
分治法之排列的字典问题
东 华 大 学
《算法分析设计与综合实践》实验报告
学生姓名:曹晨学号:171310402 指导教师:章昭辉
实验时间:2019-3-13 实验地点:图文信息楼三号机房
请勿转载或抄袭
-
实验名称
排列的字典序列问题
-
实验目的
给定n及n个元素{1,2,‧‧‧,n}的一个排列,计算出这个排列的字典序值,以及按字典序排列的下一个排列
- 实验内容
n个元素{1,2,‧‧‧,n}有n!个不同的排列。将这n!个排列按字典序排列,并编号为0,1,‧‧‧,n!-1。每个排列的序号为其字典序值。例如n=3时,6个不同排列的字典序值如下:
|
字典序值 |
0 |
1 |
2 |
3 |
4 |
5 |
|
排列 |
123 |
132 |
213 |
231 |
312 |
321 |
数据输入:
输入的第一行是元素的个数n。接下来的1行是n个元素{1,2,‧‧‧,n}的一个排列
结果输出:
输出的第一行是字典序值,第二行是按字典序排列的下一个排列
-
实验过程
自己的思路:
经过分析,可以得出26458173的字典序为1*7!+4*6!+2*5!+2*4!+3*3!+0*2!+1*1!。
解释如下:
第一位为2,排在首位为2前面的有首位为1的排列,所以是1*7!。(在第一位为2的前提下)
第二位为6,排在第二位为6 前面的有第二位为1,3,4,5的排列,所以是4*6!。(在第一位为2,第二位为6的前提下)
第三位为4,排在第三位为4前面的有第三位为1,3的排列,所以是2*5!。(在第一位为2,第二位为6,第三位为4 的前提下)
‧‧‧‧‧‧‧‧‧
依次类推可以得到式子1*7!+4*6!+2*5!+2*4!+3*3!+0*2!+1*1!=8227
在STL库中有函数next_permutation和prev_permutation,前面的是求当前排列的下一个排列,后面的是求当前排列的上一个排列
参考答案上的思路:
- 由排列计算字典序值
设给定的{1,2,‧‧‧,n}的排列为 π ,其字典序值为rank(π,n)。按字典序的定义显然有:
以π[1]开头的第一个排列(π[1]-1)(n-1)!<=rank(π,n)<= π[1](n-1)!-1。以π[1]开头的最后一排列
这是什么意思呢?明白意思就要先搞明白π[1]代表什么,前面条件告诉我们,π是一个排列,那么π[1]就是这个排列第一个元素的值,π[i]就是第i个元素的值(这个我想了一晚上才反应过来),假如π="26458173"的话,那么π[1]=2,π[2]=6, π[3]=4等。
最主要的思想来了,也是我没有想到的:设r是π在以π[1]开头的所有排列中的序号,则r也是{π[2],π[3],‧‧‧,π[n]}作为集合{1,2,‧‧‧,n}-{π[1]}(减去π[1])中排列的的字典序值。如果将{π[2],π[3],‧‧‧,π[n]}中每个大于π[1]的元素都减去1,则得到集合{1,2,‧‧‧,n-1}的一个排列π'',其字典序值也是r。由此得到计算rank(π,n)的递归式如下:
rank(π,n)= (π[1]-1)(n-1)!+ rank(π'',n-1)
初始条件为rank(π[1],1)=0
|
26458173 |
(2-1)*7! |
6458173->5347162 |
|
5347162 |
(5-1)*6! |
347162->346152 |
|
346152 |
(3-1)*5! |
46152->35142 |
|
35142 |
(3-1)*4! |
5142->4132 |
|
4132 |
(4-1)*3! |
132->132 |
|
132 |
(1-1)*2! |
32->21 |
|
21 |
(2-1)*1! |
1->1 |
|
1 |
(1-1)*0! |
|
|
(2-1)*7!+(5-1)*6!+(3-1)*5!+(3-1)*4!+(4-1)*3!+(1-1)*2!+(2-1)1*1!+(1-1)*0!=8227 |
||
- 由字典序值计算排列
对于每个整数r,0<=r<=n!-1,都有唯一的阶层分解:r=∑di*i!(0<=di<=i,1<=i<=n-1)。
设r=rank(π,n),则π[1]=dn-1+1,进而由r''=r- dn-1(n-1)!= rank(π'',n-1)可递归找到排列π''。
r= dn-1* (n-1)!+ ‧‧‧+d2*2!+d1*1!+d0*0!
