OpenResty 最佳实践 (2)
此文已由作者汤晓静授权网易云社区发布。
欢迎访问网易云社区,了解更多网易技术产品运营经验。
lua 协程与 nginx 事件机制结合
文章前部分用大量篇幅阐述了 lua 和 nginx 的相关知识,包括 nginx 的进程架构,nginx 的事件循环机制,lua 协程,lua 协程如何与 C 实现交互;在了解这些知识之后,本节阐述 lua 协程是如何和 nginx 的事件机制协同工作。
从 nginx 的架构和事件驱动机制来看, nginx 的并发处理模型概括为:单 worker + 多连接 + epoll + callback。 即每个 nginx worker 同时处理了大量连接,每个连接对应一个 http 请求,一个 http 请求对应 nignx 中的一个结构体(ngx_http_request_t):
struct ngx_http_request_s {
uint32_t signature; /* "HTTP" */
ngx_connection_t *connection; void **ctx; void **main_conf; void **srv_conf; void **loc_conf;
ngx_http_event_handler_pt read_event_handler;
ngx_http_event_handler_pt write_event_handler;
....
}结构体中的核心成员为 ngx_connection_t *connection,其定义如下:
struct ngx_connection_s { void *data;
ngx_event_t *read; // epoll 读事件对应的结构体成员
ngx_event_t *write; // epoll 写事件对应的结构体成员
ngx_socket_t fd; // tcp 对应的 socket fd
ngx_recv_pt recv;
ngx_send_pt send;
ngx_recv_chain_pt recv_chain;
ngx_send_chain_pt send_chain;
ngx_listening_t *listening;
...
}从如上结构体可知,每个请求中对应的 ngx_connection_t 中的读写事件和 epoll 关联;nginx epoll 的事件处理核心代码如下:
...
events = epoll_wait(ep, event_list, (int) nevents, timer); for (i = 0; i < events; i++) {
c = event_list[i].data.ptr;
instance = (uintptr_t) c & 1;
c = (ngx_connection_t *) ((uintptr_t) c & (uintptr_t) ~1); // epoll 获取激活事件,将事件转换成 ngx_connection_t
...
rev = c->read;
rev->handler(rev);
...
wev = c->write;
wev->handler(ev);
...
}nginx epoll loop 中调用 epoll_wait 获取 epoll 接管的激活事件,并通过 c 的指针强转,得到 ngx_connection_t 获取对应的连接和连接上对应的读写事件的回调函数,即通过 C 结构体变量成员之间的相关关联来串联请求和事件驱动,实现请求的并发处理;这里其实和高级语言的面向对象的写法如出一辙,只是模块和成员变量之间的获取方式的差异。
如果引入 lua 的协程机制,在 lua 代码中出现阻塞的时候,主动调用 coroutine.yield 将自身挂起,待阻塞操作恢复时,再将挂起的协程调用 coroutine.resume 恢复则可以避免在 lua 代码中写回调;而何时恢复协程可以交由 c 层面的 epoll 机制来实现,则可以实现事件驱动和协程之间的关联。现在我们只需要考虑,如何将 lua_State 封装的 lua land 和 C land 中的 epoll 机制融合在一起。
事实上 lua-nginx-module 确实是按照这种方式来处理协程与 nginx 事件驱动之间的关系,lua-nginx-module 为每个 nginx worker 生成了一个 lua_state 虚拟机,即每个 worker 绑定一个 lua 虚拟机,当需要 lua 脚本介入请求处理流程时,基于 worker 绑定的虚拟机创建 lua_coroutine 来处理逻辑,当阻塞发生、需要挂起时或者处理逻辑完成时挂起自己,等待下次 epoll 调度时再次唤醒协程执行。如下是 rewrite_by_lua 核心代码部分:
tatic ngx_int_tngx_http_lua_rewrite_by_chunk(lua_State *L, ngx_http_request_t *r){
co = ngx_http_lua_new_thread(r, L, &co_ref);
lua_xmove(L, co, 1);
ngx_http_lua_get_globals_table(co);
lua_setfenv(co, -2);
ngx_http_lua_set_req(co, r); // 此处设置协程与 ngx_http_request_t 之间的关系
...
rc = ngx_http_lua_run_thread(L, r, ctx, 0); // 运行 lua 脚本处理 rewrite 逻辑
if (rc == NGX_ERROR || rc > NGX_OK) { return rc;
}
...
