Impala源码之订阅发布系统的实现
本文由 网易云 发布。
作者:冯宇
本篇文章仅限内部分享,如需转载,请联系网易获取授权。
本文是Impala源码笔记的第一篇,本文主要根据源代码学习一下statestored模块的实现,众所周知,Impala包含三个模块,分别是impalad 、catalogd 和statestored, 其中statestored模块的作用是实现一个业务无关的订阅(Subscribe) 发布(Publish) 系统,catalod和impalad中的部分消息传递需要通过statestored传递,为什么要使用这样一个业务无关的服务来传递消息呢?下面我们来揭开它神秘的面纱。
低耦合
我们都知道,无论是系统架构设计还是代码框架设计,有一个原则叫做“高内聚,低耦合”,解耦就是为了降低系统之间的耦合性,减小不必要的依赖,使得系统具有更好的重用性,维护性,扩展性,可以更高效的完成系统的维护开发。举个例子,当在impala中创建一个新表,我们需要连接到一个impalad,然后执行CREATE TABLE操作,之后再将这个源数据更新通知catalogd, 通过catalogd通知所有的impalad更新缓存的元数据。一个高耦合的系统会将所有的impalad在启动的时候注册到catalogd,然后catalogd维护impalad的状态(是否存活,是否出现网络故障等),这使得catalogd在原有的业务服务基础上增加了很多额外的工作,大大提升了catalogd的实现难度和扩展性。
而通过statestored这样的订阅发布服务,catalogd作为一个发布者将新的动态发布到对应的topic上,每一个impalad节点作为一个订阅者订阅该topic,这样catalogd不必impalad的存在和状态,而impalad也不用关心catalogd在哪里启动,只需要从队列中获取元数据的更新,大大增加了系统的可扩展性,降低了catalogd的实现和运维复杂度。
Impala架构
好了,讲了这么多statestored的作用和好处,先祭出impala的整体架构,然后再讲述statestored是如何实现这样的一个订阅发布服务的,接着再看一下impala实现过程中使用statestored完成了什么具体的功能,最后以一个例子演示如何使用statestored提供的功能。
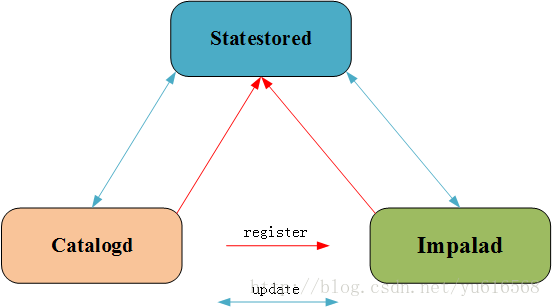
上图中可以看出,impalad和catalogd之间的消息传递是通过statestored的,而没有直接请求获取更新。
Statestored实现
说道订阅发布模式,按照之前的经验,例如上面的catalog更新的例子,通常会将catalogd作为发布者角色,然后impalad节点都是订阅者订阅该topic,这样还是需要catalogd维护所有的impalad信息,为了避免此类耦合,来看看statestored是如何实现的。
Statestored执行逻辑需要Subscriber首先调用register接口, 然后定期的向每一个Subscriber发送消息, 在impala 中它和Subscriber消息传递如下图:

impala整个系统结合使用C++和JAVA实现,但是statestored服务是全部使用C++实现的,这无疑增加了学习和调试的难度
(C++已两年没用了),impala中全部的通信操作都是使用thrift实现的,其中statestored对外只提供一个服务,参考源码中
(common/thrift/StatestoreService.thrift)的定义:
// Description of a topic to subscribe to as part of a RegisterSubscriber call struct TTopicRegistration {
// Human readable key for this topic
1: required string topic_name;
// True if updates to this topic from this subscriber should be removed upon the
// subscriber's failure or disconnection
2: required bool is_transient;
}
struct TRegisterSubscriberRequest {
1: required StatestoreServiceVersion protocol_version =
StatestoreServiceVersion.V1
// Unique, human-readable identifier for this subscriber
2: required string subscriber_id;
// Location of the StatestoreSubscriberService that this subscriber runs
3: required Types.TNetworkAddress subscriber_location;
// List of topics to subscribe to
4: required list<TTopicRegistration> topic_registrations;
}
struct TRegisterSubscriberResponse {
// Whether the call was executed correctly at the application level
1: required Status.TStatus status;
// Unique identifier for this registration. Changes with every call to
// RegisterSubscriber().
