浅谈01分数规划
概念
01分数规划一般是处理这样一类问题:给定 n 个二元组 ( Ai , Bi ),让你从中选择 m 个组 (m<=n)使得
\[\sum_{k=1}^{m}\frac{Ak}{Bk} \]最大或最小,通常分为三类
Ⅰ:基础01分数规划
模板题(POJ2976)
给定 n 个二元组 ( Ai , Bi ),从中选择 m=n-k 个求\[\sum_{k=1}^{m}\frac{Ak}{Bk} \]的最大值
我们假设这个最大值为 L,即
比较明显的一种做法是二分枚举 L,然后按照 Ai-Bi*L 从小到大排序,取后 n-k 个的和 sum,若 sum >=0 则表明 L 还可以继续增大,更新下界,否则更新上界。
========================================================
#include<cstdio>
#include<algorithm>
using namespace std;
const int N = 1010;
const double eps = 1e-8;
int A[N],B[N],n,k;
double res[N];
bool check(double m)
{
for(int i=1;i<=n;i++) res[i]=A[i]-B[i]*m;
sort(res+1,res+n+1);
double tmp=0;
for(int i=k+1;i<=n;i++) tmp+=res[i];
return tmp>=0;
}
int main()
{
while(~scanf("%d%d",&n,&k)&&n+k)
{
for(int i=1;i<=n;i++) scanf("%d",&A[i]);
for(int i=1;i<=n;i++) scanf("%d",&B[i]);
double l=0,r=1.1;
while(r-l>=eps)
{
double m=(l+r)/2;
if(check(m)) l=m;
else r=m;
}
double ans=(l+r)/2;
printf("%.0f\n",ans*100);
}
}

这里重点讲述另一种做法,Dinkelbach 算法 ,我们随便设定一个初始值 L ,然后进行如下流程:
for(int i=1;i<=n;i++) res[i]=A[i]-B[i]*L;
sort(res+1,res+n+1);
double tmp=0;
for(int i=k+1;i<=n;i++) tmp+=res[i];
我们已知
现在我们用这选定的 m 个二元组去构造出
分三类情形讨论:
① tmp>0:明显有
\[newL>L \]前者是更优解,更新 L = newL
② tmp<0 : 这种情况下 L 肯定已经大于最优解了,此时肯定有
\[newL<L \]更新 L = newL
③ tmp=0 : 这时候肯定
\[newL==L \]那这个 L 就是最优解了
由上可以看出,无论 tmp 处于哪种情形(即无论 L 初始取何值),按照上述方法它都会不断地往最优解逼近,这就是 Dinkelbach 算法 的基本思想,和二分相比,二分是枚举上下边界逼近最优解,而 Dinkelbach 的逼近跨度相对更大,所以效率更高,一般会比二分快一些,但是因为需要根据前一个 L 选定的 若干二元组 去构造,所以会有额外的时空开销。
========================================================
#include<cmath>
#include<cstdio>
#include<algorithm>
using namespace std;
const int N = 1010;
const double eps = 1e-8;
int A[N],B[N],n,k;
struct node{
double x; int id;
bool operator < (const node& a)const{
return x<a.x;
}
}res[N];
int main()
{
while(~scanf("%d%d",&n,&k)&&n+k)
{
for(int i=1;i<=n;i++) scanf("%d",&A[i]);
for(int i=1;i<=n;i++) scanf("%d",&B[i]);
double L=1,ans;
while(1)
{
ans=L;
for(int i=1;i<=n;i++) res[i]=(node){A[i]-B[i]*L,i};
sort(res+1,res+n+1);
double a=0,b=0;
for(int i=k+1;i<=n;i++) a+=A[res[i].id],b+=B[res[i].id];
L=a/b;
if(abs(ans-L)<=eps) break;
}
printf("%.0f\n",ans*100);
}
}
