猛犸机器学习开发实践
本文来自 网易云社区 。
Dolphin 是猛犸平台里的一个机器学习功能模块,提供给数据科学家进行机器学习的算法开发、模型训练和服务发布,提供分布式全功能深度学习框架,易学易用,高效灵活,支持 Tensorflow、MXNet、Caffe、Spark 等多种机器或深度学习框架,最大可能的挖掘出数据的价值。
Dolphin 是基于 Kubernetes 和 Docker 构建的机器学习的底层架构,通过 OVS (或 Calico)构建了容器的扁平化网络,通过 Harbor 进行容器管理,系统还实现了 GPU 监控管理、存储、日志、监控、权限管理等功能。
Architecture
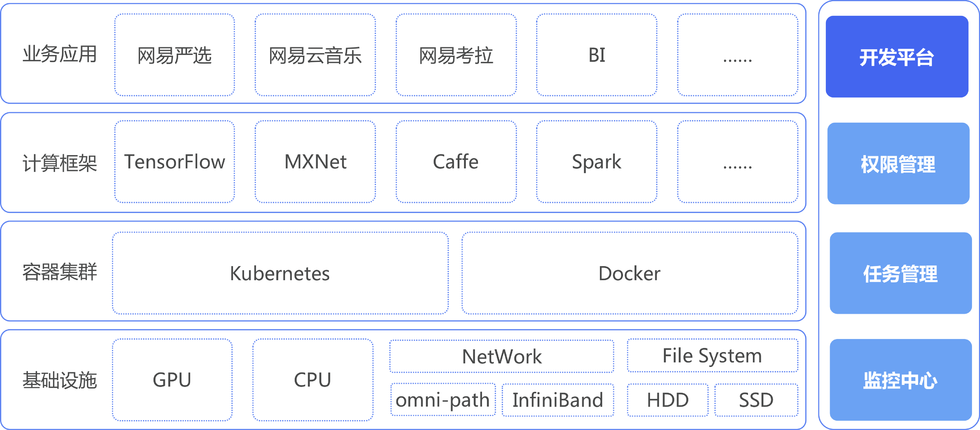
- 基础设施
整个系统基础设施中包括了 GPU 和 CPU 的混合计算服务节点,服务器之间通过 InfiniBand 构建高速的数据交换网络,数据存储在 HDD 和 SSD 盘的 HDFS 文件系统中 - 容器集群
dolphin 通过 Docker 对多种机器学习框架、用户开发环境进行实例化和运行,完全通过 Kubernetes 提供计算集群的部署、维护、 扩展机制等功能 - 计算框架
Tensorflow 和 Kubernetes 均是由 Google 开源,Tensorflow 可以原生态的支持 Kubernetes 的调度和监控管理。Kubernetes 是高度可配置和可扩展的系统,我们通过扩展 CustomResourceDefinition 实现 MXNet 等其他机器学习框架的接入 - 开发平台
数据科学家在开发平台进行数据管理、特征管理、可视化算法开发和计算流程图设计,一键式服务发布 - 数据安全
dolphin 具有字段级别的细粒度数据权限控制能力,能够对 IMPALA、SPARK、HIVE 实现一致性的 SQL 执行权限校验和对应的 HDFS 文件访问控制,保障了标签数据、训练数据和模型数据的数据安全 - 任务管理
开发了基于队列的任务调度系统,解决了 Kubernetes 没有队列服务的问题
开发了计算节点的 GPU 监控服务,解决了 Kubernetes 目前无法监控 GPU 的资源使用情况的问题
