
Java基础——正则表达式
一、什么是正则表达式
正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表通常被用来检索、替换那些符合某个模式(规则)的文本。
许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。正则表达式这个概念最初是由Uinx中的工具软件(例如sed和grep)普及开的。正则表达式通常缩写成“regex”,单数有regexp、regex、复数有regexps、regexes、regexen。
* 代表多个
?代表一个字符(可以有,可以无)
--图书编号 要么是5个数字,要么是5个数字加上 - 4 个数字,比如 12345 或 12345-0001
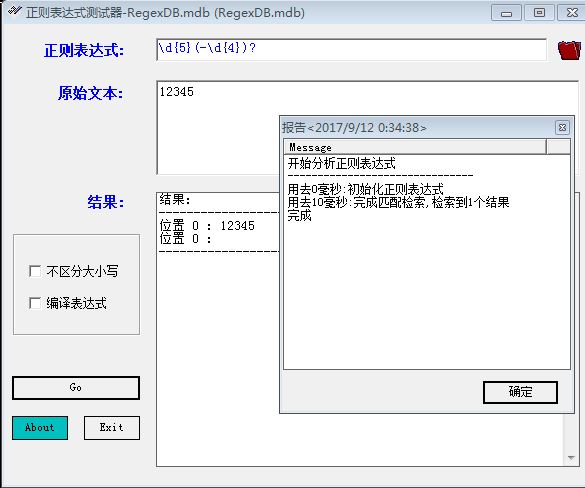
var r =new RegExp("\\d{5}"); 如果用要匹配 \ 怎么办? 要使用 \\\\ (四个) var r=/\d{5}/;
var setr="高睿说: 我我..下棋....很.很....厉害"; //第一次,去掉所有的. str=str.replace(/\./g,""); //第二次,去掉重复的字 str=str.replace(/(.)\1/g, "$1"); //结果 : 高睿说: 我下棋很厉害
== 定位符
1) ^ 规定匹配必须发生在目标字符串的开头部分上,必须出现在最前面才有用
例如 ^o 与 ok中的 o 匹配,但于 dog 中的 o 不匹配,,如果设置了RegExp对象实例的
MultiLine 属性, ^ 还会与首行匹配, 即与 \n 或 \r 之后的位置匹配
2) $ 匹配目标字符串的结尾位置,必须出现在最后才有定位符的作用
例如 o$ 与 hello 中的 o 匹配 ,但与 ok 中的 o不匹配
3) \b 匹配一个字(也就是一个单词) 的边界,它包含了字与空格间的位置以及目标字符串的开始和结束等位置
例如 "er\b" 匹配 never ok 中的er ,但不匹配 verx 中的er
"\bis\b" 匹配 this is anicecat isisisdog 中的 is
4) \B \b的逆运算 ,结果与上例相反
//例子
调用 replace(/win/g,"close") 来替换 win a window ,得到 close a closedow
调用 repalce(/\bwin\b,"close"/) 得到 close a window
//例子
如果想在一段文本的内容中的每行前面都加上同一个标记文本,只需使用这个标记文本对
^ 做全局替换即可
var str= "aaa\nbbb\nccc";
alert( str.replace(/^/mg,"#")); 这里的m 指的是多行的意思
结果:
#aaa
#bbb
#ccc
== 附
---- 原义字符
一些元字符不在再表示它原来的字面意义,如果要匹配它们的字面意义,必须使用
\ 转义
需要进行转义的字符 $ ( * . [ ? \ / ^ { |
---- 优先级顺序
* 比字符优先级高,比如 ab* 是 b 和 * 组合后,再和前面的 a组合
()比 *优先级高,(ab)* 是a和b组合后,再和* 组合,字符比 | 优先级高,
a|bc 是 bc组合后,再和 a 组合
一些正则表达式模式范例
匹配空行 /^\s*$/
匹配HTML标记 /<(\S+)(\s[^>]*)?>[\s\S]*<\/\1\s*>/
匹配email /^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$/
匹配两个相同相邻的单词 /\b([a-z]+)\1\b/ //例如 CatCat
匹配 ip 地址 /^\d{1,2}|1\d\d|2[0-4]\d|25[0-5](\.(\d{1,2}|1\d\d|2[0-4]\d|25[0-5])){3}$/
\u4e00-\u9fa5 表示中文
四、java 中使用正则表达式验证

//例一 验证手号码 public static boolean checkPhone(String str){ boolean result=true; if(str.length()!=11){ result=false; System.out.println("号码长度不正确"); } if(!str.startsWith("1")){ result=false; System.out.println("不是以1开头的"); } char [] arr=str.toCharArray(); for(int i=0;i<arr.length;i++){ if(!(arr[i]>='0'&&arr[i]<='9')){ result=false; System.out.println("含有非法字符"); break; } } return result; }
//例二 public static boolean checkPhone2(String str){ boolean result=true; try{ Long.parseLong(str); } catch(Exception ex){ System.out.println("手机号格式不正确"); result=false; } return result; }
// 例三 public static boolean checkPhone3(String str){ String regex="1[3584]\\d{9}"; return str.matches(regex); }
//例四 使用正则表达式进行切割 public static void splitDemo1(){ String str="aaa---bbb-------ccc----ddd"; String [] strList=str.split("-+"); System.out.println(strList.length); for(String s:strList){ System.out.println(s); } }
//例五 public static void splitDemo2(){ String str="aaa.bbb.ccc.ddd"; String [] strList=str.split("\\."); System.out.println(strList.length); for(String s:strList){ System.out.println(s); } }
//例六 public static void splitDemo3(){ String str="c:\\windows\\system32\\aa.bmp"; String [] strList=str.split("\\\\"); System.out.println(strList.length); for(String s:strList){ System.out.println(s); } }
//例七 替换 public static void replaceDemo(){ String str="要1234想办456假证,请联系13503688749或13302564798 或者是 15050020120 或者 257"; String regex="\\d{11}"; System.out.println(str.replaceAll(regex, "混球")); }
//例八 获取 public static void getDemo(){ String str="林花谢了春红大葱葱,太匆匆,好大大葱大葱葱大葱葱葱"; String regex="大葱葱+"; Pattern pattern=Pattern.compile(regex); Matcher matcher=pattern.matcher(str); while(matcher.find()){ System.out.println(matcher.group()); } }
//例九 从网页上获取 public static void webGetDemo()throws Exception { URL url=new URL("http://localhost:8080/book-shop/login.jsp"); URLConnection conn=url.openConnection(); BufferedReader br=new BufferedReader(new InputStreamReader(conn.getInputStream())); String regex="[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\\.[a-zA-Z0-9_-]+)+"; Pattern pattern =Pattern.compile(regex); String str=null; while((str=br.readLine())!=null){ Matcher matcher=pattern.matcher(str); while(matcher.find()){ System.out.println(matcher.group()); } } }


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· Vue3状态管理终极指南:Pinia保姆级教程