch-output.conf
- sudo vi /etc/logstash/conf.d/30-elasticsearch-output.conf
插入下面的输出配置︰
- output {
- elasticsearch {
- hosts => ["localhost:9200"]
- sniffing => true
- manage_template => false
- index => "%{[@metadata][beat]}-%{+YYYY.MM.dd}"
- document_type => "%{[@metadata][type]}"
- }
- }
保存并退出。此输出基本上配置 Logstash 来存储正在运行时,索引使用的节拍的名字命名 (在本例中为 filebeat) 中的 Elasticsearch 中的节拍数据。localhost:9200
如果你想要添加的其他应用程序使用的 Filebeat 输入筛选器,请务必命名文件,所以他们之间的输入和输出配置 (即至 02-30-) 进行排序。
测试您的 Logstash 配置使用此命令︰
- sudo service logstash configtest
它应该显示如果没有语法错误。否则为尝试并读取输出,看看什么毛病你 Logstash 配置错误。Configuration OK
重新启动 Logstash,并启用它,把我们的配置更改生效︰
- sudo service logstash restart
- sudo update-rc.d logstash defaults 96 9
接下来,我们就会加载示例 Kibana 仪表板。
加载 Kibana 仪表板
弹性提供几个示例 Kibana 仪表板和节拍索引模式,可以帮助您开始使用 Kibana。虽然我们不会在本教程中使用的仪表板,我们就会加载它们无论如何所以我们可以使用它包括 Filebeat 索引模式。
首先,将示例仪表板档案下载到您的 home 目录︰
- cd ~
- curl -L -O https://download.elastic.co/beats/dashboards/beats-dashboards-1.1.0.zip
使用此命令安装软件包︰unzip
- sudo apt-get -y install unzip
接下来,提取归档文件的内容︰
- unzip beats-dashboards-*.zip
和加载示例仪表板、 可视化和节拍索引模式到 Elasticsearch 与这些命令︰
- cd beats-dashboards-*
- ./load.sh
这些都是我们只是加载索引模式︰
- [packetbeat-]YYYY。MM。DD
- [topbeat-]YYYY。MM。DD
- [filebeat-]YYYY。MM。DD
- [winlogbeat-]YYYY。MM。DD
当我们开始使用 Kibana 时,我们将作为我们的默认选择 Filebeat 索引模式。
Filebeat 指数在中加载模板 Elasticsearch
因为我们计划使用 Filebeat 来将日志传送到 Elasticsearch,我们应该加载 Filebeat 索引模板。索引模板将配置 Elasticsearch 传入的 Filebeat 字段中智能的方式进行了分析。
首先,将 Filebeat 索引模板下载到您的 home 目录︰
- cd ~
- curl -O https://gist.githubusercontent.com/thisismitch/3429023e8438cc25b86c/raw/d8c479e2a1adcea8b1fe86570e42abab0f10f364/filebeat-index-template.json
然后加载模板使用此命令︰
- curl -XPUT 'http://localhost:9200/_template/filebeat?pretty' -d@filebeat-index-template.json
如果模板正确加载,您应该看到这样的消息︰
{
"acknowledged" : true
}
现在,我们的麋鹿服务器已准备好接收 Filebeat 数据,让我们把每个客户端服务器上设置 Filebeat。
建立了 Filebeat (添加客户端服务器)
每个 Ubuntu 或 Debian 的服务器,您想要将日志发送到 Logstash 麋鹿服务器上执行这些步骤。对基于 Red Hat Linux 发行版 (如 RHEL,CentOS 等) 上安装 Filebeat 的说明,请参阅本教程的 CentOS 变化设置了 Filebeat ((添加客户端服务器)) 节。
将 SSL 证书复制