2: optional Types.TUniqueld registration_id;
}
service StatestoreService {
// Register a single subscriber. Note that after a subscriber is registered, no new
// topics may be added.
TRegisterSubscriberResponse RegisterSubscriber(1: TRegisterSubscriberRequest params);
}
从thrift接口的定义可以看到statestored服务只提供一个接口:RegisterSubscriber,该接口需要的参数包括subscriber_id(唯一标示客户端的信息),subscriber_location(客户端地址)和TTopicRegistration信息,一个客户端可以同时订阅多个topic。
RegisterSubscriber接口的实现存在于be/src/statestore/statestore.cc文件中,它主要执行如下逻辑:
- 1、查看该Subscriber订阅的所有topic是否存在,如果不存在则初始化该topic信息。
- 2、查找该Subscriber是否已经注册过(例如重新启动一个impalad),如果存在则将之前的注册解除,并且清理该Subscriber相关的内容。
- 3、将该Subscriber注册到监控对象中,监控对象保存该Subscriber状态,判断是否已经失去连接。
- 4、初始化新加入的Subscriber的信息,包括地址,关注的topic信息等。
- 5、初始化Heartbeat和UpdateState请求,发送到线程池。
第一次看上面的注册逻辑肯定是一脸懵逼,怎么和预想的完全不一样,而且又冒出这么多新名词是什么鬼,接下来就围绕着这个一一道来。
首先statestored虽然是一个订阅-发布系统,而statestored作为一个中心服务器并没有定义订阅者和发布者这两种角色,那么怎么区分这两种角色呢?这里先卖个关子,暂时现称他们为Subscriber吧,每一个Subscriber注册的时候需要携带关注的topic信息(可以同时关注多个topic)以及Subscriber的地址(包括IP和端口),为什么要传给statestored这些信息呢,当然是为了当topic上有新动态的时候通知Subscriber啦,既然是一个IP+port,这就意味着subscriber需要在这个端口上启动一个服务,这个服务提供接 口用于statestored通知topic的更新,thrift接口定义(common/thrift/StatestoreService.thrift)如下:
struct TUpdateStateRequest {
1: required StatestoreServiceVersion protocol_version = StatestoreServiceVersion.V1
2: required map<string, TTopicDelta> topic_deltas;
3: optional Types.TUniqueId registration_id;
}
struct TUpdateStateResponse {
1: required Status.TStatus status;
2: required list<TTopicDelta> topic_updates;
3: optional bool skipped;
}
struct THeartbeatRequest {
1: optional Types.TUniqueId registration_id;
}
struct THeartbeatResponse {
}
service StatestoreSubscriber {
TUpdateStateResponse UpdateState(1: TUpdateStateRequest params);
可以看到该服务实现了两个接口,UpdateState和Heartbeat,前者用于通知topic的更新,后者用于和Subscriber保持心跳连接, 但是一个Subscriber可能关注多个topic,不同的topic更新的时机是不一致的,如何做到同时通知一个Subscriber多个topic的更新呢?statestored并没有使用事件通知(topic更新)的方式,而是周期性的通知,因此statestored需要周期性的调用这两个接口。
周期性调度又是如何实现的呢,无非是通过构造两个线程池,分别用于处理heartbeat和updateState的逻辑,线程池接受的请求是的信息,deadline表示该请求发送的最后时间,根据subscriberId查找请求应该发往哪个Subscriber。具体实现发送heartbeat和updateState请求的逻辑(也就是线程池中每一个任务的处理逻辑)在Statestore::DoSubscriberUpdate函数中,该函数执行逻辑如下:
- 1、判断deadline是否为0,如果是0则意味着立即发送,例如刚注册的subscriber第一次请求的deadline等于0,否则sleep 一定的时间直到deadline(sleep时间差的时间).