}从上述代码片段中我们看到了协程与 ngx 请求之间的绑定关系,那么只要在 ngx_http_lua_run_thread 函数中(实际上是在 lua 脚本中)处理何时挂起 lua 的执行即可。大部分时候我们在 lua 中的脚本工作类型分两种,一种是基于请求信息的逻辑改写,一种是基于 tcp 连接的后端交互。逻辑改写往往不会发生 io 阻塞,即当前脚本很快执行完成后回到 C land,不需要挂起再唤醒的流程。而对于方式二,lua-nginx-module 提供了 cosocket api, 它封装了 tcp api,并且会在合适的时候(coroutine.yield 的调用发生在 IO 异常,读取包体完毕,或者 proxy_buffers 已满等情形,具体的实现读者可以参考 ngx_http_lua_socket_tcp.c 源码)调用 coroutine.yield 方法 。 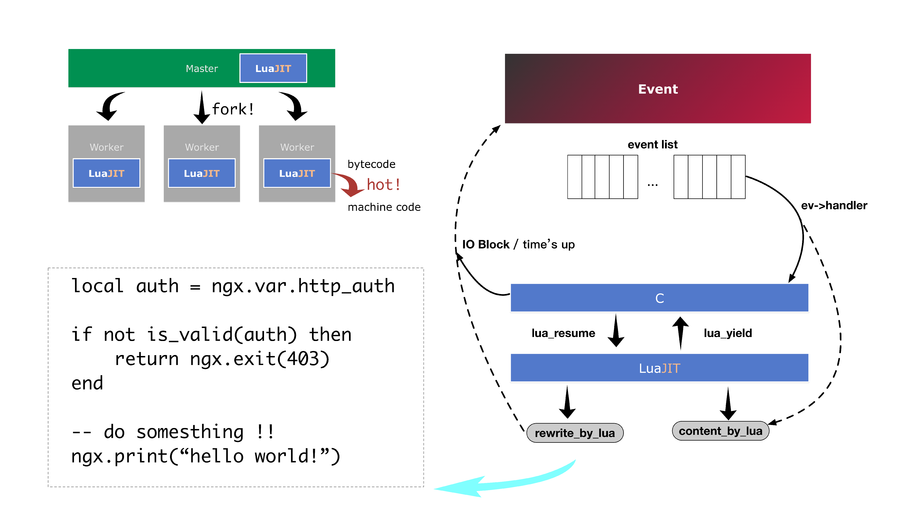
综上所述,结合lua 协程和 nginx 事件驱动机制,使用 OpenResty 可以使用 lua 脚本方便的扩展 nignx 的功能。
OpenResty hooks (编程钩子)

init_by_lua
该阶段主要用于预加载一些 lua 模块, 如加载全局 json 模块:require 'cjson.safe';设置全局的 lua_share_dict 等,并且可以利用操作系统的 copy-on-write 机制;reload nginx 会重新加载该阶段的代码。
init_worker_by_lua
该阶段可用于为每个 worker 设置独立的定时器,设置心跳检查等。
rewrite_by_lua
实际场景中应用最多的一个 hooks 之一,可用于请求重定向相关的逻辑,如改写 host 头,改写请求参数和请求路径等
access_by_lua
该阶段可用于实现访问控制相关的逻辑,如动态限流、限速,防盗链等
content_by_lua
该阶段用于生成 http 请求的内容,和 proxy_pass 指令冲突;二者在同一个阶段只能用一个。该阶段可用于动态的后端交互,如 mysql、redis、kafaka 等;也可用于动态的 http 内容生成,如使用 lua 实现 c 的 slice 功能,完成大文件的分片切割。
banalce_by_lua
该阶段可用于动态的设置 proxy_pass 的上游地址,例如用 lua 实现一个带监控检测机制的一致性 hash 轮序后端算法,根据上游的响应动态设置该地址是否可用。
body_filter_by_lua
用于过滤和加工响应包体,如对 chunk 模式的包体进行 gzip; 也可以根据包体的大小来动态设置 ngx.var.limit_rate.