此外,初始值的选定也会稍稍影响测评效率(拿这题来说,初始值设为 0 测试时间是47ms,而初始值设为 1 的 测试时间则都是 32ms ,应该是测试数据答案大部分偏向大一些),所以一般可根据题意初始化,若题意求最大,则初始化为上限值,若题意求最小,则初始化为下限值。

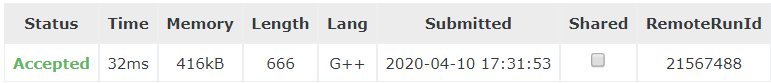
Ⅱ:最优比率生成树
模板题(POJ2728)
给定平面坐标系上的 n 个点,每个点都有权值,两点的花费是两点权差的绝对值,两点的收益是两点的距离,求一个生成树,使得树上的 花费/收益 最小
我们还是假设最小值为 L ,设选定的 m = n-1 条边的收益和花费二元组分别为 (val[i],cost[i]),则
和 基础01分数规划 一样我们还是可以选择二分枚举 L ,按照 cost[i]-val[i]*L 作为两点的边权求最小生成树,设当前最小生成树的总权值为
这里是求最小,若 tmp<=0,则更新上界,否则更新下界(由于是稠密图,所以最小生成树用prim求)
========================================================
#include<cmath>
#include<cstdio>
#include<iostream>
#include<algorithm>
using namespace std;
const int N = 1010;
const double eps = 1e-4;
const double inf = 0x3f3f3f3f;
int x[N],y[N],z[N],n;
double cost[N][N];
double val[N][N];
double cal(int i,int j){
double a=x[i]-x[j],b=y[i]-y[j];
return sqrt(a*a+b*b);
}
double prim(double m)
{
bool vis[N]={0,1};
double c[N],sum=0;
int tot=1,u=1,v;
while(tot<n)
{
double res=inf;
for(int i=1;i<=n;i++)
{
if(!vis[i])
{
double tmp=cost[u][i]-m*val[u][i];
if(tmp<c[i]||u==1) c[i]=tmp;
if(res>c[i]){
res=c[i];
v=i;
}
}
}
sum+=c[v];
vis[v]=1;
u=v;
tot++;
}
return sum;
}
int main()
{
while(~scanf("%d",&n)&&n)
{
for(int i=1;i<=n;i++)
scanf("%d%d%d",&x[i],&y[i],&z[i]);
for(int i=1;i<=n;i++)
for(int j=i+1;j<=n;j++)
{
val[j][i]= val[i][j]=cal(i,j);
cost[j][i]=cost[i][j]=abs(z[i]-z[j]);
}
double l=0,r=100;
while(abs(r-l)>eps)
{
double m=(l+r)/2;
if(prim(m)>=0) l=m;
else r=m;
}
printf("%.3f\n",l);
}
}

这题还是可以用 Dinkelbach 考虑,它依旧满足
这样的形式,所以我们还是 用旧 L 选择的 n-1 条边去构造 newL 使得
而不断去逼近最终答案
========================================================
#include<cmath>
#include<cstdio>
#include<iostream>
#include<algorithm>
using namespace std;
const int N = 1010;
const double eps = 1e-4;
const double inf = 0x3f3f3f3f;
int x[N],y[N],z[N],n;
double cost[N][N];
double val[N][N];
double cal(int i,int j){
double a=x[i]-x[j],b=y[i]-y[j];
return sqrt(a*a+b*b);
}
double prim(double m)
{
bool vis[N]={0,1};
double c[N],COST=0,DIS=0;
int tot=1,u=1,v,pre[N];
while(tot<n)
{
double res=inf;
for(int i=1;i<=n;i++)
{
if(!vis[i])
{
double tmp=cost[u][i]-m*val[u][i];
if(tmp<c[i]||u==1) c[i]=tmp,pre[i]=u;