在你的麋鹿服务器,复制的 SSL 证书 — — 必备教程中创建 — — 向您的客户端服务器(替代客户端服务器的地址和你自己的登录)︰
- scp /etc/pki/tls/certs/logstash-forwarder.crt user@client_server_private_address:/tmp
提供您的登录凭据后, 确保证书副本获得成功。它是必需的客户端服务器和麋鹿服务器之间的通信。
现在,在您的客户端服务器,复制麋鹿服务器 SSL 证书到适当的位置 (等/pki/tls/证书)︰
- sudo mkdir -p /etc/pki/tls/certs
- sudo cp /tmp/logstash-forwarder.crt /etc/pki/tls/certs/
现在我们将安装 Topbeat 软件包。
安装 Filebeat 软件包
在客户端服务器上创建节拍源列表︰
- echo "deb https://packages.elastic.co/beats/apt stable main" | sudo tee -a /etc/apt/sources.list.d/beats.list
它也使用相同的 GPG 密钥作为 Elasticsearch,可以使用此命令安装︰
- wget -qO - https://packages.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
然后安装 Filebeat 软件包︰
- sudo apt-get update
- sudo apt-get install filebeat
Filebeat 已安装但尚未配置。
配置 Filebeat
现在我们将配置 Filebeat 连接到我们的麋鹿服务器上的 Logstash。本节将逐步指导您通过修改带有 Filebeat 的示例配置文件。当你完成这些步骤时,你应该有看起来像这一个文件。
在客户端服务器上,创建和编辑 Filebeat 配置文件︰
- sudo vi /etc/filebeat/filebeat.yml
注︰Filebeat 的配置文件是在 YAML 格式,这意味着缩进是非常重要的 !请务必使用相同数量的空间,表明在这些指令。
靠近顶部的文件,您将看到部分,这是你可以定义指定的日志文件应该被运的探矿者,他们应作如何处理。每个探矿者是用字符表示的。prospectors-
我们将修改现有探矿者发送和 Logstash。下,评出该文件。这将阻止发送 Filebeat 到 Logstash 目录中每个。然后添加新条目和。它应该看起来像这样当你完成时︰syslogauth.logpaths- /var/log/*.log.logsyslogauth.log
...
paths:
- /var/log/auth.log
- /var/log/syslog
# - /var/log/*.log
...
然后找到指定的行取消注释它并将其值更改为"系统日志"。经改性后,它应该看起来像这样︰document_type:
...
document_type: syslog
...
这指定中此探矿者的日志的类型syslog (这是我们的 Logstash 过滤器寻找的类型)。
如果你想要将其他文件发送到您的麋鹿服务器,或对 Filebeat 如何处理您的日志进行任何更改,请随时修改或添加探矿者的条目。
下一步下一节,, 查找行说,这表明 Elasticsearch 输出部分 (其中我们不打算使用)。删除或注释掉整个 Elasticsearch 输出部分(到线说)。outputelasticsearch:#logstash:
发现注释 Logstash 输出部分,表示的行所说,然后删去前再取消注释。在本节中,注释行。更改为专用 IP 地址 (或主机名,如果你跟那个选项) 的麋鹿服务器︰#logstash:#hosts: ["localhost:5044"]localhost
### Logstash as output
logstash:
# The Logstash hosts
hosts: ["ELK_server_private_IP:5044"]
这配置 Filebeat 连接到 Logstash 麋鹿服务器在端口 (我们指定早些时候的输入 Logstash 端口) 上。5044
直接条目下,相同的缩进,添加以下行︰hosts
bulk_max_size: 1024
下一步,找到部分,然后再取消注释。取消注释的行的指定,然后更改它的值对。它应该看起来像这样︰tlscertificate_authorities["/etc/pki/tls/certs/logstash-forwarder.crt"]
...