header_filter_by_lua
调整发送给 client 端的响应头,也是最常用的 hooks 之一;比如设置响应的 server 头,修缓存头 cache-control 等。
log_by_lua
一方面可以设置 nginx 日志输出的字段值,另一方面我们也可以用 cosocket 将日志信息发送到指定的 http server;因响应头和响应体已发送给客户端,该阶段的操作不会影响到客户端的响应速度。
OpenResty 之 lua 编写常见陷阱
elseif,区别于 else if;
and & or,不支持问号表达式;lua 中 0 表示 true;
no continue,lua 中不支持 continue 语法;需要用 if 和 else 语句实现;
. & :,lua 中 object.method 和 object:method 行为不同,object:method 为语法糖,会扩展成第一个参数为 self
forgot return _M,在编写模块的时候如果最后忘记 return _M, 调用时会提示尝试对 string 调用方法的异常
OpenResty 编程优化
do local statement,尽量使用 local 化的变量声明,加速变量索引速度的同时避免全局命名空间的污染;
do not use blocked api,不要调用会阻塞 lua 协程的 api,比如 lua 原生的 socket,会造成 nginx worker block;
use ngx.ctx instead of ngx.var,ngx.var 会调用 ngx.var 的变量索引系统,比 ngx.ctx 低效很多;
decrease table resize,避免 lua table 表的 resize 操作,可以用 luajit 事先声明指定大小的 table。比如频繁的 lua 字符串相加的 .. 操作,当 lua 预分配内存不够时,会重新动态扩容(和 c++ vector 类型),会造成低效;
use lua-resty-core,使用 lua-resty-core api,该部分 api 用 luajit 的 ffi 实现比直接的 C 和 lua 交互高效;
use jit support function,少用不可 jit 加速的函数,那些函数不能 jit 支持,可以参看 luajit 文档。
ffi,对自己实现的 C 接口,也建议用 ffi 暴露出接口给 lua 调用。
nginx 易混易错配置说明
so_keepalive
用于 listen 中,探测连接保活; 采用TCP连接的C/S模式软件,连接的双方在连接空闲状态时,如果任意一方意外崩溃、当机、网线断开或路由器故障,另一方无法得知TCP连接已经失效,除非继续在此连接上发送数据导致错误返回。很多时候,这不是我们需要的。我们希望服务器端和客户端都能及时有效地检测到连接失效,然后优雅地完成一些清理工作并把错误报告给用户。
如何及时有效地检测到一方的非正常断开,一直有两种技术可以运用。一种是由TCP协议层实现的Keepalive,另一种是由应用层自己实现的心跳包。
TCP默认并不开启Keepalive功能,因为开启 Keepalive 功能需要消耗额外的宽带和流量,尽管这微不足道,但在按流量计费的环境下增加了费用,另一方面,Keepalive设置不合理时可能会因为短暂的网络波动而断开健康的TCP连接。并且,默认的Keepalive超时需要7,200,000 milliseconds,即2小时,探测次数为 5 次。系统默认的 keepalive 配置如下:
net.ipv4.tcpkeepaliveintvl = 75 net.ipv4.tcpkeepaliveprobes = 5 net.ipv4.tcpkeepalivetime = 7200
如果在 listen 的时候不设置 so_keepalive 则使用了系统默认的 keepalive 探测保活机制,需要 2 小时才能清理掉这种异常连接;如果在 listen 指令中加入
so_keepalive=30m::10
可设置如果连接空闲了半个小时后每 75s 探测一次,如果超过 10 次 探测失败,则释放该连接。
sendfile/directio
sendfile
copies data between one file descriptor and another. Because this copying is done within the kernel, sendfile() is more efficient than the combination of read(2) and write(2), which would require transferring data to and from user space.