开发了 Kubernetes 中训练服务的参数服务的生命周期管理模块,解决了 Tensorflow 的参数服务在训练完毕无法自我关闭的问题 - 监控中心
通过 Heapster+Influxdb+Grafana 进行集群的监控,通过 Fluentd+Elasticsearch+Kibana 进行日志的收集
Kubernetes Cluster
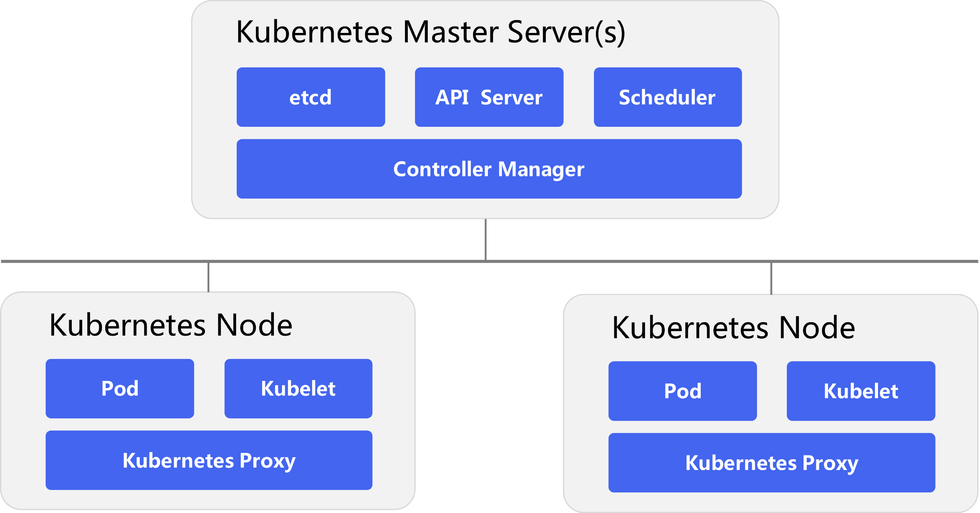
Master
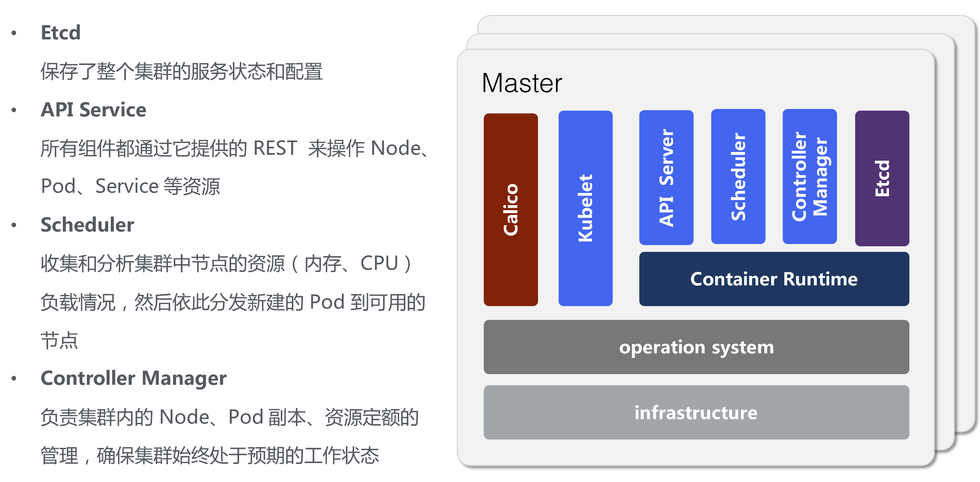
- API Server:提供了资源对象的唯一 REST 操作入口,其他所有组件都必须通过它提供的API来操作 NODE、POD、Service 资源数据
- Controller Manager:作为集群内部的管理控制中心,负责集群内的 Node、Pod 副本、Endpoint、Namespace、服务账号、资源定额的管理,当某个 Node 意外宕机时,Controller Manager 会及时发现并执行自动化修复流程,确保集群始终处于预期的工作状态
- Scheduler:收集和分析当前 Kubernetes 集群中所有 Minion 节点的资源(内存、CPU)负载情况,然后依此分发新建的 Pod 到 Kubernetes 集群中可用的节点
- Etcd:保存了整个 Kubernetes 集群的状态
Minion
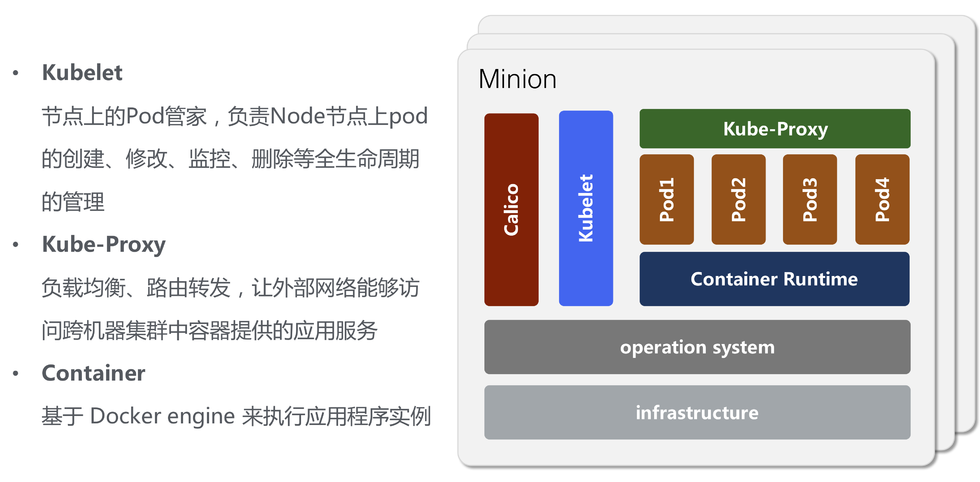
- Kubelet:节点上的 Pod 管家,负责 Node 节点上 pod 的创建、修改、监控、删除等全生命周期的管理
- Proxy:解决外部网络能够访问跨机器集群中容器提供的应用服务
Kubernetes Master
Kubernetes Node
Etcd - Distributed reliable key-value store
Etcd 服务发现是一个基于 Raft 协议的强一致性、高可用的键值对存储,用于 集群中的服务注册、监控服务健康状态 和共享服务配置,在 Etcd 中 存储了 kubernetes 集群所有的数据。
kubernetes NetWork Model