tls:
# List of root certificates for HTTPS server verifications
certificate_authorities: ["/etc/pki/tls/certs/logstash-forwarder.crt"]
这配置 Filebeat 来使用我们的麋鹿服务器创建 SSL 证书。
保存并退出。
现在重新启动 Filebeat 放我们的改变︰
- sudo service filebeat restart
- sudo update-rc.d filebeat defaults 95 10
再次,如果你不确定你的 Filebeat 配置是否正确,比较它反对此示例 Filebeat 配置。
现在发送 Filebeat 和 Logstash 麋鹿服务器上 !所有你想收集日志中的其他服务器重复这一节。syslogauth.log
Filebeat 安装进行测试
如果你麋鹿堆栈设置正确,Filebeat (在您的客户端服务器) 应航运您对 Logstash 麋鹿服务器上的日志。Logstash 应该是 Filebeat 数据加载到 Elasticsearch 日期戳的索引中。filebeat-YYYY.MM.DD
在您的麋鹿服务器,验证 Elasticsearch 的确接收数据,通过查询 Filebeat 指数与此命令︰
- curl -XGET 'http://localhost:9200/filebeat-*/_search?pretty'
您应该看到一群看起来像这样的输出︰
...
{
"_index" : "filebeat-2016.01.29",
"_type" : "log",