从 Linux 的文档中可以看出,当 nginx 有磁盘缓存文件时候,可以利用 sendfile 特性将磁盘内容直接发送到网卡避免了用户态的读写操作。
directio
Enables the use of the O_DIRECT flag (FreeBSD, Linux), the F_NOCACHE flag (macOS), or the directio() function (Solaris), when reading files that are larger than or equal to the specified size. The directive automatically disables (0.7.15) the use of sendfile for a given request
写文件时不经过 Linux 的文件缓存系统,不写 pagecache, 直接写磁盘扇区。启用aio时会自动启用directio, 小于directio定义的大小的文件则采用 sendfile 进行发送,超过或等于 directio 定义的大小的文件,将采用 aio 线程池进行发送,也就是说 aio 和 directio 适合大文件下载。因为大文件不适合进入操作系统的 buffers/cache,这样会浪费内存,而且 Linux AIO(异步磁盘IO) 也要求使用directio的形式。
proxy_request_buffering
控制处理客户端包体的行为,如果设置为 on, 则 nginx 会接收完 client 的整个包体后处理。如 nginx 作为反向代理服务处理客户端的上传操作,则先接收完包体再转发给上游,这样上游异常的时候,nginx 可以多次重试上传,但有个问题是如果包体过大,nginx 端如果负载较重话,会有大量的写磁盘操作,同时对磁盘的容量也有较高要求。如果设置为 off, 则传输变成流式处理,一个 chunk 一个 chunk 传输,传输出错更多需要 client 端重试。
proxy_buffer_size
Sets the size of the buffer used for reading the first part of the response received from the proxied server. This part usually contains a small response header. By default, the buffer size is equal to one memory page. This is either 4K or 8K, depending on a platform.
proxy_buffers
Sets the number and size of the buffers used for reading a response from the proxied server, for a single connection. By default, the buffer size is equal to one memory page. This is either 4K or 8K, depending on a platform.
proxy_buffering
Enables or disables buffering of responses from the proxied server.
When buffering is enabled, nginx receives a response from the proxied server as soon as possible, saving it into the buffers set by the proxy_buffer_size and proxy_buffers directives. If the whole response does not fit into memory, a part of it can be saved to a temporary file on the disk. Writing to temporary files is controlled by the proxy_max_temp_file_size and proxy_temp_file_write_size directives.
When buffering is disabled, the response is passed to a client synchronously, immediately as it is received. nginx will not try to read the whole response from the proxied server. The maximum size of the data that nginx can receive from the server at a time is set by the proxy_buffer_size directive.
当 proxy_buffering on 时处理上游的响应可以使用 proxy_buffer_size 和 proxy_buffers 两个缓冲区;而设置 proxy_buffering off 时,只能使用proxy_buffer_size 一个缓冲区。
proxy_busy_size
When buffering of responses from the proxied server is enabled, limits the total size of buffers that can be busy sending a response to the client while the response is not yet fully read. In the meantime, the rest of the buffers can be used for reading the response and, if needed, buffering part of the response to a temporary file. By default, size is limited by the size of two buffers set by the proxy_buffer_size and proxy_buffers directives.