谷歌内部的基础设施已经保障了所有的容器之间通过平行网络实现互联互通,Kubernetes 预留了网络插件接口,由使用者自行构建网络,目前社区也给出了 Flannel、Calico、OVS 等网络方案,机器学习是一个计算密度型系统,对数据传输性能要求非常高,所以需要慎重考虑使用哪种网络模型。
- Flannel:是使用桥接接口转发网络包的 overlay 网络,从一个容器发往另一个容器的网络包将历经两个网络栈,网络传输性能存在一定的损耗,所以没有采纳该方案
- Calico:是使用了基于 BGP 路由方式的网络模型,数据通过 Linux Kernel 查找路由表直接转发到对方容器所在的宿主机,避免了 Flannel 网络存在的数据从内核态到用户态的 2 次处理,效率损耗最小,Calico 部署十分的方便快捷,非常适合在私有化的环境中进行部署使用
- OVS:在公有云的部署直接使用网易云的 OVS 网络
Calico
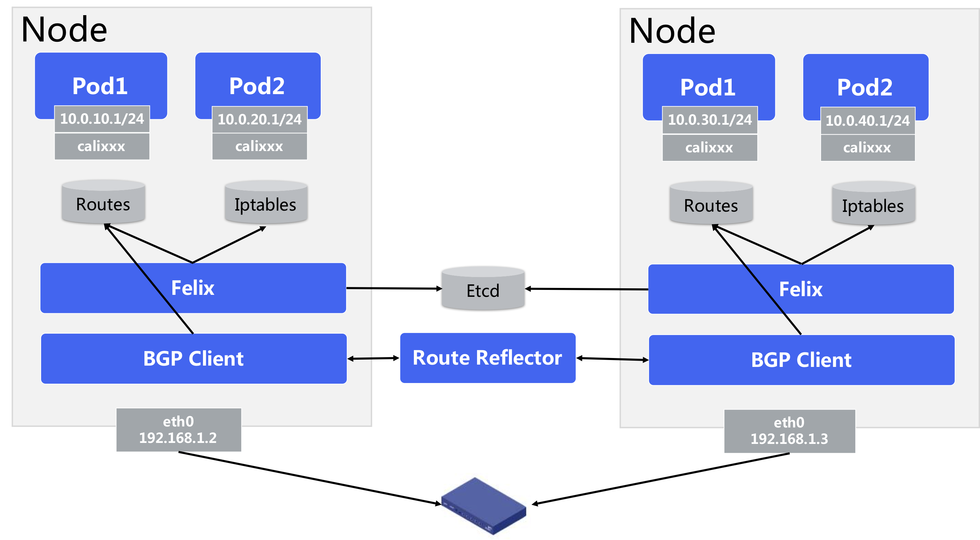
- Felix,主要负责配置路由及ACLs等信息来确保endpoint的连通状态
- Etcd,主要负责网络元数据一致性,确保Calico网络状态的准确性
- BGPClient(BIRD),主要负责把 Felix 写入 kernel 的路由信息分发到当前 Calico 网络,确保 workload 间的通信的有效性
- BGPRouteReflector(BIRD),大规模部署时使用,摒弃所有节点互联的 mesh 模式,通过一个或者多个 BGPRouteReflector 来完成集中式的路由分发
- Calico 在每一个计算节点利用 Linux kernel 实现了一个高效的 vRouter 来负责数据转发,而每个 vRouter 通过 BGP 协议负责把自己上运行的 workload 的路由信息向整个 Calico 网络内传播,小规模部署可以直接互联,大规模下可通过指定的 BGProutereflector 来完成
NVidia Docker
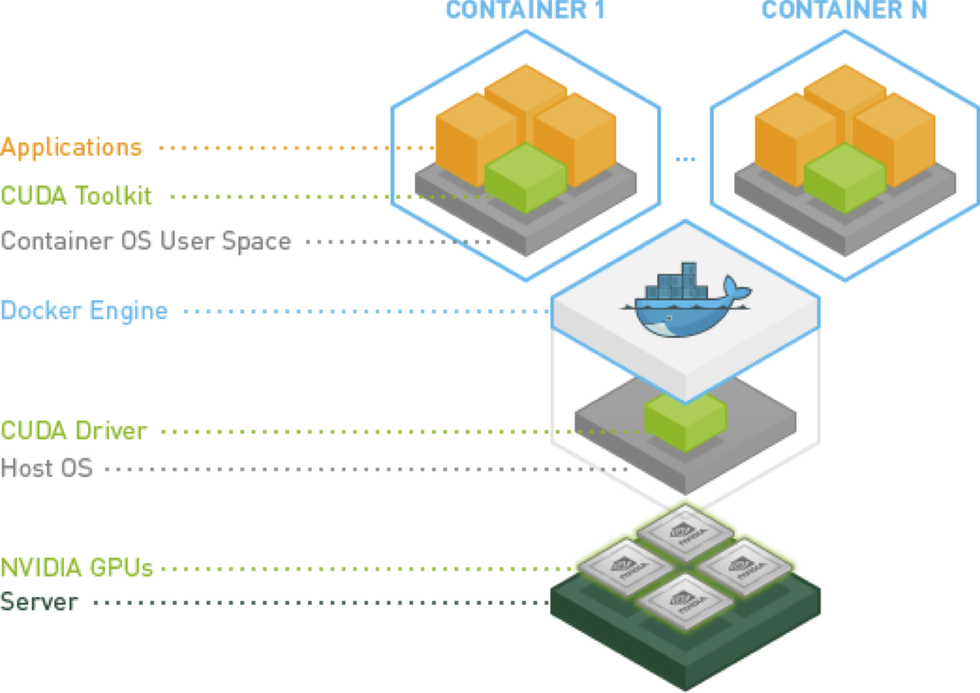