"_id" : "AVKO98yuaHvsHQLa53HE",
"_score" : 1.0,
"_source":{"message":"Feb 3 14:34:00 rails sshd[963]: Server listening on :: port 22.","@version":"1","@timestamp":"2016-01-29T19:59:09.145Z","beat":{"hostname":"topbeat-u-03","name":"topbeat-u-03"},"count":1,"fields":null,"input_type":"log","offset":70,"source":"/var/log/auth.log","type":"log","host":"topbeat-u-03"}
}
...
如果您的输出显示 0 总点击数,Elasticsearch 不加载任何日志在你搜索的索引下,您应该检查您的设置的错误。如果您收到预期的输出,继续下一步。
连接到 Kibana
当你完成所有你想要收集日志的服务器上的 Filebeat 的设置,让我们看看 Kibana,我们之前安装的 web 接口。
在 web 浏览器中,转到的 FQDN 或麋鹿服务器的公共 IP 地址。后输入"kibanaadmin"凭据时,您应该看到提示您配置默认索引模式的网页︰
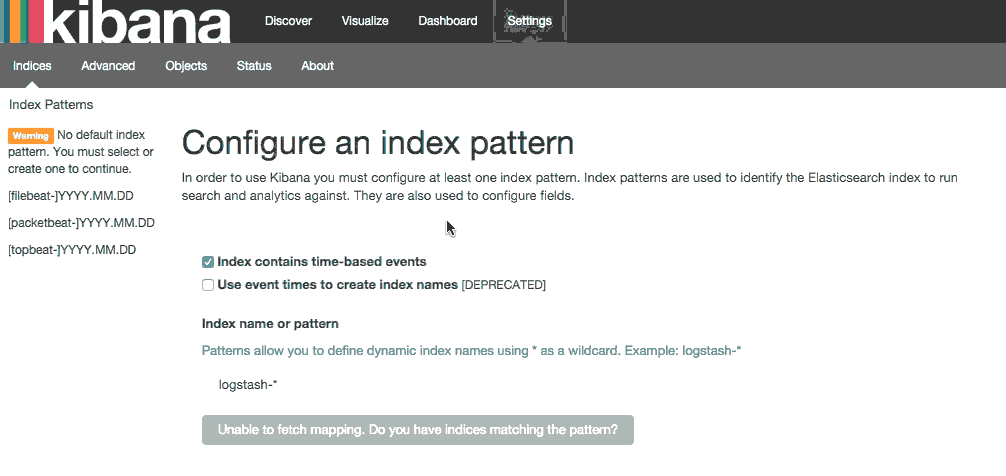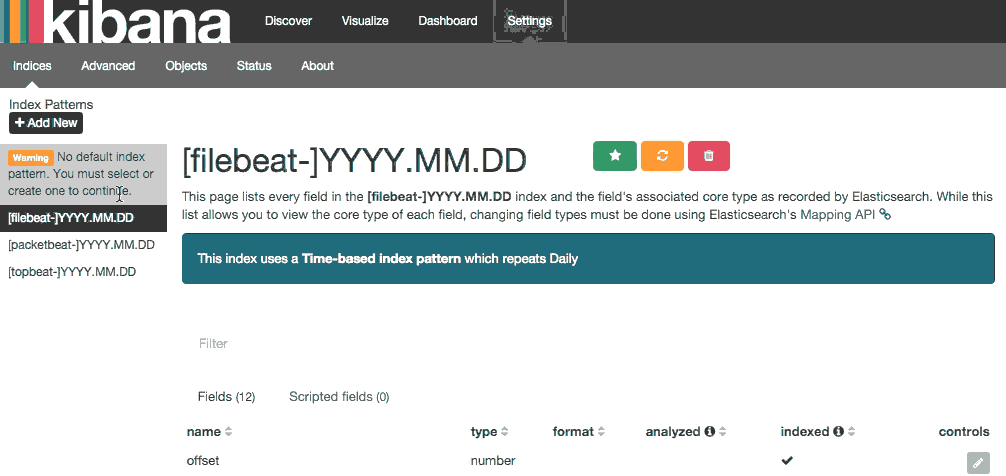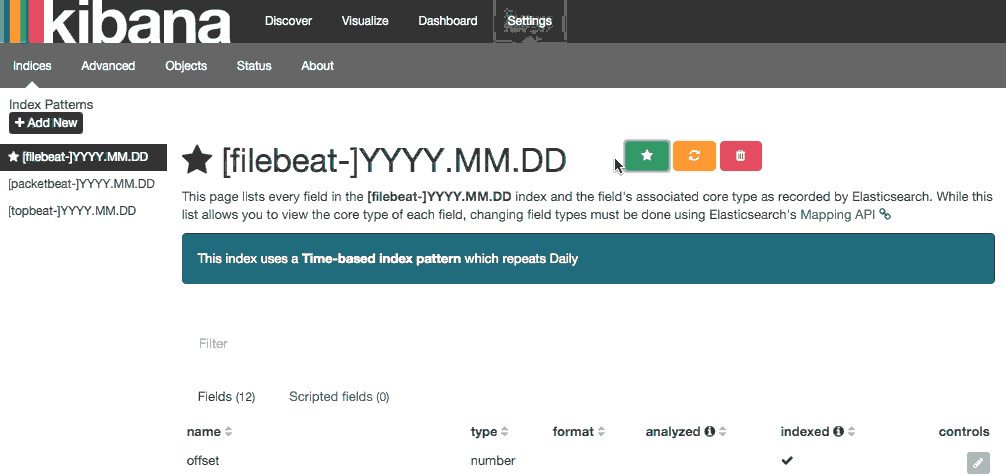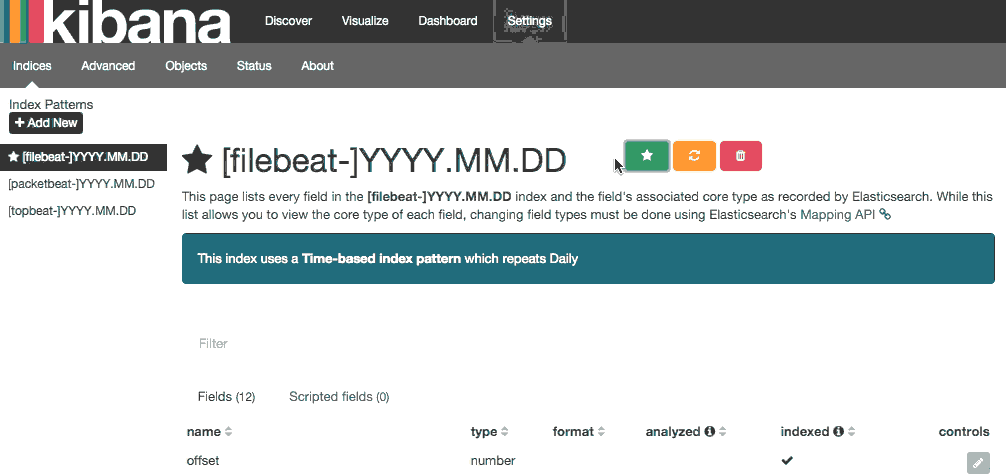
