
微博爬虫 python
本文爬取的是m站的微博内容,基于python 2.7
一、 微博内容爬取
1.要爬取的微博首页网址https://m.weibo.cn/u/3817188860?uid=3817188860&luicode=10000011&lfid=100103type%3D1%26q%3DAlinda
2.手机微博是看不到翻页,是一直往下加载的,但是其json格式的数据仍然以翻页的形式呈现。
3.打开开发者工具,向下翻页面,可以在Network下的XHR的响应文件中,找到json文件的网址。
如:https://m.weibo.cn/api/container/getIndex?uid=3817188860&luicode=10000011&lfid=100103type%3D1%26q%3DAlinda&containerid=1076033817188860&page=4
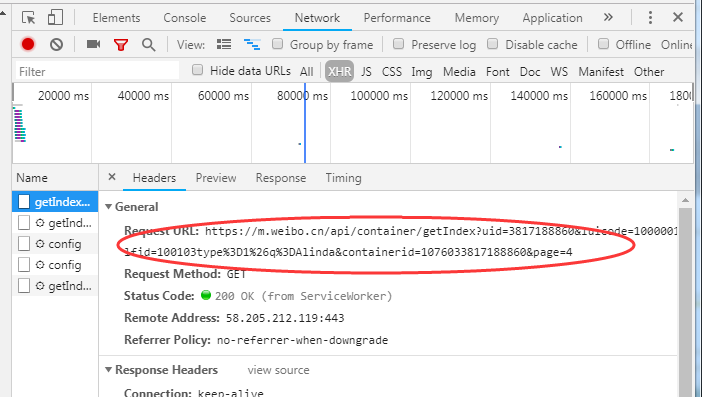
通过分析发现每个JSON页面是有规律的,即前面的内容都一样,只是后面的页码不同;每个json页面的格式如下:
https://m.weibo.cn/api/container/getIndex?uid=3817188860&luicode=10000011&lfid=100103type%3D1%26q%3DAlinda&containerid=1076033817188860&page=【page_num】
一般情况下一个json页面有11微博评论(我只是查看了几个页面,所有的页面是不是这样,我没有去验证)
知道json页面的组成规律,我们就可以爬虫了!!!
4.微博内容爬取
代码如下:
# -*- coding: utf-8 -*-
import requests
import re
from fake_useragent import UserAgent
import pandas as pd
ua = UserAgent()
headers = {
'User-Agent':ua.random, # ua.random是随机生成一个User-Agent
'Host': 'm.weibo.cn',
'Referer': 'https://m.weibo.cn/p/1005053817188860?sudaref=login.sina.com.cn',
}
def WriteInCsv(list):
df = pd.DataFrame(list, columns=[u'微博内容链接', u'创建时间', u'id', u'微博内容',u'转发数', u'评论数', u'点赞数'])
df.to_excel("content.xlsx", encoding="utf_8_sig", index=False)
def getMblogContent():
list = []
bsae_url = 'https://m.weibo.cn/api/container/getIndex?uid=3817188860&luicode=10000011&lfid=100103type%3D1%26q%3DAlinda&containerid=1076033817188860&page='
for p in range(0, 149):
try:
url = bsae_url + p.__str__()
resp = requests.get(url, headers=headers, timeout=10)
JsonData = resp.json()
data = JsonData.get('data').get('cards') # cards里包含此页面的所有微博内容
print p
for d in data: # data是列表类型
try:
scheme = d['scheme']
mblog = d['mblog'] # i是字典类型
created_at = mblog['created_at'] # mblog也是页面里的一个容器名字,一个mblog表示一个微博
id = mblog['idstr']
text = re.sub(u"\\<.*?>", "", mblog['text']) # 去除<>标签里的内容
print text
reposts_count = mblog['reposts_count']
comments_count = mblog['comments_count']
attitudes_count = mblog['attitudes_count']
list.append([scheme, created_at, id, text, reposts_count, comments_count, attitudes_count])
except:
print "error"
except:
print "打开页面错误"
return list
print "OK"
list = getMblogContent()
WriteInCsv(list)
5.代码说明:
(1)本代码总共用了两个try。第一个try是为了跳过打不开的json页面;第二个try是为了跳过“mblog”内容为的字典,最开始没有加第2 try,老是出错,后来发现是因为有些“mblog”里并没有内容,是空的。
二、微博评论爬取
1.从上面的json数据页面获取字段idstr,即微博id。
从https://m.weibo.cn/status/4177994643916324地址可以获取一条微博的手机页面。
格式:https://m.weibo.cn/status/【id】
2.从https://m.weibo.cn/api/comments/show?id=4273393069439291&page=1
地址可以获取一条微博的评论的json格式数据,id为一条微博的id,page为评论翻页。
格式:https://m.weibo.cn/api/comments/show?id=【id】&page=【page_num】
3.从m站爬取的微博评论,最多只有100页,大概是1000条。
4.可以从以下方式获取所有的评论页面,但得到的是HTML页面,不是JSON格式,所有我还没有找到获取页面内容的方法???
格式:https://weibo.com/aj/v6/comment/big?ajwvr=6&id=【id】&filter=all&page=【page_num】。
5.微博博主(m站的,每条微博最多获取100页的评论数据)所有微博评论的python实现代码如下:
# -*- coding: utf-8 -*-
import requests
import re
from fake_useragent import UserAgent
import pandas as pd
ua = UserAgent()
headers = {
'User-Agent': ua.random, # ua.random是随机生成一个User-Agent
'Host': 'm.weibo.cn',
'Referer': 'https://m.weibo.cn/p/1005053817188860?sudaref=login.sina.com.cn',
}
def WriteInCsv(list):
df = pd.DataFrame(list, columns=[u'微博id', u'用户id', u'评论文本', u'评论数'])
df.to_excel("comment.xlsx", encoding="utf_8_sig", index=False)
def getOnePageComment(mblog_id,data,hot_data):
for i in data:
text = re.sub(u"\\<.*?>", "", i['text']) # 去除<>标签里的内容
like_counts = i['like_counts']
user_id = i['user']['id'].__str__()
list.append([mblog_id, user_id, text, like_counts])
for i in hot_data:
text = re.sub(u"\\<.*?>", "", i['text']) # 去除<>标签里的内容
like_counts = i['like_counts']
user_id = i['user']['id']
list.append([mblog_id, user_id, text, like_counts])
print "list长度:"
print len(list)
base_url= "https://m.weibo.cn/api/comments/show?id="
df = pd.read_excel("content.xlsx") # excel
id_list =df['id']
list = []
i = 0
for id in id_list:
mblog_id = id.__str__()
print i
base_url2 = base_url+id.__str__() +'&page='
for p in range(0, 100):
try:
url = base_url2 + p.__str__()
print url
resp = requests.get(url, headers=headers, timeout=10)
JsonData = resp.json()
if JsonData['ok'] != 0:
data = JsonData.get('data').get('data') # cards是页面里的一个容器名字
print "data"
else:
break
if JsonData.get('data').get('hot_data'):
hot_data = JsonData.get('data').get('hot_data')
print "hot_data"
else:
hot_data = ""
print "hot_data_null"
getOnePageComment(mblog_id, data, hot_data)
except:
print 'error'
i = i + 1
print "OK"
WriteInCsv(list)