因为 GPU 属于特定的厂商产品,需要特定的 Driver,Docker 本身并不支持 GPU。以前如果要在 Docker 中使用 GPU,就需要在 Container 中安装主机上使用 GPU 的 Driver,然后把主机上的 GPU 设备(例如:/dev/nvidia0)映射到 Container 中,所以这样的 Docker image 并不具备可移植性。
英伟达公司的 Nvidia-docker 项目就是为了解决这个问题,它让 Docker image 不需要知道底层 GPU 的相关信息,而是通过启动 Container 时 mount 设备和驱动文件来实现的,通过查看 Nvidia-docker 的源代码,我们可以了解到 Nvidia-docker 是对 Docker 的 create 和 run 命令进行了封装,将驱动信息映射到 Container 中。
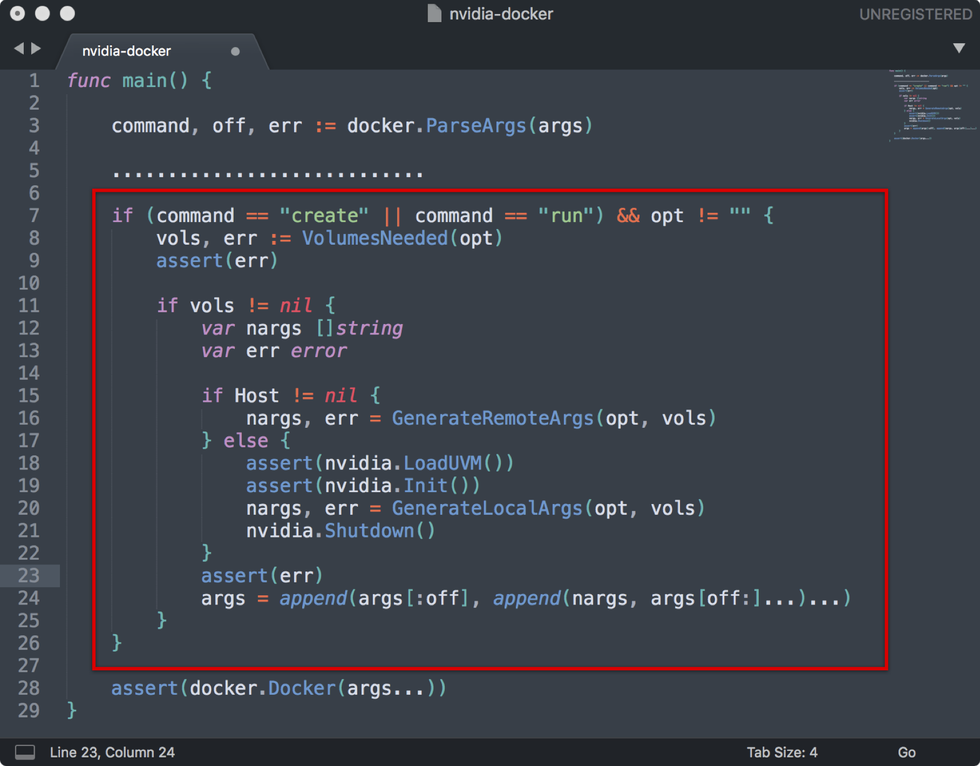
通过执行 curl -s http://localhost:3476/docker/cli 命令我们能够获取到类似如下 Nvidia 驱动信息:
--device=/dev/nvidiactl --device=/dev/nvida-uvm --device=/dev/nvidia3 --device=/dev/nvidia2 --device=/dev/nvidia1 --device=/dev/nvidia0 --volume-drivre=nvidia-docker --volume=/usr/local/nvidia/nvidia_driver_361.48
那么我们就可以直接通过 docker run -it -rm curl -s http://localhost:3476/docker/cli nvidia/cuda nvidia-smi 直接启动一个支持 GPU 的 Docker Container,在了解了 Nvidia-docker 的运行原理之后,我们完全可以直接使用原生态的 Docker 而不需要使用 Nvidia-docker 项目。
TensorFlow
TensorFlow 是谷歌开源的深度学习工具包,它将深度学习复杂的计算过程抽象成了数据流图(Data Flow Graph),并提供简介灵活的高级抽象接口,通过简单的学习就可以使用「高大上」的深度学习了。