if(res>c[i]){
res=c[i];
v=i;
}
}
}
COST+=cost[pre[v]][v];
DIS+= val[pre[v]][v];
vis[v]=1;
u=v;
tot++;
}
return COST/DIS;
}
int main()
{
while(~scanf("%d",&n)&&n)
{
for(int i=1;i<=n;i++)
scanf("%d%d%d",&x[i],&y[i],&z[i]);
for(int i=1;i<=n;i++)
for(int j=i+1;j<=n;j++)
{
val[j][i]= val[i][j]=cal(i,j);
cost[j][i]=cost[i][j]=abs(z[i]-z[j]);
}
double l=0,ans;
while(1)
{
ans=l;
l=prim(l);
if(abs(ans-l)<=eps) break;
}
printf("%.3f\n",ans);
}
}
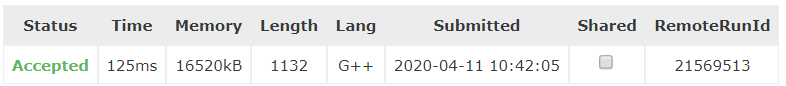
Ⅲ:最优比率环
模板题(POJ3621)
给定一个有向图,每个点有点权,每条边有边权,求图上的一个环,这个环的 点权和/边权和 最大,找到这个最大值
我们假设这个最大值为 L ,则对于所有图上的环来说,每个环肯定满足
反过来一下
可以明显的看出,只有这个 L >= 最优解 的时候,图上所有的环关于上式才一定成立,否则的话 L 就比最优解小,而判断上式是否存在<0 的情况等价于以 (点权*L-边权) 为 边判断负环是否存在,所以可以用二分+SPFA 解决这个问题
========================================================
#include<cmath>
#include<queue>
#include<stack>
#include<cstdio>
#include<cstring>
#include<iostream>
using namespace std;
const int N = 1010;
const int M = 5010;
const double eps = 1e-3;
int n,m,val[N];
struct node{
int to,nxt,w;
}e[M];
int head[N],tot=1;
void add(int u,int v,int w){
e[++tot]=(node){v,head[u],w};
head[u]=tot;
}
bool SPFA(double L)
{
double dis[N];
int in[N]={0},vis[N]={0};
for(int i=1;i<=n;i++) dis[i]=1e7;
dis[1]=0,vis[1]=1;
queue<int>q;
q.push(1);
while(!q.empty())
{
int u=q.front(); q.pop(); vis[u]=0;
for(int i=head[u];i;i=e[i].nxt)
{
int v=e[i].to,w=e[i].w;
double value=w*L-val[u];
if(dis[v]>dis[u]+value)
{
dis[v]=dis[u]+value;
if(++in[v]>n) return 1;
if(!vis[v])
{
q.push(v),vis[v]=1;
}
}
}
}
return 0;
}
int main()
{
scanf("%d%d",&n,&m);
for(int i=1;i<=n;i++)
scanf("%d",&val[i]);
for(int i=1,u,v,w;i<=m;i++)
scanf("%d%d%d",&u,&v,&w),add(u,v,w);
double l=0,r=10000;
while(abs(r-l)>eps)
{
double mid=(l+r)/2;
if(SPFA(mid)) l=mid;
else r=mid;
}
printf("%.2f",l);
}
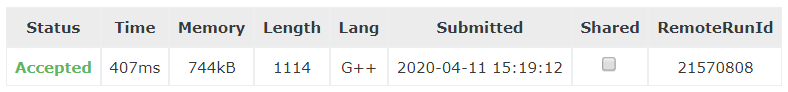
这题可不可以用 Dinkelbach 考虑呢,理论上肯定是可以的,但是难点就在于每次必须要记录这个具体的环来构造,显然找具体环的代价太大,得不偿失,所以这题还是二分更好。
总结
由上可以总结,对于01分数规划问题(maybe大部分),理论上都可以用 二分 或者 Dinkelbach 来解决,而 后者对答案的逼近效率一般是高于前者的,但是 Dinkelbach 每一次逼近的时候需要记录具体的二元组来构造,会造成额外的时空开销(视题意而定),所以 需要考虑这个 记录的代价 来 选择哪种解法更适合当前问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号