前进并选择[filebeat]-YYY。MM.DD从索引模式菜单 (左侧),然后单击星 (设为默认索引)按钮将 Filebeat 索引设置为默认值。
现在,单击顶部导航栏中的发现链接。默认情况下,这会显示所有的日志数据在最后 15 分钟。您应该看到直方图和日志事件,与下面的日志消息︰
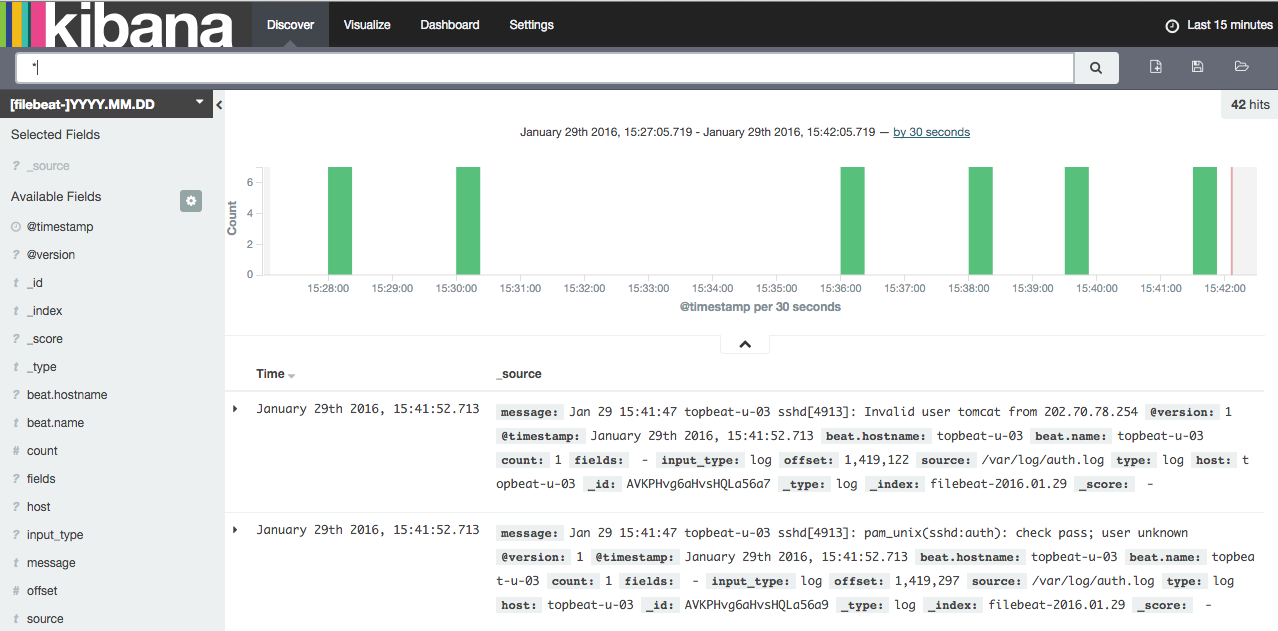
现在,就不会有在那里,因为你只从您的客户端服务器收集系统日志转移。在这里,你可以搜索和浏览您的日志。您还可以自定义您的仪表板。
请尝试以下操作︰
- 搜索"根"来看看是否任何人意图以 root 用户身份登录到您的服务器
- 搜索特定的主机名 (搜索
host: "hostname") - 通过选择面积直方图或从上面的菜单中更改时间框架
- 单击直方图下方的消息,请参阅筛选数据的方式
Kibana 有很多其他功能,例如图形和筛选,以便随时闲逛 !
结论
现在,你的系统日志转移集中通过 Elasticsearch 和 Logstash,你是能够想象他们与 Kibana,应关闭到一个好的开始,集中所有您重要的日志。请记住,您可以发送几乎任何类型的日志或索引的数据到 Logstash,但是数据变得更有用,如果它是分析和结构与神交。
为了提高你新的麋鹿堆栈,你应该考虑收集和筛选你其他日志 Logstash,与创建 Kibana 仪表板。您可能还要收集系统度量通过使用 Topbeat与你麋鹿堆栈。这些主题都被属于在这个系列的其他教程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号