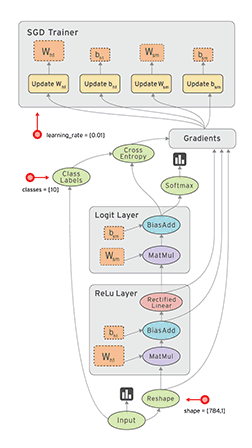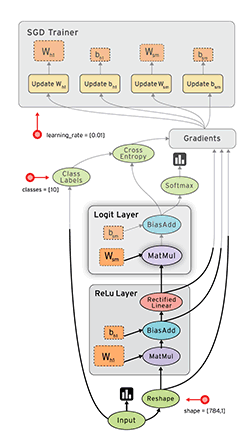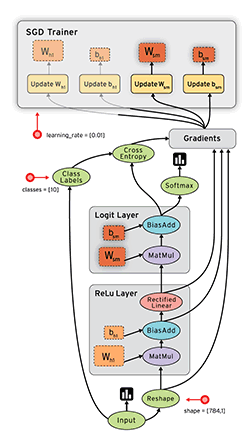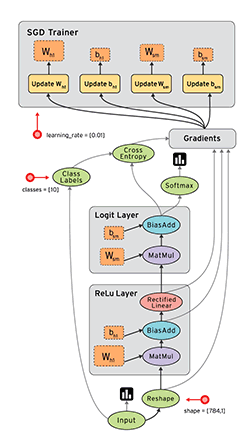
上图中的示例显示了从数据 Input 开始,沿着有向图进行计算,图中每个节点都是一次计算,称为 option,TensorFlow 中数据以 Tensor 为格式,输入一个 Tensor ,经过一次 op 后输出另一个 Tensor,然后根据数据流图进入下一个 op 作为输入,因此,整个计算过程其实是一个 Tensor 数据的流动过程,所以谷歌将这个系统形象的叫做 TensorFlow。
有了数据流图后下一个问题是如何在各种设备上很好的运行,TensorFlow 通过一个会话 Session 来控制整个数据流图的执行。TensorFlow 一个很大的优点是将复杂的运算(如矩阵运算,softmax)封装成了高级函数,用户只要使用就好了,在内部,TensorFlow 将这些函数转化成可以高效在 CPU 或 GPU 执行的机器码。Session 的主要作用是将这张数据流图合理的切分(尽量减少 Session 与 CPU 或 GPU 之间的交互,因为很慢),按照一定的顺序提交给 CPU 或者 GPU,然后(可能)还进行一些容错的机制,Session 负责高效地让数据流图被 CPU 或 GPU 执行完成的。
Tensorflow on Kubernetes
如果让数据科学家直接使用 Tensorflow 的时候,会遇到例如租户隔离、资源隔离、网络隔离、难以指定 GPU 进行任务调度等等一系列软件工程问题,这也是为什么需要引入 Kubernetes 的原因。
- Tensorflow 资源无法隔离
Kubernetes 提供租户隔离,容器资源隔离和网络隔离等多种机制 - Tensorflow 缺乏 GPU 资源的调度
Kubernetes-v1.4 开始支持 GPU 调度 - Tensorflow 存在进程遗留问题、无法区分正常完成还是故障退出