- 2、根据subscriberId找到对应的Subscriber信息(也就是在register时候保存的信息),如果找不到则可以直接返回忽略该请求。
- 3、执行发送heartbeat或者updateState操作,并且设置下一次发送的deadline。
- 3.1 如果该请求是heartbeat请求,则构造心跳信息并发送,下次deadline时间等于当前时间加上间隔时间,心跳信息只是用于探活。
- 3.2 如果是updatestate请求,则首选需要构造本次发送的更新信息,这些信息可以根据Subscriber对象中关注的每一个topic最近一次更新的版本(已经发送成功的版本)和这些topic所有版本信息获得,如果是第一次发送则需要发送全部的topic信息,否则发送增量的信息。发送成功则设置最新更新的版本,否则下次重试,最后,它还需要根据updateState的返回值(response的topic_updates字段)将该subscriber更新信息应用到topic版本库里面。最后还有一些异常的处理。下次更新的时间的设置是根据返回值的is_skip字段判断,如果它为true则表示subscriber没时间处理该消息(意味着正忙),则间隔两个时间间隔,否则间隔一个时间间隔发送。
- 4、最后在每次发送请求之后检查subscriber状态,如果它的状态为FAILED(例如很久没有收到心跳了)则删除该subscriber,否则调度下一次执行(向线程池中放入一个新的deadline的请求)。
看到这里可能要问了,既然updateState请求和heartbeat请求都是定时发送的,那么为什么还需要heartbeat呢?前面说过heartbeat消息只是用于探活,而updateState是用来处理真正的消息发布,分工明确,而且这两个消息的调度频率也是不相同的。statestored对Subscriber的探活又是怎么做的呢?
在注册subscriber的时候有一个步骤是注册Subscriber到检测对象中,这个对象由FailureDetector定义,实现方式有两种:MissedHeartbeatFailureDetector和TimeoutFailureDetector,目前statestored使用的是前者,它是根据向Subscriber发送的heartbeat连续丢失(错误)个数判断该subscriber是否存活,后者是根据上次成功发送到Subscriber的heartbeat信息距离当前时间是否超时判断是否存活。
写到这里已经把statestored的主要逻辑和实现说明了一番,是不是觉得很简单?但是上面还有一个疑点没有说明,就是在这个订阅发布系统中,如果区分订阅者和发布者的呢?这个问题在发送updateState请求的逻辑中已经提到,每次执行updateState是发送该subscriber缺失的哪些版本的消息,该操作还有一个返回值,这个返回值会被应用到topic中。所以如果一个subscriber实现updateState的时候返回值包含更新的信息,那么这个subscriber既是一个发布者又是一个订阅者,而单纯的接受updateState的参数不返回任何更新信息的subscriber就仅仅是一个订阅者了。
Impala中的topic
在impala中,现在存在三个topic,可以通过statestored的web界面查看队列信息,当然开启statestored的web界面服务需要设置参数enable_webserver=true(默认值),端口通过webserver_port配置。可以看到impala中使用的三个topic分别是:
- impala-membership,这个topic用于传递当前存在的impalad进程,所有的impalad即使发布者又是订阅者,因为impalad 在执行查询的时候需要根据该信息确定可以将子任务分配给哪些impalad执行,当然该功能使用zookeeper注册临时节点的方式实现,但是impalad没有采用该方案。
- impala-request-queue,这个topic用于传递队列资源使用信息,impalad在执行查询之前需要预估查询耗费的资源,并且根据该请求发送的队列配额判断是否可以执行请求,使用该topic同步每一个队列的信息,毕竟队列的更新是每一个impalad 都需要涉及的(例如执行一个子任务需要消耗资源),因此每一个impalad即使发布者又是订阅者。
- catalog-update,这个topic用于同步系统元数据,catalogd是发布者,impalad是订阅者。
从上面的topic使用中可以逐渐明确一个问题:什么样的消息需要通过这种订阅发布的方式通信呢?我觉得是那些实时性要求没那么高并且涉及到系统中大部分节点的。例如一个创建表的请求需要impalad发送给catalogd,这样的操作就不能通过statestored通信,因为impalad需要同步的等待该请求执行完成才能返回给客户端,对时效性要求较高,则采用直接调用catalogd接口的方式。
使用Statestored开发新功能
