
HashMap原理概述
HashMap底层实现采用了散列表,这是一种非常重要的数据结构。对于我们以后理解很多技术都非常有帮助(比如: redis数据库的核心技术和HashMap-样) ,因此,非常有必要让大家理解。
数据结构中由数组和链表来实现对数据的存储,他们各有特点。
(1)数组:占用空间连续。寻址容易 ,查询速度快。但是,增加和删除效率非常低
(2)链表:占用空间不连续。寻址困难 ,查询速度慢。但是,增加和删除效率非常高。
那么,我们能不能结合数组和链表的优点(即查询快,增删效率也高)呢?答案就是"哈希表”。哈希表的本质就是“数组+链表"。
查看源码

public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
transient Node<K,V>[] table;
...
}
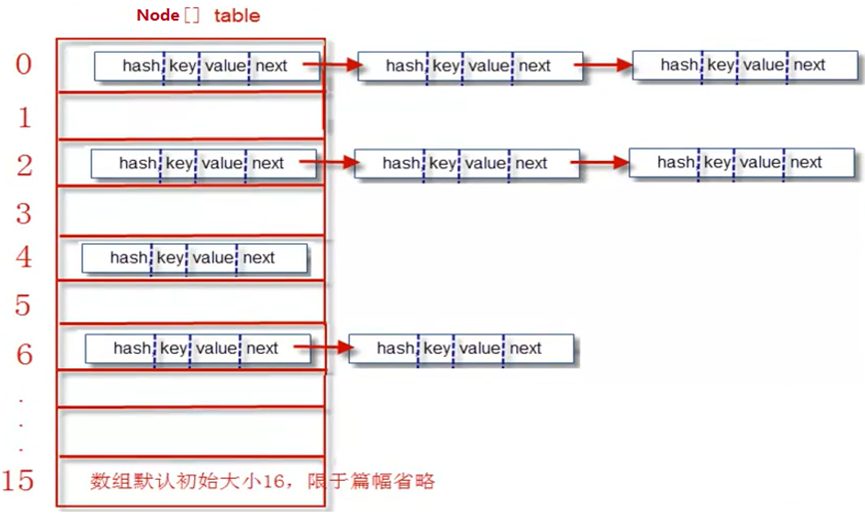
其中的Node[ ]table就是HashMap的核心数组结构,我们也称之为“位桶数组” 。我们再继续看Node是什么,源码如下:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
一个Node对象存储了:
1. key :键对象value :值对象
2. next:下一个节点
3. hash:键对象的hash值
显然每一个Entry对象就是一个单向链表结构,我们使用图形表示一个Entry对象的典型示意 :

Node对象存储结构图
然后,我们画出Node[]数组的结构(这也是HashMap的结构) :
l 存储数据过程put(key,value)
明白了HashMap的基本结构后,我们继续深入学习HashMap如何存储数据。此处的核心是如何产生hash值,该值用来对应数组的存储位置。
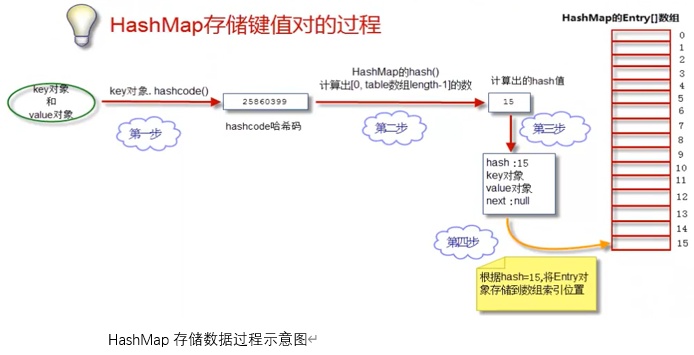
我们的目的是将”key-value两个对象”成对存放到HashMap的Node[]数组中。参见以下步骤:
- 获得key对象的hashcode
首先调用key对象的hashcode0方法,获得hashcode.
2.根据hashcode计算出hash值(要求在[0,数组长度 - 1]区间)
hashcode是一个整数,我们需要将它转化成[0,数组长度- 1]的范围。我们要求转化后的hash值尽量均匀地分布在[0,数组长度- 1]这个区间,减少"hash冲突".一种简单和常用的算法是(相除取余算法) :hash值= hashcode%数组长度。这种算法可以让hash值均匀的分布在[0,数组长度- 1]的区间。早期的HashTable就是采用这种算法。但是,这种算法由于使用了"除法”, 效率低下。JDK后来改进了算法。首先约定数组长度必须为2的整数幂,这样采用位运算即可实现取余的效果: hash值= hashcode&(数组长度-1)。为了获得更好的散列效果。JDK对hashcode进行了两次散列处理(核心目标就是为了分布更散更均匀),源码如下:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
3.生成Node对象
如上所述, 一个Node对象包含4部分: key对象、value对象、 hash值、指向下一个Node对象的引用。我们现在算出了hash值。下一个Node对象的引用为null。
4.将Node对象放到table数组中
如果本Node对象对应的数组索弓|位置还没有放Node对象,则直接将NodeNode存储进数组;如果对应索引位置已经有Node对象,则将已有Node对象的next指向本Entry对象,形成链表。
总结如上过程:当添加一个元素(key-value)时 ,首先计算key的hash值,以此确定插入数组中的位置,但是可能存在同一hash值的元素已经被放在数组同一位置了,这时就添加到同一hash值的元素的后面,他们在数组的同一位置,就形成了链表,同一个链表上的Hash值是相同的,所以说数组存放的是链表。
JDK8中,当链表长度大于8时,链表就转换为红黑树,这样又大大提高了查找的效率。
Ⅱ 取数据过程get(key)
我们需要通过key对象获得“键值对”对象,进而返回value对象。明白了存储数据过程,取数据就比较简单了,参见以下步骤:
- 获得key的hashcode ,通过hash()散列算法得到hash值,进而定位到数组的位置。
- 在链表上挨个比较key对象。调用equals()方法 ,将key对象和链表上所有节点的key对象进行比较,直到碰到返回true的节点对象为止。
- 返回equals()为true的节点对象的value对象。
明白了存取数据的过程,我们再来看一下hashcode()和equals方法的关系 :
Java中规定,两个内容相同(equals()为true)的对象必须具有相等的hashCode。因为如果equals()为true而两个对象的hashcode不同;那在整个存储过程中就发生了悖论。
Ⅲ 扩容问题
HashMap的位桶数组,初始大小为16。实际使用时,显然大小是可变的。如果位桶数组中的元素达到(0.75*数组length),就重新调整数组大小变为原来2倍大小。扩容很耗时。扩容的本质是定义新的更大的数组,并将旧数组内容挨个拷贝到新数组中。JDK8中, HashMap在存储一个元素时,当对应链表长度大于8时,链表就转换为红黑树,这样又大大提高了查找的效率。