先得到尾项再得到前项,因为(r%1!)=0,任意的d0=(r%1)/0!=0,所以初始条件为1
|
r=8228 |
d=(r%2!)/1!=0 |
b[6]=1 |
大于b[i]的已经出现的都要加1,和上面的减1对称 |
12 |
|
r=8288 |
d=(r%3!)/2!=1 |
b[5]=2 |
213 |
|
|
r=8226 |
d=(r%4!)/3!=3 |
b[4]=4 |
4213 |
|
|
r=8202 |
d=(r%5!)/4!=2 |
b[3]=3 |
35214 |
|
|
r=8160 |
d=(r%6!)/5!=2 |
b[2]=3 |
346215 |
|
|
r=7290 |
d=(r%7!)/6!=4 |
b[1]=5 |
5347216 |
|
|
r=5040 |
d=(r%8!)/7!=1 |
b[0]=2 |
26458317 |
-
由排列计算下一个排列
对于给定的排列π
首先找到下标i,使得π[i]< π[i+1],且π[i+1]> π[i+2]> ‧‧‧>π[n];
其次找到下标j,使得π[i]< π[j]且对所有j<k<=n有π[k]< π[i]
然后交换π[i]和π[j]
最后将子排列{π[i+1],π[i+2],‧‧‧,π[n]}反转
举个例子如下:对于 8,1,6,4,7,5,3,2
1.首先从后向前遍历,后段7,5,3,2已经是一个逆序排列了,它是以8,1,6,4开头的最后一个排列,下一个排列不能以8,1,6,4开始,此时的4就是上面所说的i。
2.不能从8,1,6,4开始,那么只能从8,1,6,4的下一个开始,因为是字典序,所以要从后面找比4大的数,则是5(不能为7,8167超过了8165),此时的5就是上面所说的j。
3.交换4和5,变成了8,1,6,5,7,4,3,2
4.得到以8165开头的第一个排列,需要反转后面的排列7,4,3,2
5.最后得到排列8,1,6,5,2,3,4,7
-
结果分析
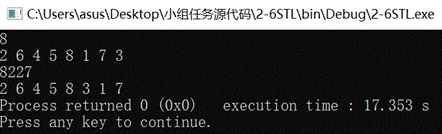
这个结果是我用自己的思想编写代码输出的,经验证答案正确
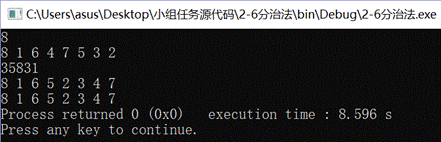
这个结果是我用参考答案和csdn上的思想编写代码输出的,经验证答案正确
-
实验总结
这次的实验又让我看到了分治法的广泛应用,虽然我自己写的代码不太好,但是我学习了很多令人拍手叫绝的算法,不禁感慨自己的水平还是很低。
另外我对c++中的库函数有了很大的兴趣,良好的运用它们可以省很多的力气。
附录:(要求代码里各行要有注释)
用自己的思想编写的代码(利用next_permutation库函数)
int factorial(int n)
{
if(n==1)
return 1;
else return n*factorial(n-1);
}//用于计算n的阶乘
void findSum(int *a,int n)
{
int count=0;
int sum=0;//该排列的字典序值
for(int i=0;i<n-1;i++)//从第一位遍历到第n-1位
{
for(int j=i+1;j<n;j++)
{
if(a[i]>a[j])
{
count++;//用来表示第i位的后面比它小的数的个数
}
}
sum+=count*factorial(n-i-1);//加上这一位前面的排序数
count=0;
}
cout<<sum<<endl;//输出字典序值
}
int main()
{
int n;//元素的个数
cin>>n;
int a[n];
for(int i=0;i<n;i++)
{
cin>>a[i];
}//数组用来存放元素
findSum(a,n);//调用计算字典序值的函数
if(next_permutation(a,a+n))//调用计算下一个排列的库函数
{
for(int i=0;i<n;i++)
{
cout<<a[i]<<" ";
}//输出下一个排列
}
return 0;
}
用(参考答案和csdn上的思想)自己编写的代码:
https://blog.csdn.net/anderyu/article/details/21481183
//计算n的阶乘
int factorial(int n)
{
if(n==1)
return 1;
else if(n==0)
return 0;
else return n*factorial(n-1);
}
//由排序计算字典序值
int permRank(int n,int *a) {
int r=0;//字典序值初始化
int i;
int b[n];
for(i=0;i<n;i++)
{
b[i]=a[i];
}//把元素放进数组b中
for(i=0;i<n;i++)//从第一个遍历数组
{
r+=(b[i]-1)*factorial(n-i-1);//加上当前阶层的字典序值
for(int j=i+1;j<n;j++)
{
if(b[i]<b[j])
{
b[j]--;
}//改变后段的值,把比当前的值大的值减1
}
}
return r;//返回字典序值
}
//由字典序值计算排列
void permUnrank(int n,int r,int *b)
{
if(n>=factorial(n))
return ;//如果n的数值大于排列的最大序值,则无输出
b[n-1]=1;//初始化最后一位数为1
for(int j=1;j<n;j++)
{
int d=(r%factorial(j+1))/factorial(j);//求当前阶层的d
r-=d*factorial(j);//总值减去这一阶层的值
b[n-1-j]=d+1;//当前位的值等于d+1
for(int i=n-1-j+1;i<n;i++)
{
if(b[i]>d)//可以改为if(b[i]>=b[n-1-j])
{
b[i]++;
}
}//这个for循环是用来把大于等于当前位且已存在的值加1
}
for(int i=0;i<n;i++)
{
cout<<b[i]<<" ";
}//输出排序
return ;
}
//由排列计算下一个排列
void permSucc(int n,int *a,int &flag)
{
int i=n-2;//从最后一个开始往前遍历
while(a[i+1]<a[i]&&i!=-1)
{
i--;
}//直到遇到前面一个的值小于后面一个的值时停止
if(i==-1)
flag=0;//flag等于0意味着a的排列时所有排列中的最后一个,即逆序,没有下一个排列了
else
{
flag=1;//反之意味着有下一个排列
int j=n-1;//从最后一个开始寻找j
while(a[j]<a[i])
j--;//直到j的值大于i的值时停止
swap(a[i],a[j]);
for(int m=i+1;m<=(n-1+i)/2;m++)
{
swap(a[m],a[n+i-m]);
}//交换i和j的值
}
for(int m=0;m<n;m++)
{
cout<<a[m]<<" ";
}//将后段的排序反转
return ;
}
//主函数
int main()
{
int n;
cin>>n;//排列的元素个数
int a[n];
for(int i=0;i<n;i++)
{
cin>>a[i];
}//存放元素
int r=permRank(n,a);//调用求排列字典序值的函数
int b[n];
cout<<r<<endl;
permUnrank(n,r+1,b);//调用由字典序值求出排列的函数
cout<<endl;
int flag;
permSucc(n,a,flag);//调用由排列计算下一个排列的函数
return 0;
}