上文讨论了statestored实现原理以及哪些场景适合使用statestored通信,那么我们就利用statestored的特性做一些有用的功能吧,这里我们作为实例的新功能是为了解决impalad查询信息分散的问题,使用过impala的同学都知道,SQL查询可以发送到任意一台impalad节点,这个impalad节点作为该查询的主控节点,而查询的执行情况和统计信息都可以在这个impalad的web界面上查看,方便监控和使用,但是如果不同的查询发送到不同的impalad,此时查询某一个SQL的执行情况就需要逐个的判断它所发送的impalad节点,再登录web页面查看,这就使得使用方式复杂了许多。
这里作为一个例子就是开发一个新功能,完成集中式的查询统计管理(假设名为SQLStatAdmin),设计流程如下:
- 1、每一个impalad启动的时候都注册一个新的topic,假设名为impala-queries。
- 2、当请求发送到任意一个impalad时,impalad将该查询的信息通过这个topic发送到statestored,为了避免发送大量的消息,发送的查询消息可以只包括查询id、impalad节点信息、用户信息等概要信息。
- 3、SQLStatAdmin系统启动的时候注册这个topic,仅仅作为订阅者获取不同impalad发送的查询信息。
- 4、SQLStatAdmin记录获取的SQL信息并持久化,然后再通过查询Id和该查询请求的impalad节点的地址获取详细的查询统计信息。
- 5、SQLStatAdmin提供查询界面查询整个impala集群的查询统计信息。
当然上面的说明只是一个比较粗略的设计,但是使用statestored实现该功能或者类似的功能无疑是最好的。
配置
Impala中三个节点都需要对statestored进行相关的配置主要涉及的配置如下:
|
配置 |
配置节点 |
说明 |
默认值 |
|
state_store_host |
impalad/catalogd |
statestored启动的机器hostname |
localhost |
|
state_store_port |
impalad/catalogd |
statestored启动的端口号 |
24000 |
|
state_store_subscriber_port |
impalad/catalogd |
本地subscriber服务监听端口 |
23000 |
|
use_statestore |
impalad |
是否使用statestored维护impalad节点关系 |
true |
|
statestore_num_update_threads |
statestored |
updateState线程池线程数 |
10 |
|
statestore_num_heartbeat_threads |
statestored |
heartbeat线程池线程数 |
10 |
|
statestore_update_frequency_ms |
statestored |
updateState更新频率(毫秒) |
2000 |
|
statestore_heartbeat_frequency_ms |
statestored |
heartbeat更新频率(毫秒) |
1000 |
|
statestore_max_missed_heartbeats |
statestored |
探活最多丢失的心跳个数 |
10 |
总结
本文详细介绍了impala中statestored模块的作用和实现原理,并且以一个实例的方式介绍如何使用statestored完成一些新的功能。虽然statestored可以实现解耦,提高系统的可扩展性,但是这样的设计还是存在一定的弊端:
- 同步消息不及时可能造成无法预知的错误,例如查询队列信息不及时可能使得某些队列超额使用;元数据更新不及时可能造成不同impalad节点元数据的不一致。这些需要根据具体的业务需求想办法解决。
- 单点瓶颈,statestored在impala中是单点存在的,虽然即使它宕机造成的影响不是特别大(因为所有的信息impalad和catalogd都有缓存,错误的时候也会校验),但是还是会影响系统的问题,因此还是需要一些方案处理该问题。
- 存在bug,在单发布者情况下,例如元数据同步topic,catalogd执行一个更新(例如删除一个表),但是在发送给statestored之前(下一次调用updateState之前)catalogd宕机了,导致这个更新没有同步到catalogd,而impalad一直根据版本执行元数据更新。等到catalogd重启之后,之前的未发送的更新记录已经全部丢失,因此删除表的操作不能同步到impalad中。
网易有数:企业级大数据可视化分析平台。面向业务人员的自助式敏捷分析平台,采用PPT模式的报告制作,更加易学易用,具备强大的探索分析功能,真正帮助用户洞察数据发现价值。可点击这里免费试用。
了解 网易云 :
网易云官网:https://www.163yun.com/
新用户大礼包:https://www.163yun.com/gift
网易云社区:https://sq.163yun.com/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号