当接收上游的响应发送给 client 端时,也需要一个缓存区,即发送给客户端而未确认的部分,这个 buffer 也是从 proxy_buffers 中分配,该指令限定能从 proxy_buffers 中分配的大小。
keepalive
该指令可作用于 nginx.conf 和 upstream 的 server 中;当作用于 nginx.conf 中时,表示作为 http server 端回复客户端响应后,不关闭该连接,让该连接保持 ESTAB 状态,即 keepalive。 当该指令作用于 upstrem 块中时,表示发送给上游的 http 请求加入 connection: keepalive, 让服务端保活该连接。值得注意的是服务端和客户端均需要设置 keepalive 才能实现长连接。 同时 keepalive指令需要和 如下两个指令配合使用:
keepalive_requests 100;keepalive_timeout 65;
keepalive_requests 表示一个长连接可以复用的次数,keepalive_timeout 表示长连接在空闲多久后可以关闭。 keepalive_timeout 如果设置过大会造成 nginx 服务端 ESTAB 状态的连接数增多。
nginx 维护与更新
nginx 信号集和 nginx 操作之间的对应关系如下:
| nginx operation | signal |
|---|---|
| reload | SIGHUP |
| reload | SIGUSR1 |
| stop | SIGTERM |
| quit | SIGQUIT |
| hot update | SIGUSR2 & SIGWINCH & SIGQUIT |
stop vs quit
stop 发送 SIGTERM 信号,表示要求强制退出,quit 发送 SIGQUIT,表示优雅地退出。 具体区别在于,worker 进程在收到 SIGQUIT 消息(注意不是直接发送信号,所以这里用消息替代)后,会关闭监听的套接字,关闭当前空闲的连接(可以被抢占的连接),然后提前处理所有的定时器事件,最后退出。没有特殊情况,都应该使用 quit 而不是 stop。
reload
master 进程收到 SIGHUP 后,会重新进行配置文件解析、共享内存申请,等一系列其他的工作,然后产生一批新的 worker 进程,最后向旧的 worker 进程发送 SIGQUIT 对应的消息,最终无缝实现了重启操作。 再 master 进程重新解析配置文件过程中,如果解析失败则会回滚使用原来的配置文件,即 reload 失败,此时工作的还是老的 worker。
reopen
master 进程收到 SIGUSR1 后,会重新打开所有已经打开的文件(比如日志),然后向每个 worker 进程发送 SIGUSR1 信息,worker 进程收到信号后,会执行同样的操作。reopen 可用于日志切割,比如 nginx 官方就提供了一个方案:
$ mv access.log access.log.0 $ kill -USR1 `cat master.nginx.pid` $ sleep 1 $ gzip access.log.0 # do something with access.log.0
这里 sleep 1 是必须的,因为在 master 进程向 worker 进程发送 SIGUSR1 消息到 worker 进程真正重新打开 access.log 之间,有一段时间窗口,此时 worker 进程还是向文件 access.log.0 里写入日志的。通过 sleep 1s,保证了 access.log.0 日志信息的完整性(如果没有 sleep 而直接进行压缩,很有可能出现日志丢失的情况)。
hot update
某些时候我们需要进行二进制热更新,nginx 在设计的时候就包含了这种功能,不过无法通过 nginx 提供的命令行完成,我们需要手动发送信号。
首先需要给当前的 master 进程发送 SIGUSR2,之后 master 会重命名 nginx.pid 到 nginx.pid.oldbin,然后 fork 一个新的进程,新进程会通过 execve 这个系统调用,使用新的 nginx ELF 文件替换当前的进程映像,成为新的 master 进程。新 master 进程起来之后,就会进行配置文件解析等操作,然后 fork 出新的 worker 进程开始工作。
接着我们向旧的 master 发送 SIGWINCH 信号,然后旧的 master 进程则会向它的 worker 进程发送 SIGQUIT 信息,从而使得 worker 进程退出。向 master 进程发送 SIGWINCH 和 SIGQUIT 都会使得 worker 进程退出,但是前者不会使得 master 进程也退出。
最后,如果我们觉得旧的 master 进程使命完成,就可以向它发送 SIGQUIT 信号,让其退出了。
引用
更多网易技术、产品、运营经验分享请点击。
相关文章:
【推荐】 直播平台杜绝违规内容之道
【推荐】 Spring Boot 学习系列(05)—自定义视图解析规则
【推荐】 Flink on Yarn模式启动流程分析

 浙公网安备 33010602011771号
浙公网安备 33010602011771号