Kubernetes 提供容器生命周期管理,进程和容器共生死
不过在进行分布式 Tensorflow 训练的时候,社区仍然没有解决 Work 已经工作完毕,Parameter Server 无法自行退出的问题,需要自己开发训练任务进度监控让 Parameter Server 退出 - Tensorflow 集群服务器定位
Kubernetes 提供 DNS 服务器提供服务器位置,省去了 Tensorflow 的计算集群的服务节点 IP 地址配置 - Tensorflow 不方便日志查看
Kubernetes 提供了较为完善的 Monitoring 和 Logging 功能 - Tensorflow 存在训练数据和模型存储问题
Kubernetes 支持对接 Cephfs,GlusterFS 等 Read 性能更好的分布式存储系统 - 多种机器学习框架支持
通过定制化开发 Kubernetes 的 Custom Resource 和 Operator 接口支持 MXNet 等其他机器学习框架
Dolphin
作为数据科学家的开发工具,如何让数据科学家能够在算法编写、参数调整的时候能够直接获取交互式的反馈信息,我们通过深度定制 Jupyter 内核开发了完全在可视化的 dolphin WEB 系统,让数据科学家在交互式操作界面中所见即所得的编写算法、调试参数、输出可视化图表并形成算法报告。
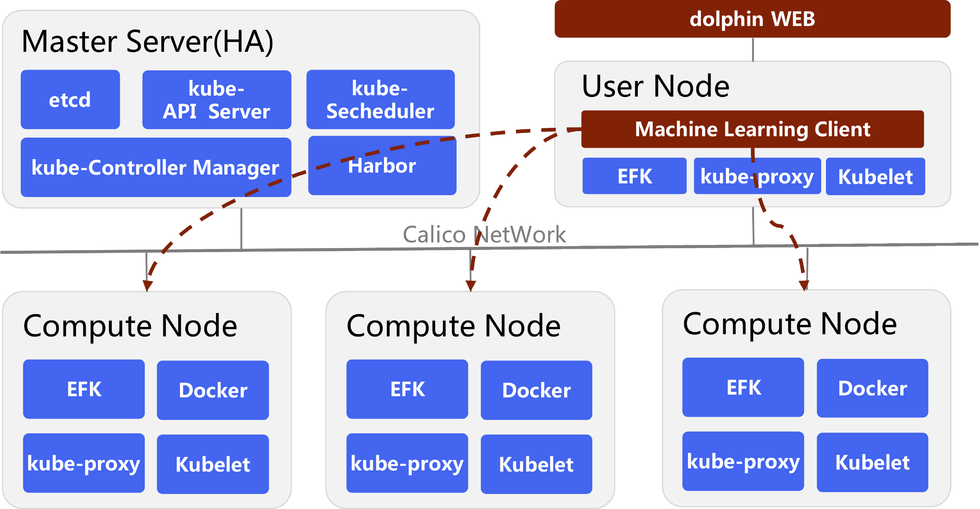
Dolphin 根据数据科学家选用的不同的机器学习算法框架,通过 Kubernetes 编排出相应的机器学习计算集群,如下图所示通过 dolphin 调度起来的 Tensorflow 计算集群,创建出 Parameter Server 和 Work 的 POD 以及 SVC,通过 HDFS Mount 模块将用户数据空间映射到 Docker Container 中,执行用户的算法脚本进行模型训练和服务发布。

本文已由作者刘勋授权网易云社区发布,原文链接:猛犸机器学习开发实践

 浙公网安备 33010602011771号
浙公网安备 33010602011771号